
标识符与变量
标识符
标识符可以标志 :类名,方法名,接口名,常量名
命名规则 :
- 只能由字母,数字,下划线,$ 组成
- 不能以数字开头
- 关键字不能做标识符
- 标识符严格区分大小写
例如:
class HelloWorld{
}
class helloWorld{
}
这两个类是完全不同的类,但如果用javac编译这个文件 仅会生成一个HelloWorld文档(就是上面的那个),用IDE不会出现这种问题
命名规范 :
- 见名知意
- 大小写分隔单词
- 类名和接口名首字母大写
- 变量名和方法名首字母小写
- 常量名全部大写,单词间下划线衔接
变量
数据 被称为 字面量 ; 数据一定占有内存空间
字面量可分为 :
整数型字面量 1 2 3
浮点型字面量 1.3 1.2
布尔型字面量 true false
字符型字面量 ‘a’ ‘b’
字符串型字面量 “abc” “中国”
其中 字符型 和 字符串型 描述的是文字,字符使用单引号,字符串使用双引号
System.out.println(10);
System.out.println(10);
System.out.println(10);
这三个 10 占用不同的内存空间; 而:
int i = 10;
System.out.println(i);
System.out.println(i);
System.out.println(i);
这三次访问的是相同的内存空间,使得内存空间得到了复用
Java是一种强类型语言,每个变量都必须声明其类型;其要素包括变量名,变量类型,作用域
变量: 类型 名称 = 字面量
- 类型决定内存空间大小 列如int 4字节
- 名称方便访问
- 值是保存数据
- 命名参照规范
- 在Java中,未赋值的变量不可访问 相当于这块内存空间没有开辟(实际上 强类型语言中所有的变量必须先定义后使用)
变量的作用域(有效范围): 仅在大括号内有效
引例 :
String name = 张三;
/*报错信息: 找不到符号*/
类似于:
int b = 100;
int c = b;
/*把b中的内容赋值给c*/
报错的原因在于: JVM认为张三是一个标识符(类名,方法名,变量/常量 名,接口名)
变量的作用域
变量分为三种:
- 类变量
- 实例变量 从属于对象,具有默认值
- 局部变量
class Variable{
static int allClicks = 0; //类变量
String str = "hello world";//实例变量
public void doSome(){
int i = 0;//局部变量
}
}
public class B{
public static final int A = 10;
int i = 10;
public static void main(String[] args){
int i = 20;
System.out.println(i); //20
}
public static void test(String[] args){
int i = 30;
System.out.println(i);//30
}
}
以上三个i互不冲突,main中的i有效范围就在main里,test中的i就在test里
数据类型
数据类型用来声明变量,程序运行过程中依照不同的数据类型来分配不同大小的空间
基本数据类型
- 整数型 byte,short,int,long
- 浮点型 float,double
- 布尔型 boolean
- 字符型 char
| 类型 | 字节 | 个数 | 取值范围 | 默认值 |
|---|---|---|---|---|
| byte | 1 | 256个 | -128~127 | 0 |
| short | 2 | 65536个 | -32768~32767 | 0 |
| int | 4 | -2147483648~2147483647 | 0 | |
| long | 8 | -很大~ +很大 | 0l | |
| float | 4 | 范围可变 | 0.0f | |
| double | 8 | 范围可变 | 0.0 | |
| boolean | 1 | true/false | false | |
| char | 2 | 65536个 | 0-65535 | \u0000 |
short和char实际上容量相同,不过char可以表示更大的数字
字符型
字符类型char表示一个字符。Java的char类型表示一个Unicode字符(Unicode兼容ASCII)。
char可以存储1个汉字,汉字占用两字节,char也占用两字节,char采用UNICODE编码
字符类型char是基本数据类型,它是character的缩写。char 底层存的就是Unicode编码。
char c1 = 'A';
char c2 = '中';
因为Java在内存中总是使用Unicode表示字符,所以,一个英文字符和一个中文字符都用一个char类型表示,它们都占用两个字节。
要显示一个字符的Unicode编码,只需将char类型直接赋值给int类型即可:
int n1 = 'A'; // 字母“A”的Unicodde编码是65
int n2 = '中'; // 汉字“中”的Unicode编码是20013
char c = 'A';
int a = c;//65
以如下代码为例说明:
char ch = 'a';
int it = ch;
ch底层存储的就是 00000000 01100001
赋值给it得到的就是 00000000 00000000 00000000 01100001
在打印的时候将ch解码为 ‘a’,int类型打印就是97
赋值给int类型是因为byte、short装不下char类型的数据
char c = 'ab';
/*报错信息:未结束的字符文字*/
char d = "a";
/*报错信息:类型不兼容*/
未结束的字符文字: 编译器认为 ‘a 之后应该有一个 ‘ 但是出现了一个 b
还可以直接用转义字符\\u+Unicode编码来表示一个字符:
// 注意是十六进制:
char c3 = '\\u0041'; // 'A',因为十六进制0041 = 十进制65
