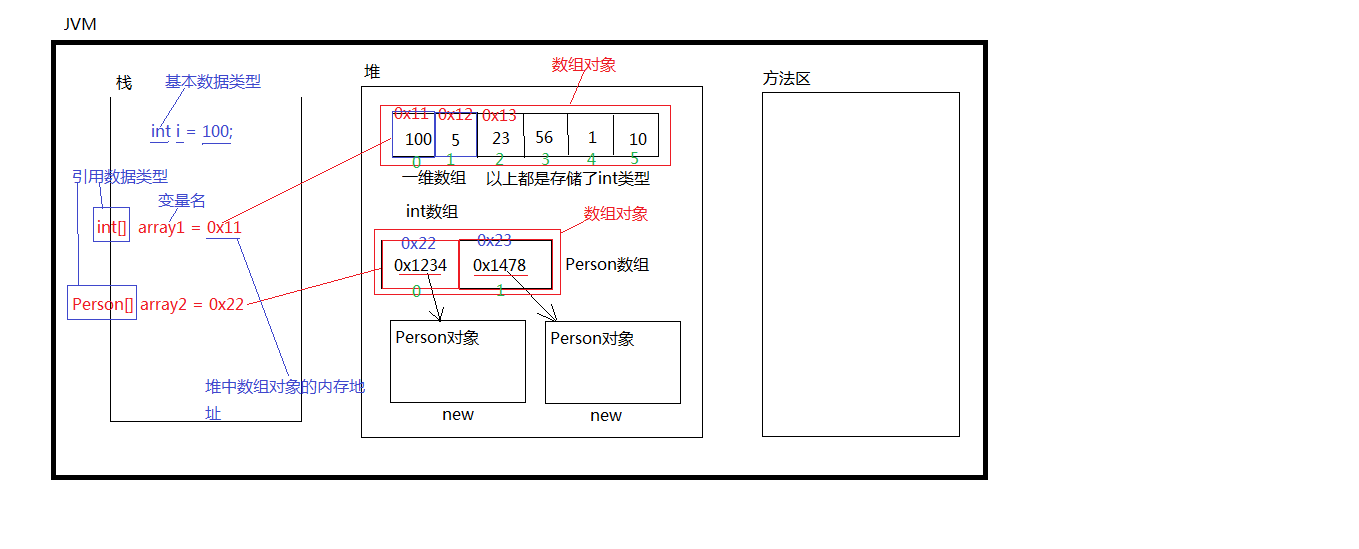
数组
- 数组是一种引用数据类型,所以数组对象实际上存储在堆内存当中
- 数组实际上是一种容器,可以容纳多个元素
- 数组中存储的是基本数据类型的数据,或者是引用数据类型的引用(不能直接存储Java对象)
- 长度不可变,起始位置是0,最后一个下标是length – 1
- 所有的数组对象都有length属性
- Java中数组元素类型统一,比如int类型数组只能存储int类型数据
- 数组的内存地址在逻辑上是连续的
- Person[] 数组是引用数据类型数组,存储的就是引用数据类型
优点:
- 数组是查询效率最高的数据结构
- 每一个元素的内存地址在空间存储上是连续的,每一个元素类型相同,占用的空间大小相同
- 通过第一个元素的内存地址,并且知道每一个元素占用的空间大小,通过数学计算就可得出某个下标上元素的内存地址,直接通过内存地址定位元素,所以检索效率最高。索引操作数组原理:首地址 + 索引值 * 每个元素占用字节数。
- 数组中不管存储多少个元素检索效率都是相同的,因为查找的时候不是一个一个找,是通过内存地址直接定位的
缺点:
- 为了保证内存地址连续,在数组上随机删除或者增加元素的时候效率会很低,因为随机增删元素会涉及到后面元素向前或者向后位移的操作
- 数组不能存储大数据量(很难在内存空间上找到一块特别大的连续内存空间)
初始化一维数组
- 静态初始化:确定数组中存储哪些元素时
int[] array = {100,200,300,400};
Object[] obj = {new Object(),new Object(),new Object()};
- 动态初始化:不确定数组中存储哪些元素时 预先分配存储空间
int[] array = new int[5];
初始化一个3长度的int数组,每个元素默认值是0
public class ArrayTest01 {
public static void main(String[] args) {
int[] array1 = {100,200,300};
int[] array2 = new int[3];
System.out.println(array1.length);
System.out.println(array1[0]);
System.out.println(array1[array1.length - 1]);
}
}
一维数组遍历:
从头到尾:
//array2.fori
for (int i = 0; i < array2.length; i++) {
System.out.println("array2" + "[" + i + "] : " + array2[i]);
}
从尾到头:
//array2.forr
for (int i = array2.length - 1; i >= 0; i--) {
System.out.println("array2" + "[" + i + "] : " + array2[i]);
}
如果访问到array2[array2.length]就会报错:ArrayIndexOutOfBoundsException 数组下标越界异常
foreach遍历:
for(int data : array2){
System.out.println(data);
}
方法的形式参数列表指定为一维数组,例如:
public static void printArray(int[] array){
for (int data:
array) {
System.out.println(data);
}
}
public static void printArray(String[] array){
for (String data:
array) {
System.out.println(data);
}
}
以上两个printArray方法形成方法重载,
public static void main(String[] args) {
int[] a = new int[5];
for (int i = 0; i < a.length; i++) {
a[i] = i;