char c4 = '\\u4e2d'; // '中',因为十六进制4e2d = 十进制20013
注意:
'a' + "abc"; //aabc 字符串拼接
'a' + 1 //97 转换为int
'a' + 1 + "abc" //98abc
char a = 'a';
sout(a + 1); //98
a = a + 1;
sout(a); //b
转义字符
\\"表示字符"\\'表示字符'\\\\表示字符\\\\n表示换行符\\r表示回车符\\t表示Tab 补齐到八个空格\\u####表示一个Unicode编码的字符
char s1 = '\t';
System.out.println("abc" + s1 + "def");
System.out.println("abc\\tdef");
char s2 = '\n';
System.out.println("abc" + s2 + "def");
假设要输出一个 \
System.out.println('\');
这样是行不通的,因为\将后面的单引号转义为一个字面量,编译器认为此处少了一个单引号,所以应该是
System.out.println('\\');
若想输出 “test”
System.out.println("\\"test\\"");
\ u 表示后面的内容是一个字符的Unicode编码,十六进制。
char x = '\\u4e2d';
System.out.println(x); //输出了一个 中
char x = '4e2d' ; //未结束的字符文字
UNICODE 编码
ASCII码采用1byte 存储
例如’a’ -> 97 ‘A’ -> 65 ; 而97 -> 0110 0001 , ‘a’变为0110 0001 的过程是编码 反过来是解码
国际标准组织制定了ISO-8859-1编码方式(latin-1),向上兼容ASCII,不支持中文
简体中文编码方式:GB2312 < GBK < GB18030 繁体中文编码方式:big5
Java为了支持全球文字采用UNICODE编码,包括UTG-8,UTF-16,UTF-32等
整数型
int
任何情况下,整数型字面量/数据被当作int类型处理,如果希望该类型被当作long类型,需要在后面加上 l/L
-
整数型字面量:八进制以0开头,十六进制以0x开头
-
小容量转大容量 : 自动类型转换
-
大容量转小容量 : 需要加强制类型转换符,并且可能有精度损失
int a = 100; //数据当作int类型处理,不存在类型转换
long b = 200; //数据当作int类型处理,小容量转大容量,自动类型转换
long c = 300L; //300L是一个long类型的字面量,不存在类型转换
long d = 2147483647; //int类型最大值,自动类型转换
long e = 2147483648; /*报错信息:整数太大*/
报错是因为整数被看作int,而这个字面量超过了int的存储范围,编译报错。
解决办法: 在最后加一个L
long x = 100L;
int y = x; /*报错信息:不兼容的类型*/
报错是因为 编译器检查到2行代码处只知道x是一个long类型的值,而不知道其中存储的数据究竟是多少,解决办法是:
int y = (int)x; //进行强制类型转换
在底层转换的过程中:
long类型的100L : 00000000 00000000 00000000 00000000 00000000 00000000 00000000 01100100
转换为int类型时,会强制性的把前面的四个字节去掉,变为00000000 00000000 00000000 01100100
JDK7新特性: 数字之间可以用下划线分割
int money = 10_0000_0000;
System.out.println(money)//下划线并不会被输出
byte
byte x = 127;
byte y = 1;
按上面的规则:整数型字面量被当作int处理,此处应该报错;但是java还有一条规则:
当整数型字面量没有超过byte/short/char的取值范围时,那么这个整数型字面量可以直接赋值
混合运算
三个重要结论:
- 当一个整数字面量赋值给char类型的变量时,会自动转换成char字符类型,最终的结果是一个字符
char s1 = 'a';
System.out.println(s1); //输出正常
char s2 = 97;
System.out.println(s2); //得到的也是a
char s3 = 65535;
System.out.println(s3); //得到了一个未知字符
char s4 = 65536; /*报错: 不兼容的类型*/
- byte、short、char混合运算时,会各自先转换成int类型再运算
char c1 = 'a';
byte b = 1;
char s1 = c1 + b;/*报错:不兼容的类型*/
char s2 = 98;
byte m = 10;
byte n = 10;
byte e = m + n; // 报错:不兼容的类型,byte与byte会先转换为int
第三行报错是因为 虽然整数字面量可以直接赋给char类型,但是上面的运算结果得到的是一个int类型,编译器无法检测到具体的值,只能检测到int类型被赋值给char类型
- 多种数据类型混合运算时,最终结果的类型是容量最大的数据类型(结论二除外)
long a = 10L;
char c = 'a';
short s = 100;
int i = 30;
System.out.println(a + c + s + i);//结果是237
int x = a + c + s + i; /*报错信息:不兼容的类型:从long转换到int可能会有损失*/
其他需要注意的问题:
int money = 10_0000_0000;
int year = 20;
int total1 = money * year; //-1474836480 计算的时候溢出了
//用long类型可以接收吗?