}
String[] strings = {"haha","hehe","hoho"};
printArray(a);
printArray(strings);
-
在传递参数的时候直接把引用传递进去就可以了
-
此处可以用new创建一个数组对象传递进去:
printArray(new int[]{1,2,3,4});
但是在此处不能直接传递数组:printArray({1,2,3});
main方法的参数
JVM调用main方法,main方法需要一个args参数,调用的时候会自动传一个String数组进来
public static void main(String[] args) {
System.out.println(args.length);
}
控制台会输出一个0,说明args不是空引用。(如果是空引用此处会发生空指针异常)
这就像创建一个长度为0的数组:
String[] str1 = new String[0];
String[] str2 = {};
args数组其实是留给用户的,用户可以在控制台上输入参数,这个参数会自动转化为String[] args
例如用以下方式运行程序:
java 类名 abc def xyz
这个时候JVM会自动将abc def xyz 按照空格的方式进行分离,分离完成后自动放到String[] args数组当中,此时length是3
引用类型数组
对于Object数组来说,可以存储MyDate、String、Animal这些对象,这些对象的内存大小是不同的,而数组中从存储的只是各个引用,数组中的每个元素占用大小是相同的
如果要调用父类中存在的方法:
Animal[] animals = {new Cat(),new Bird() {
@Override
public void move() {
System.out.println("Bird flying");
}
}};
//对Animal数组遍历:
for (int i = 0; i < animals.length; i++) {
animals[i].move();
}
animals[i]取出的是Animal类型的对象地址,再用.调用就是引用调方法,不是数组调方法
如果要调用子类中特有的方法:
for (int i = 0; i < animals.length; i++) {
if (animals[i] instanceof Cat){
((Cat)animals[i]).catchMouse();
} else if (animals[i] instanceof Bird) {
((Bird)animals[i]).sing();
}
}
练习
反转数组
public static void main(String[] args) {
int[] nums = {5, 12, 90, 18, 77, 76, 45, 28, 59, 72};
reverseArr(nums);
System.out.println(Arrays.toString(nums));
}
public static void reverseArr(int[] arr){
for (int i = 0; i < arr.length / 2; i++) {
arr[arr.length - 1 - i] = arr[i] ^ arr[arr.length - 1 - i];
arr[i] = arr[i] ^ arr[arr.length - 1 - i];
arr[arr.length - 1 - i] = arr[i] ^ arr[arr.length - 1 - i];
}
}
删除指定索引的元素
根据索引删除元素的效率非常低,涉及到后续元素的位移
需求:删除数组{5, 1, 3, 6, 2, 4}索引为2的元素,删除后为:{5, 1, 6, 2, 4, 0}。
/**
* 根据索引删除数组中的元素
* @param arr 需要删除元素的数组
* @param index 需要删除数组元素的索引
*/
public static void deleteElement(int[] arr, int index) {
// 第一步:判断索引是否合法