long total2 = money * year;//结果还是相同的,原因是整数型默认是int,在转换为long类型之前就出现问题了
//正确做法
long total = money * ((long)year);//在进行运算前就把其一转换成long类型
浮点型
类型提升:
如果参与运算的两个数其中一个是浮点型,那么整型可以自动提升到浮点型:
public class Main {
public static void main(String[] args) {
int n = 5;
double d = 1.2 + 24.0 / n; // 6.0
System.out.println(d);
}
}
需要特别注意,在一个复杂的四则运算中,两个整数的运算不会出现自动提升的情况。例如:
double d = 1.2 + 24 / 5; // 5.2
计算结果为5.2,原因是编译器计算24 / 5这个子表达式时,按两个整数进行运算,结果仍为整数4。
double
Java中规定任何一个浮点型数据都默认当作double类型处理,如果想让这个浮点型字面量被当作float类型来处理,需要在字面量最后加上F/f(1.0默认是double ,1.0f认为是float)
int i = 10.0/5; /*报错信息:不兼容的类型,从double转为int可能有损失*/
此处的运算满足上面的规则: 先将5转换为容量最大的数据类型double,再进行除法运算
float
float f = 3.14; /*报错信息:cannot convert from double to float*/
赋值给float类型变量:
- 最后加上f
- 强制类型转换
银行财务类问题
在银行或者财务问题中double的精度也是远远不够的,java提供了一种精度更高的类型:java.math.BigDecimal
float/double存在的问题:
float d1 = 212313131f;
float d2 = d1 + 1;
System.out.println(d1 == d2);//结果竟然是true 这就存在问题了
浮点数的误差:浮点数0.1在计算机中就无法精确表示,因为十进制的0.1换算成二进制是一个无限循环小数,很显然,无论使用float还是double,都只能存储一个0.1的近似值。但是,0.5这个浮点数又可以精确地表示。
因为浮点数常常无法精确表示,因此,浮点数运算会产生误差:
public class Main {
public static void main(String[] args) {
double x = 1.0 / 10;
double y = 1 - 9.0 / 10;
// 观察x和y是否相等:
System.out.println(x); //0.1
System.out.println(y); //0.09999999999999998
}
}
由于浮点数存在运算误差,所以比较两个浮点数是否相等常常会出现错误的结果。正确的比较方法是判断两个浮点数之差的绝对值是否小于一个很小的数:
// 比较x和y是否相等,先计算其差的绝对值:
double r = Math.abs(x - y);
// 再判断绝对值是否足够小:
if (r < 0.00001) {
// 可以认为相等
} else {
// 不相等
}
浮点数在内存的表示方法和整数比更加复杂。Java的浮点数完全遵循IEEE-754标准,这也是绝大多数计算机平台都支持的浮点数标准表示方法。
溢出
整数运算在除数为0时会报错,而浮点数运算在除数为0时,不会报错,但会返回几个特殊值:
NaN表示Not a NumberInfinity表示无穷大-Infinity表示负无穷大
例如:
double d1 = 0.0 / 0; // NaN
double d2 = 1.0 / 0; // Infinity
double d3 = -1.0 / 0; // -Infinity
这三种特殊值在实际运算中很少碰到,只需要了解即可。
强制类型转换
可以将浮点数强制转型为整数。在转型时,浮点数的小数部分会被丢掉。如果转型后超过了整型能表示的最大范围,将返回整型的最大值。例如:
int n1 = (int) 12.3; // 12
int n2 = (int) 12.7; // 12
int n2 = (int) -12.7; // -12
int n3 = (int) (12.7 + 0.5); // 13
int n4 = (int) 1.2e20; // 2147483647
如果要进行四舍五入,可以对浮点数加上0.5再强制转型:
public class Main {
public static void main(String[] args) {
double d = 2.6;
int n = (int) (d + 0.5);
System.out.println(n);
}
}
引用数据类型
类(String是类的一种),接口,数组等
引用类型保存的是对象的引用
- 实际上没有对象变量这样的东西存在,只有引用到对象的变量;
- 对象引用变量保存的是存取对象的方法;它并不是对象的容器,而是类似指向对象的指针
Dog myDog; 这一步是声明引用变量
new Dog(); 这是创建对象
Dog myDog = new Dog(); 连接对象和引用
String
String 表示字符串类型,属于引用数据类型;
Java中规定用 "" 括起来的都是String对象,例如:"abc" 就是一个String类型对象; 并且 “” 括起来的字符串是不可变的。
在JVM中,以 “” 括起来的字符串都是直接存储在 方法区 中的 字符串常量池 里,这是因为字符串在实际的开发中使用的太频繁了,这样做是为了提高执行效率。
在JDK7.0之后就把字符串常量池移动到堆内存当中了。
User user = new User(110,"张三");
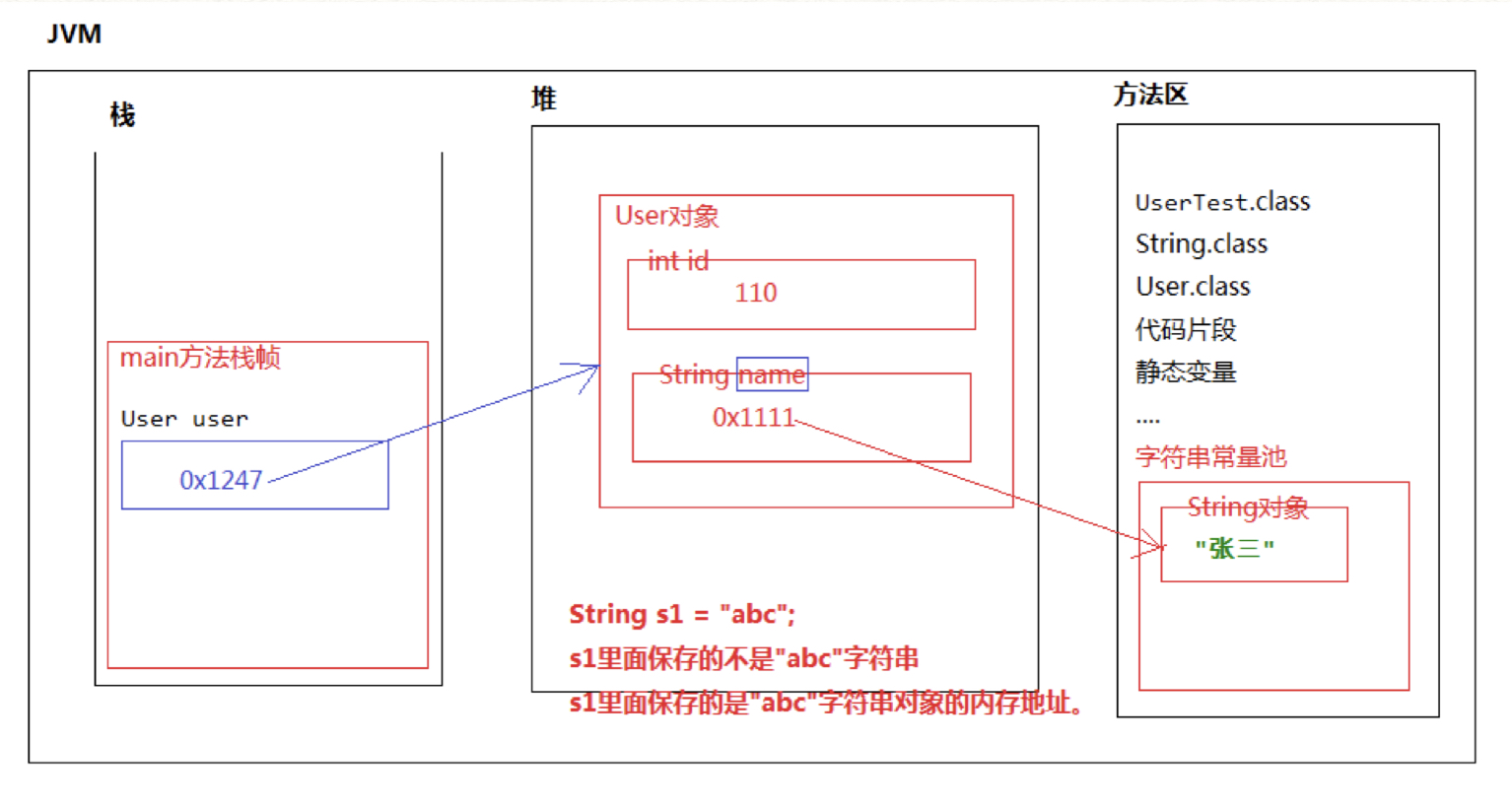
String s1 = "hello";
String s2 = "hello"; //这个hello不会新建字符串对象
System.out.println(s1 == s2);
第三行比较的就是变量中保存的内存地址 ,结果为true
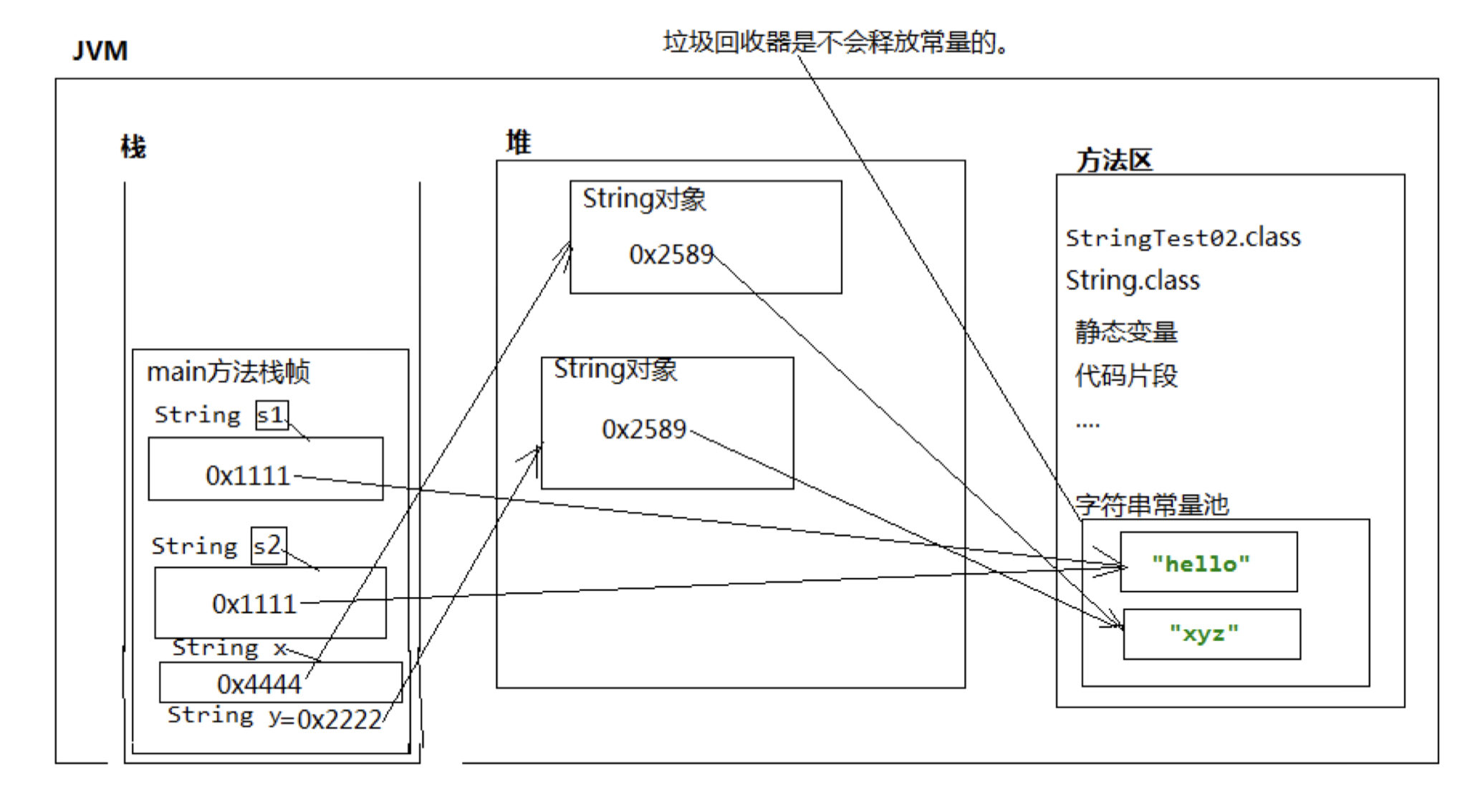
String x = new String("xyz");
String y = new String("xyz");
System.out.println(x == y);
System.out.println(x.equals(y));
```
第三行比较的是 x 和 y 中保存的 堆内存中的对象的内存地址,结果为false; 第四行调用了String类的equals方法,作用是比较两个字符串是否相等,所以结果为true
#### 多行字符串
如果我们要表示多行字符串,使用+号连接会非常不方便:
```java
String s = "first line \n"
+ "second line \n"
+ "end";
从Java 13开始,字符串可以用"""..."""表示多行字符串(Text Blocks)了。举个例子:
public class Main {
public static void main(String[] args) {
System.out.println("begin");
String s = """
SELECT * FROM
users
WHERE id > 100
ORDER BY name DESC
""";
System.out.println(s);
System.out.println("end");
}
}
/*
begin
SELECT * FROM
users
WHERE id > 100
ORDER BY name DESC
end
*/
上述多行字符串实际上是5行,在最后一个DESC后面还有一个\n。如果我们不想在字符串末尾加一个\n,就需要这么写:
String s = """
SELECT * FROM
users
WHERE id > 100
ORDER BY name DESC""";
还需要注意到,多行字符串前面共同的空格会被去掉,即:
String s = """
...........SELECT * FROM
........... users
...........WHERE id > 100
...........ORDER BY name DESC
...........""";
用.标注的空格都会被去掉。
如果多行字符串的排版不规则,那么,去掉的空格就会变成这样:
String s = """
......... SELECT * FROM