if(index < 0 || index >= arr.length) {
System.out.println("索引越界");
return; // 索引不合法,直接结束方法
}
// 第二步:从index个元素开始,将后一个元素向前移动一位
for(int i = index; i < arr.length - 1; i++) {
// 将后一个元素向前移动一位
arr[i] = arr[i + 1];
}
// 第三步:将最后一个元素设置为默认值
arr[arr.length - 1] = 0;
}
删除指定位置的元素
结论:根据索引插入元素的效率非常低,因为需要大量挪动数组元素+可能做扩容操作。
public static int[] insertElement(int[] arr,int index,int element){
int[] newArr = new int[arr.length + 1];
for (int i = 0; i < arr.length; i++) {
if (index == i){
newArr[i] = element;
}
newArr[i < index ? i : i + 1] = arr[i];
}
return newArr;
}
找最大值
public static int getMax(int[] arr){
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
int score = arr[i];
if (score > max){
max = score;
}
}
return max;
}
注意:应该以数组中的元素作为最大/最小值
数组的拷贝与扩容
Java中数组长度一旦确定就不可变,数组满了需要数组扩容
Java中对数组的扩容是:新建一个大容量的数组,然后将小容量的数组中的数据一个一个拷贝到大容量的数组中
数组扩容效率较低,尽可能少用数组扩容
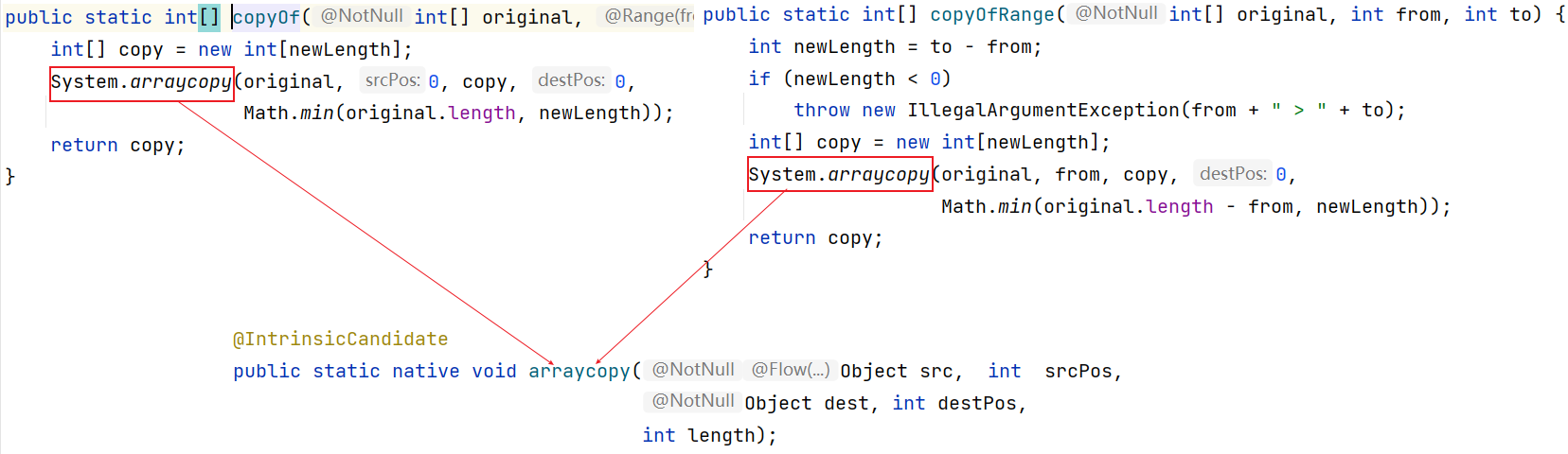
public static native void arraycopy(Object[] src, int srcPos,
Object[] dest, int destPos,
int length);
- src: 源数组
- srcPos:源数组中的起始位置
- dest:目标数组
- destPos:目标数组的起始位置
- length:拷贝长度
测试:
public static void main(String[] args) {
int[] src = {1,11,22,3,4};
int[] dest = new int[10];
System.arraycopy(src,0,dest,0,src.length);
for (int i = 0; i < dest.length; i++) {
System.out.println(dest[i]);
}
}
数组中存储的是引用也可以进行拷贝:
String[] str = {"hello","world","java","oracle"};
String[] newStr = new String[20];
System.arraycopy(str,0,newStr,0,str.length);
for (int i = 0; i < newStr.length; i++){
System.out.println(newStr[i]);
}
此处拷贝的是对象的地址。
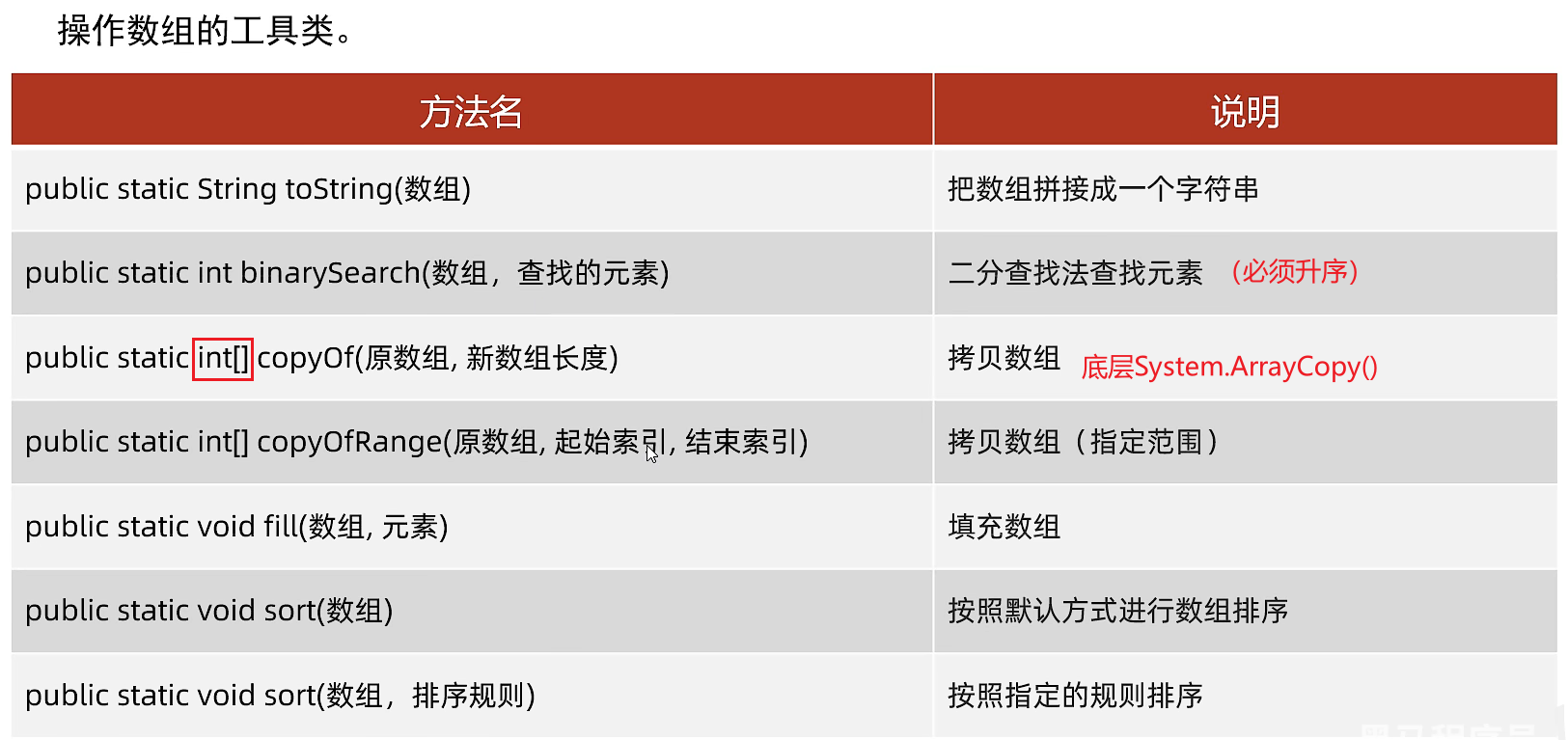
数组API
JDK类库中已经提供了相关的工具类:java.util.Arrays
Arrays.toString()

该方法在开始就计算a.length – 1,也就是数组下标的最大值,避免了每次执行循环判断语句
该方法会返回一个字符串对象
- 对于基本数据类型来说:
int[] a = {1,2,3,4,5};
System.out.println(Arrays.toString(a));//[1, 2, 3, 4, 5]
- 对于引用数据类型来说:
MyDate[] myDates = new MyDate[]{new MyDate(1, 1, 1), new MyDate(2, 2, 2), new MyDate(3, 3, 3)};
System.out.println(Arrays.toString(myDates));
这时的输出结果是:[1 – 1 – 1, 2 – 2 – 2, 3 – 3 – 3];因为在MyDate类中重写了toString方法
public String toString() {
return this.year + " - " + this.month + " - " + this.day;
}
也就是说引用数据类型作为参数时会自动调用该引用的toString方法
Arrays.sort
自然排序
默认情况下:给基本数据类型进行升序排列
int[] arr = {9,2,6,5,3,1,4,8,7};
Arrays.sort(arr);
for(int data : arr){
System.out.print(data + " ");
}
也可以指定某一段进行排序:
int[] arr = {9,2,6,5,3,1,4,8,7};
Arrays.sort(arr,0,5);//对下标从0 - 5的元素排序
for(int data : arr){
System.out.print(data + " ");
}
引用数据类型:
- String类型:
String[] strings = {"A","E","B","C","a","b"}; //A 65 a 97
Arrays.sort(strings);
System.out.println(Arrays.toString(strings));
按照unicode编码对结果进行升序排列,输出结果是: [A, B, C, E, a, b]
定制排序
- 其他类型,或者要降序排列只能使用重载的sort方法:
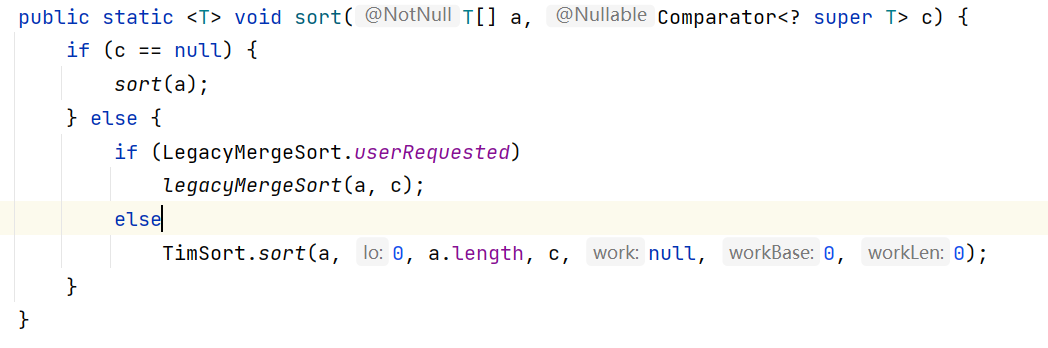
重载的sort方法只能给引用数据类型进行排序,如果数组是基本数据类型,就要转变为对应的包装类
参数中的Comparator接口:

第二个参数是一个接口,所以在调用方法的时候,需要传递这个接口的实现类对象,作为排序的规则;但是这个实现类只需要使用一次,所以没有必要单独写一个类,可以采用匿名内部类的形式:
/**
* public static void sort(数组,排序规则)
*
* 参数一:要排序的数组
* 参数二:排序的规则
*
*/
Integer[] arr = {2,3,1,5,6,7,8,9};
Arrays.sort(arr, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return 0;
}
});
单独定义比较器类(不推荐):
public class UserComparator implements Comparator<User> {//注意此处实现的接口
@Override
public int compare(User o1, User o2) {
return o1.age - o2.age;
}
}
Comparator接口限制的类型是 super T ,后文会说明原因。
数组排序的底层原理:插入排序 + 二分查找
默认将0索引当作有序序列,1索引到最后认为是无序的序列;遍历无序的序列得到里面每一个元素。假设当前遍历得到的元素是A元素,把A向有序序列中插入,在插入的时候是利用二分查找获得InsertPoint,用A元素与插入点的元素进行比较,比较的规则就是compare方法的方法体
compare方法的参数:
- o1是无序序列中遍历得到的元素
- o2是有序序列的元素
返回值是int类型:
- $ < 0 $ :当前要插入的元素是小的,要放在前面
- $ > 0 $ :当前要插入的元素是大的,要放在后面
- $ = 0 $:当前要插入的元素跟现在的元素比是一样的,也会放在后面
如果要升序排列就是用 待插入元素(无序序列元素)- 插入点元素,如果要倒序排列就相反
Integer[] arr = {2,3,1,5,6,7,8,9};
Arrays.sort(arr, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("o1 = " + o1);
System.out.println("o2 = " + o2);
System.out.println("=========================");
return o1 - o2;
}
});
System.out.println("arr = " + Arrays.toString(arr));
对于double类型的数据,不能直接做差强转int,也不能使用Math.floor/Math.ceil,只能使用Double.compare
如果没有传入比较器Comparator 或者 比较器Comparator为空,在sort方法中会进入重载的sort方法:

在排序前还会进行一次判断
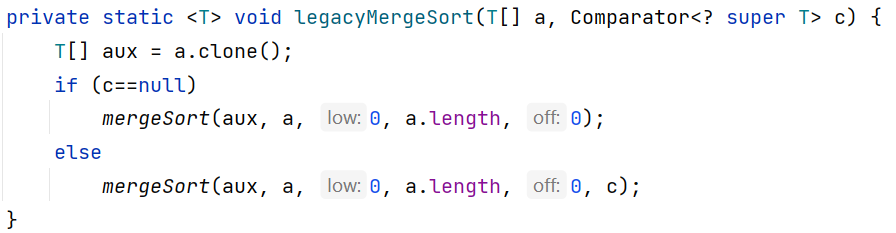
if成立(比较器为空):
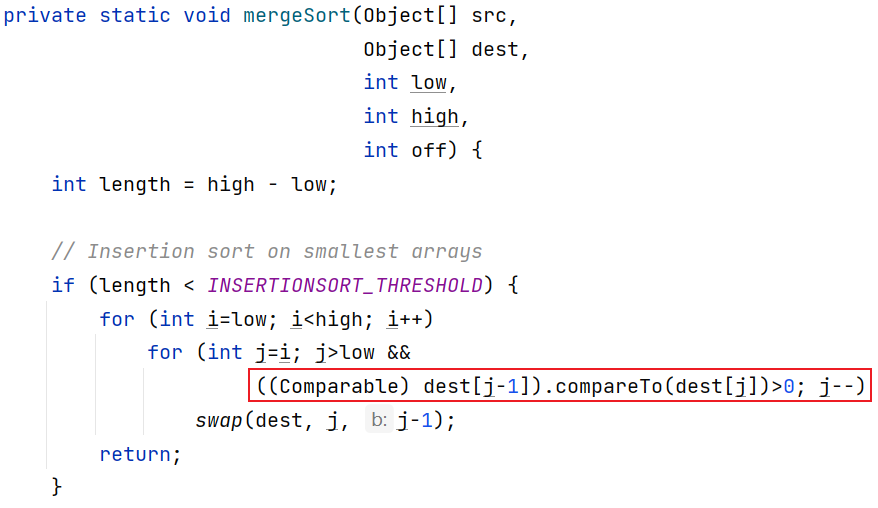
将数组中的元素转换为Comparable类型,并调用compareTo方法
如果该类型没有实现Comparable接口,在转型的时候JVM发现该类型并不是Comparable的实现类,抛出ClassCastException
实现Comparable接口:重写接口中的compareTo方法,在该方法中指定比较规则:
a.compareTo(b) == 0 a == b
a.compareTo(b) > 0 a > b
a.compareTo(b) < 0 a < b
class User implements Comparable<User>{
int age;
public User(int age) {
this.age = age;
}
public int compareTo(User o) {
return this.age - o.age;//指定排序规则
}
public String toString() {
return String.valueOf(this.age);
//在main中输出的时候会自动调用该引用的toString方法,需要重写
}
}
this指代的当前元素就是无序序列中的元素
测试:
User u1 = new User(10);
User u2 = new User(20);
User u3 = new User(30);
User[] users = {u1,u2,u3};
Arrays.sort(users);
for(User data : users){
System.out.print(data + " ");//自动调用toString
}
if不成立(传入了比较器):
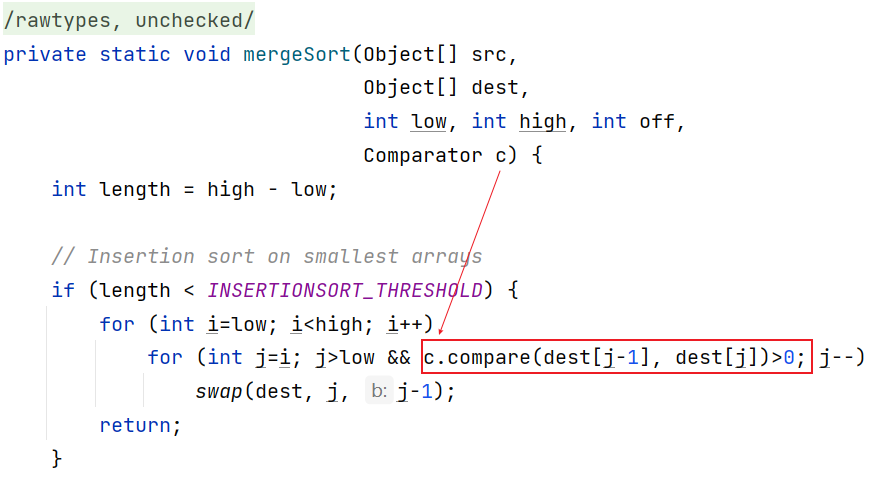
直接使用比较器调用comparTo方法对两个类型进行比较,这也是限制比较器泛型类型只能是 super T 的原因
小数类型的比较
对价格进行排序,不能直接转为int:
compare(Orange o1,Orange o2){
return (int)(o1.getPrice() - o2.getPrice());
}
这样在10.1 – 10.0时自动的变为0,就错误的认为这两个Orange是相等的
正确的实现方式:
compare(Orange o1,Orange o2){
if(o1.getPrice() > o2.getPrice()){
return 1;
}else if(o1.getPrice() < o2.getPrice()){
return -1;
}else{
return 0;
}
}
这样太繁琐了,Double类型为我们提供了这个方法:
//Since : 1.4
public static int compare(double d1, double d2) {
if (d1 < d2)
return -1; // Neither val is NaN, thisVal is smaller
if (d1 > d2)
return 1; // Neither val is NaN, thisVal is larger