......... users
.........WHERE id > 100
......... ORDER BY name DESC
......... """;
即总是以最短的行首空格为基准。
不可变特性
Java的字符串除了是一个引用类型外,还有个重要特点,就是字符串不可变。考察以下代码:
public class Main {
public static void main(String[] args) {
String s = "hello";
System.out.println(s); // 显示 hello
s = "world";
System.out.println(s); // 显示 world
}
}
观察执行结果,难道字符串s变了吗?其实变的不是字符串,而是变量s的“指向”。
执行String s = "hello";时,JVM虚拟机先创建字符串"hello",然后,把字符串变量s指向它:
s
│
▼
┌───┬───────────┬───┐
│ │ "hello" │ │
└───┴───────────┴───┘
紧接着,执行s = "world";时,JVM虚拟机先创建字符串"world",然后,把字符串变量s指向它:
s ──────────────┐
│
▼
┌───┬───────────┬───┬───────────┬───┐
│ │ "hello" │ │ "world" │ │
└───┴───────────┴───┴───────────┴───┘
原来的字符串"hello"还在,只是我们无法通过变量s访问它而已。因此,字符串的不可变是指字符串内容不可变。至于变量,可以一会指向字符串"hello",一会指向字符串"world"。
理解了引用类型的“指向”后,试解释下面的代码输出:
public class Main {
public static void main(String[] args) {
String s = "hello";
String t = s;
s = "world";
System.out.println(t); // t是"hello"
}
}
运算符
算术运算符
算术运算符:+ – * / % ++ —
以++为例:
int m = 10;
int n = m++; //可以理解为先把m赋给n,再让m的值 + 1
int x = 10;
int y = ++x; //可以理解为 先进行自加1 再进行赋值
其实++运算使得变量立刻+1,只是i++取的是加之前的值,++i取的是加之后的值
引例: ^01
int i = 10;
i = i++;
System.out.println(i); //这时i的值还是10
因为Java在执行这种表达式的时候,会提前将i找一个临时变量存储,就等同于以下代码:
int i = 10;
int temp = i;
i++;
i = temp;
字节码指令
public class ReadClass01 {
public static void main(String[] args) {
int i = 10;
}
}
查看生成的class字节码指令:javap
javap -c ReadClass01.class
Compiled from "ReadClass01.java"
public class ReadClass01 {
public ReadClass01();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: bipush 10
2: istore_1
3: return
}
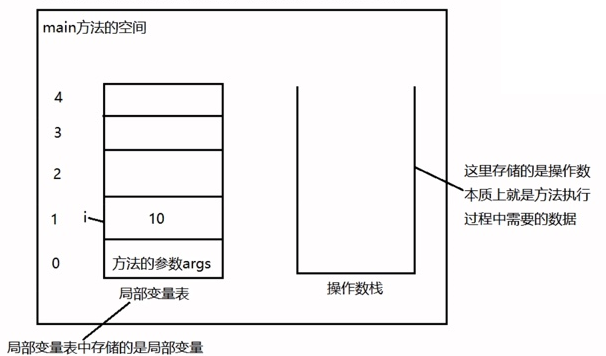
在Java程序执行的时候,会在JVM中为每个方法分配独立的空间,此时为main分配独立的空间
在独立的空间中有两块非常重要的空间:
-
操作数栈:存储操作数,操作数是任何一种类型的数据,这种数据存储在栈数据结构中
10存储在操作数栈中
-
局部变量表:存储局部变量
-
bipush: 将数据压入操作数栈中 -
istore_1: 将操作数栈顶数据弹出并存储到局部变量表第1个位置上(第0个位置存储main方法的参数) -
return:方法结束
iload 指令
public class ReadClass02 {
public static void main(String[] args) {