// Cannot use doubleToRawLongBits because of possibility of NaNs. long thisBits = Double.doubleToLongBits(d1);
long anotherBits = Double.doubleToLongBits(d2);
return (thisBits == anotherBits ? 0 : // Values are equal
(thisBits < anotherBits ? -1 : // (-0.0, 0.0) or (!NaN, NaN)
1)); // (0.0, -0.0) or (NaN, !NaN)
}
可以直接调用:
compare((o1,o2) -> Double.compare(o1,o2));
排序底层实现
- JDK7 – JDK13
| 排序目标 | 条件 | 采用算法 |
|---|---|---|
int[] long[] float[] double[] |
size < 47 | 混合插入排序(pair) |
| size < 286 | 双基准点快排 | |
| 有序度低 | 双基准点快排 | |
| 有序度高 | 归并排序 | |
byte[] |
size <= 29 | 插入排序 |
| size > 29 | 计数排序(范围小) | |
char[] short[] |
size < 47 | 插入排序 |
| size < 286 | 双基准点快排 | |
| 有序度低 | 双基准点快排 | |
| 有序度高 | 归并排序 | |
| size > 3200 | 计数排序 | |
Object [] |
-Djava.util.Arrays.useLegacyMergeSort = true | 传统并归排序 |
| TimSort |
- JDK14 – JDK20
| 排序目标 | 条件 | 采用算法 |
|---|---|---|
int[] long[] float[] double[] |
size < 44并位于最左侧 | 插入排序 |
| size <65 并不是最左侧 | 混合插入排序(pin) | |
| 有序度低 | 双基准点快排 | |
| 递归次数超过384 | 堆排序(快排低效) | |
| 对于整个数组或非最左侧 size > 4096,有序度高 | 归并排序 | |
byte[] |
size <= 64 | 插入排序 |
| size > 64 | 计数排序(范围小) | |
char[] short[] |
size < 44 | 插入排序 |
| 再大 | 双基准点快排 | |
| 有序度低 | 双基准点快排 | |
| 递归次数超过384 | 计数排序 | |
| size > 1750 | 计数排序 | |
Object [] |
-Djava.util.Arrays.useLegacyMergeSort = true | 传统并归排序 |
| TimSort |
针对Object数组:优先选择稳定排序算法 TimSort
针对基本类型数组:
- 数据量小:插入排序
- 数据量大:
- 有序度高:并归排序
- 有序度低:快排
- 范围小:计数排序
Arrays.binarySearch
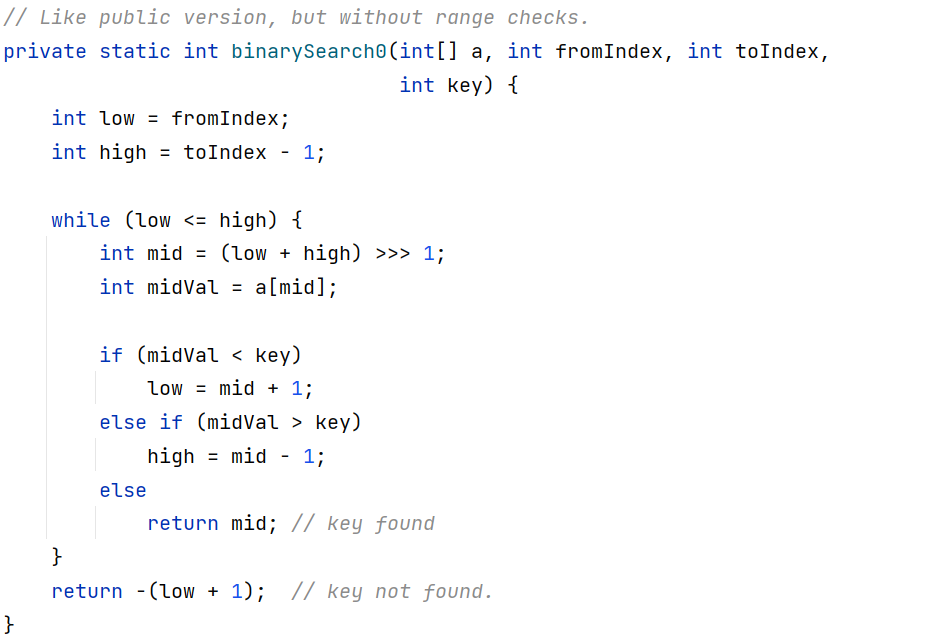
public static int binarySearch(int[] a, int key) {
return binarySearch0(a, 0, a.length, key);
}
二分查找,第一个参数int[] a表示在a数组中查找,第二个参数int key表示查找的目标元素,返回值时key在a数组中的下标。如果返回负数表示该元素的插入点,即该元素在a中不存在
使用二分查找的前提:数组已经排序
public static void main(String[] args) {
int[] a = {9,3,6,2,5,4,1,8,7};
Arrays.sort(a);
System.out.println(Arrays.binarySearch(a,6));
}
返回值为负数时,返回的是一个插入点 insertion,- insertion - 1即为插入该元素时的位置
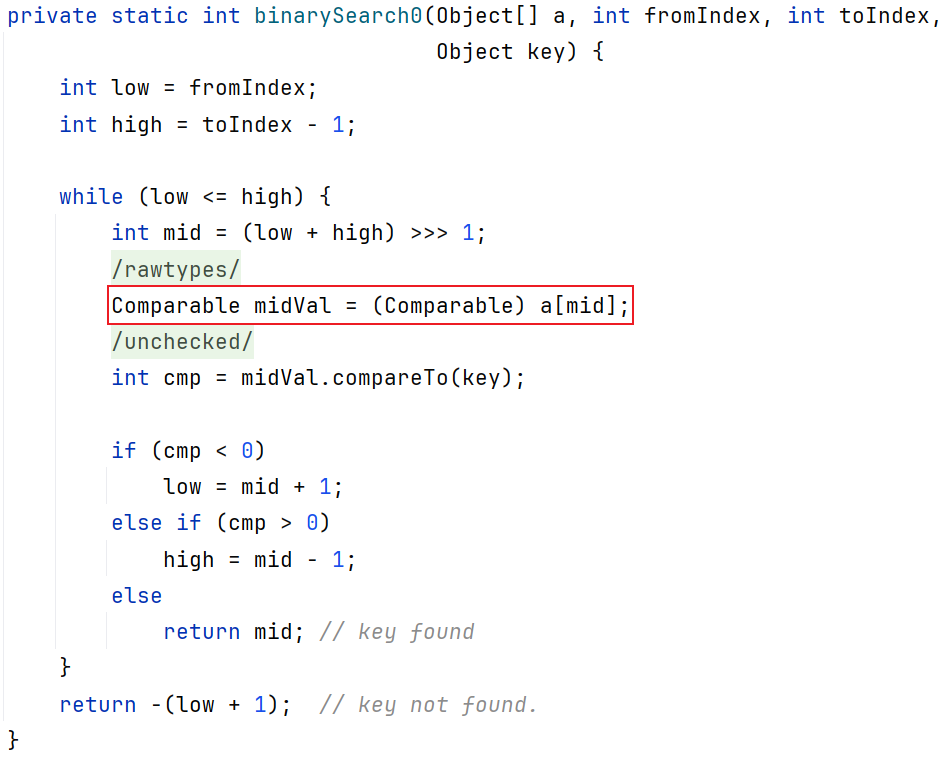
对于Object[] 类型的数组来说,在二分查找的时候会将数组中的元素转换为Comparable类型
Arrays.copyOf(int[] original,int newLength)


Arrays.equals(arr1,arr2)
public static boolean equals(Type[] a1, Type[] a2), 判断两个数组中的内容是否相同。
Arrays.asList(T … a)
//返回和指定数组大小相等的ArrayList,返回的集合是可序列化的,并且实现RandomAccess接口
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
返回的ArrayList是Arrays工具类的一个私有静态内部类:
该集合继承自AbstractList,没有覆盖add/remove方法,会直接调用父类的add/remove,抛出UnsupportedOperationException异常。也就是Arrays.asList()得到的集合大小、长度不可变,但是内容可变(set、replaceAll)
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private static final long serialVersionUID = -2764017481108945198L;
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
@Override
public int size() {
return a.length;
}
@Override
public Object[] toArray() {
return Arrays.copyOf(a, a.length, Object[].class);
}
@Override
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
int size = size();
if (a.length < size)
return Arrays.copyOf(this.a, size,
(Class<? extends T[]>) a.getClass());
System.arraycopy(this.a, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
@Override
public E get(int index) {
return a[index];
}
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
@Override
public int indexOf(Object o) {
E[] a = this.a;
if (o == null) {
for (int i = 0; i < a.length; i++)
if (a[i] == null)
return i;
} else {
for (int i = 0; i < a.length; i++)
if (o.equals(a[i]))
return i;
}
return -1;
}
@Override
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (E e : a) {
action.accept(e);
}
}
@Override
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
E[] a = this.a;
for (int i = 0; i < a.length; i++) {
a[i] = operator.apply(a[i]);
}
}
@Override
public void sort(Comparator<? super E> c) {
Arrays.sort(a, c);
}
@Override
public Iterator<E> iterator() {