int i = 10;
int k = i;
}
}
Compiled from "ReadClass02.java"
public class ReadClass02 {
public ReadClass02();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: bipush 10
2: istore_1 //操作数栈顶的数据弹出存储在局部变量表第1个位置上 : i 10
3: iload_1 //将局部变量表中 1 位置的数据复制一份放在操作数栈顶
4: istore_2 //操作数表栈顶数据弹出并放入局部变量表2中的位置 :k
5: return
}
iinc 指令
public class ReadClass03 {
public static void main(String[] args) {
int i = 10;
i++;
}
}
Compiled from "ReadClass03.java"
public class read_class.ReadClass03 {
public read_class.ReadClass03();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: bipush 10
2: istore_1
3: iinc 1, 1 //局部变量表第1个位置上的数据加1
6: return
}
字节码分析
- 字节码解读一下代码的区别
/**
这一行代码有两步:
1. 将数据放入操作数栈
2. 操作数栈顶数据弹出赋值给变量
*/
int i = 10;
int k = i++;
int i = 10;
int k = ++i;
Compiled from "ReadClass03.java"
public class read_class.ReadClass03 {
public read_class.ReadClass03();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: bipush 10 //10 压入操作数栈顶
2: istore_1 //10 出栈 赋值给局部变量表 1 i = 10
//int k = i++;
//等号右边的数据要放入操作数栈
3: iload_1 //局部变量表1位置上的数据复制一份放入操作数栈顶
4: iinc 1, 1 //局部变量表1位置的数据自增1 i = 11
7: istore_2 //栈顶10出栈,赋值给局部变量表 2 k = 10
8: return
}
Compiled from "ReadClass03.java"
public class read_class.ReadClass03 {
public read_class.ReadClass03();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: bipush 10
2: istore_1
3: iinc 1, 1
6: iload_1
7: istore_2
8: return
}
区别在于:k = i++是先将i的值放入操作数栈顶,再自增1,最后将操作数栈顶的元素放入k中;而k = ++i是先自增1,再将结果存入操作数栈顶并赋值给k
字节码分析上面的[[002-Java程序基础#^01|引例]]:
int i = 10;
i = i++;
System.out.println(i); //i的值是10
int j = 10;
j = ++j;
System.out.println(j); //j的值是11
public static void main(java.lang.String[]);
Code:
0: bipush 10
2: istore_1
//将局部变量表1位置的i值复制一份放入操作数栈顶
3: iload_1
4: iinc 1, 1 //i自增1
7: istore_1 //操作数栈顶元素出栈赋值给i,i还是10
8: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
11: iload_1
12: invokevirtual #13 // Method java/io/PrintStream.println:(I)V
15: bipush 10
17: istore_2
18: iinc 2, 1
21: iload_2
22: istore_2
23: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
26: iload_2
27: invokevirtual #13 // Method java/io/PrintStream.println:(I)V
30: return
}
关系运算符
> >= < <= == !=
所有关系运算符的结果都是布尔类型
逻辑运算符
& | ! && ||
逻辑运算符的两边都是布尔类型,并且结果也是布尔类型
- & 只有两边的结果都是true的时候,结果才是true; 并且如果左边是false的话右边表达式还是会继续执行
- && 如果左边表达式的结果是false 的话,右边的表达式就不会执行
- || 同理。
int x = 10, y = 11;
System.out.println(x > y & x > y++);//左边的结果已经是false了,但是右边的表达式还会执行
System.out.println(y);//结果是12
int m = 10, n = 11;
System.out.println(m > n & m > n++);//左边的结果是false了,右边的表达式就不会执行了
System.out.println(n);//结果是11
扩展赋值运算符
+= -= *= /= %=
- 扩展运算符永远不会改变运算结果的类型
x += 1;
x = (byte)(x + 1);
这两条语句实际上是等价的,扩展赋值运算符会自动进行强制类型转换
引例:
byte x = 100;
x = x + 1; /*报错信息:不兼容的类型,从int类型转换为byte类型可能有精度损失
1被认为是int类型的(在 数据类型 一节有详细说明)*/
x += 1; //这样做就没有任何问题,自动进行强制类型转换,这也证明了上述结论
x += 199; //这已经超过了byte类型的取值范围,但是还不会报错;强制类型转换会自动损失精度
条件运算符
布尔表达式 ? 表达式1 : 表达式2;
布尔表达式为true时,选择第一个表达式执行;为false时选择第二个表达式执行
boolean sex = true;
char c = sex ? '男' : '女' ;//最终的结果时字符类型,就需要用字符型变量进行接收
字符串连接运算符
+在Java中有两个作用:
- +两边都是数字类型时,进行求和
- 任意一边是字符串类型时,进行字符串拼接,得到的结果还是字符串
在一个表达式中有多个 + 时,按照自左向右的顺序进行执行
System.out.println(a + b + "110");
先计算a + b ,得到300 + “110”再进行字符串拼接,结果是300110
流程控制
if
例:接收一个年龄 [0-150] 合法
package IF;
import java.util.Scanner;
public class IfTest01 {
public static void main(String[] args) {
String str = "老年";
Scanner sc = new Scanner(System.in);
int a = sc.nextInt();
if(a > 150 || a < 0){
System.out.println("Error");
}
else{
if(a <= 5){
str = "幼儿";
}
else if(a <= 10){
str = "少儿";
}
}
System.out.println(str);
}
}
注意:1. 通过设置变量str来保证代码唯一出口
2.进行小于判断要从小到大, 进行大于判断要从大到小
- if后()中若是赋值语句,最终的结果是变量的值
boolean sex = true;
if(sex = true){} // 此处先将true赋值给sex,()的结果就是sex的结果
/*说明此处永远是true*/
int i = 100;
if(i = 100){} //报错:不兼容的类型,从int转换为boolean会有损失
switch
switch(值){
case num1 : doSome; break;
case num2 : doSome; break;
case num3 : doSome; break;
}
支持的值: 本质上是支持 int 和 String 类型的; 但是byte、short、char和int类型是自动类型转换,也可以用在()当中
JDK12新特性
int number = 1;
switch (number) {
case 1 -> System.out.println("one");
case 2 -> System.out.println("two");
case 3 -> System.out.println("three");
default -> System.out.println("null");
}
break 可以省略
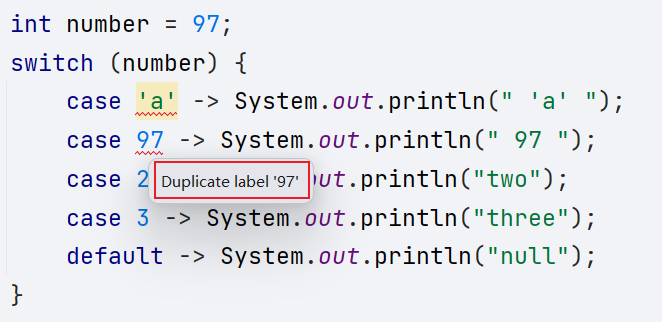
switch中的值只能是常量,不能是变量。编译阶段并不知道变量中存储的具体的值
JDK5支持枚举,JDK7支持String
for
执行流程:
- 变量初始化
- 循环判断条件
- 循环体语句
- 更新语句
- 循环判断条件
- 循环体语句
- 更新语句
for (int i = 0; i < 10; i++) {
//i是局部变量,for循环结束,i的内存空间就被释放了
}
对于嵌套的for:
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 10; j++) {
/*这两次循环的j是两个完全不同的内存空间
* 第一次循环结束后j就被释放了,对于第二次i = 1的循环来说又开辟了一个内存j
* 所以两次的j是不同的
* */
}
}
增强for循环:
public class ForEachTest01 {
public static void main(String[] args) {
int[] arr = {1,33,66,5,2,6,98,56,5};
for(int data : arr){
System.out.println(data);
}
}
}
增强for: for(元素类型 变量名 : 数组或集合)
这样写是没有下标的
for循环的双面性
我们为什么要用for遍历?
咋一听,好像有点莫名其妙。不用for循环,我怎么遍历啊?
其实无论何时,使用for都意味着我们潜意识里已经把数据泛化,牺牲数据的特性转而谋求统一的操作方式。想象一下,假设一个数组存了国家男子田径队的队员们,比如110米栏的刘翔、100米项目的苏炳添和谢震业。你如果写一个for循环:
for(sportsMan : sportsMen){
sportsMan.kualan();
}
在循环中,你只能调用运动员身上的一项技能执行。
- 你选跨栏吧,苏炳添和谢震业不会啊…
- 你选100米短跑吧,刘翔肯定比不过专业短跑运动员啊…
所以,绝大多数情况下,for循环意味着抽取共同特性,忽略个体差异。好处是代码通用,坏处是无法发挥个体优势,最终影响效率。
break
作用:1.用在switch-case中防止case穿透
2.用在循环体语句中终止循环执行
- break 不会让方法结束,只会终止离他最近的循环
- 若要终止指定的循环,需要给循环起一个名字
//终止外层循环
a: for (int k = 0; k < 2; k++) {
b: for (int i = 0; i < 10; i++){
System.out.println(i);
if(i == 5){
break a;
}
}
}
continue
continue作用:终止当前本次循环,直接跳入下一次循环继续执行
for(初始化表达式; 条件表达式; 更新表达式){
if(布尔表达式){
continue; // 当这个continue语句执行时,下面的代码都不执行,直接跳到更新表达式进行下一轮循环
}
code1;
code2;
code3;
}
continue到指定循环:
a: for(初始化表达式1; 条件表达式1; 更新表达式1){
b:for(初始化表达式2;条件表达式2;更新表达式2){
if(布尔表达式){
continue a; //直接跳到更新表达式1,更新表达式2就不执行了
//continue b; 跳到更新表达式2
}
}
}
while
while(布尔表达式){
[循环体语句]
}
do{
[循环体语句]
}while(布尔表达式);