return new ArrayItr<>(a);
}
}
数组转型
Integer[] arr = {1,2,3,4};
Object[] objects = arr;
Integer[] integers = (Integer[]) objects;
System.out.println(Arrays.toString(integers));
其实与对象的转型是相同的。
二维数组
二维数组就是一个特殊的一维数组,这个特殊的一维数组中每一个元素是一个一维数组
二维数组初始化
- 静态初始化
int[][] array = {
{10,20,30},
{40,50,60},
{70,80,90}
};
System.out.println(array.length);
System.out.println(array[1].length);
数组的长度是3(3个一维数组),其中第一个一维数组的长度是3
- 动态初始化
int[][] array1 = new int[3][4];
二维数组中的读写
a [ 二维数组中一维数组的下标 ] [一维数组中元素的下标]
a[3] [101]:表示第四个数组中第102个元素
注意:a[3]是一个整体,a[3]结束后的结果再下标101
int[] a0 = a[0];
int a00 = a0[0];
//合并之后就变成了:a[0][0]
二维数组的遍历:
String[][] strArray = {
{"java","c++","c#","python","oracle"},
{"lucy","jack","rose","lisa"},
{"a-train","homelander","starlight"}
};
for (int i = 0; i < strArray.length; i++) {//取出每一个一维数组
for (int j = 0; j < strArray[i].length; j++) {//遍历一维数组中的每个元素
System.out.print(strArray[i][j] + " ");
}
System.out.println('\n');
}
或者使用Java标准库的Arrays.deepToString():
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
System.out.println(Arrays.deepToString(ns));
}
}
二维数组作为参数:
public static void printArray(Object[][] objs){
for (int i = 0; i < objs.length; i++) {
for (int j = 0; j < objs[i].length; j++) {
System.out.print(objs[i][j] + " ");
}
System.out.println('\n');
}
}
调用的时候就可以:
String[][] strArray = {
{"java","c++","c#","python","oracle"},
{"lucy","jack","rose","lisa"},
{"a-train","homelander","starlight"}
};
printArray(strArray);
//或者可以:
printArray(new String[][]{
{"java","c++","c#","python","oracle"},
{"lucy","jack","rose","lisa"},
{"a-train","homelander","starlight"}
});
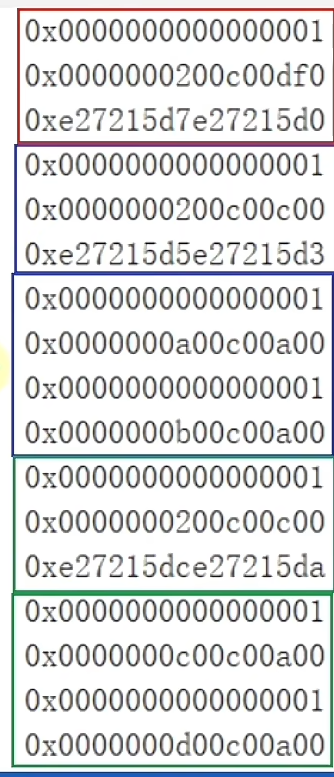
二维数组的内存结构
在堆内存中整体上必须是8的整数倍:
- markword 8字节
- 类型指针 4字节
- 数组长度 4字节
- 数据部分 + 对齐部分
int[][] arr = {
{0xA, 0xA, 0xA, 0xA},
{0xB, 0xB, 0xB, 0xB},
{0xC, 0xC, 0xC, 0xC},
}
外层数组的结构:
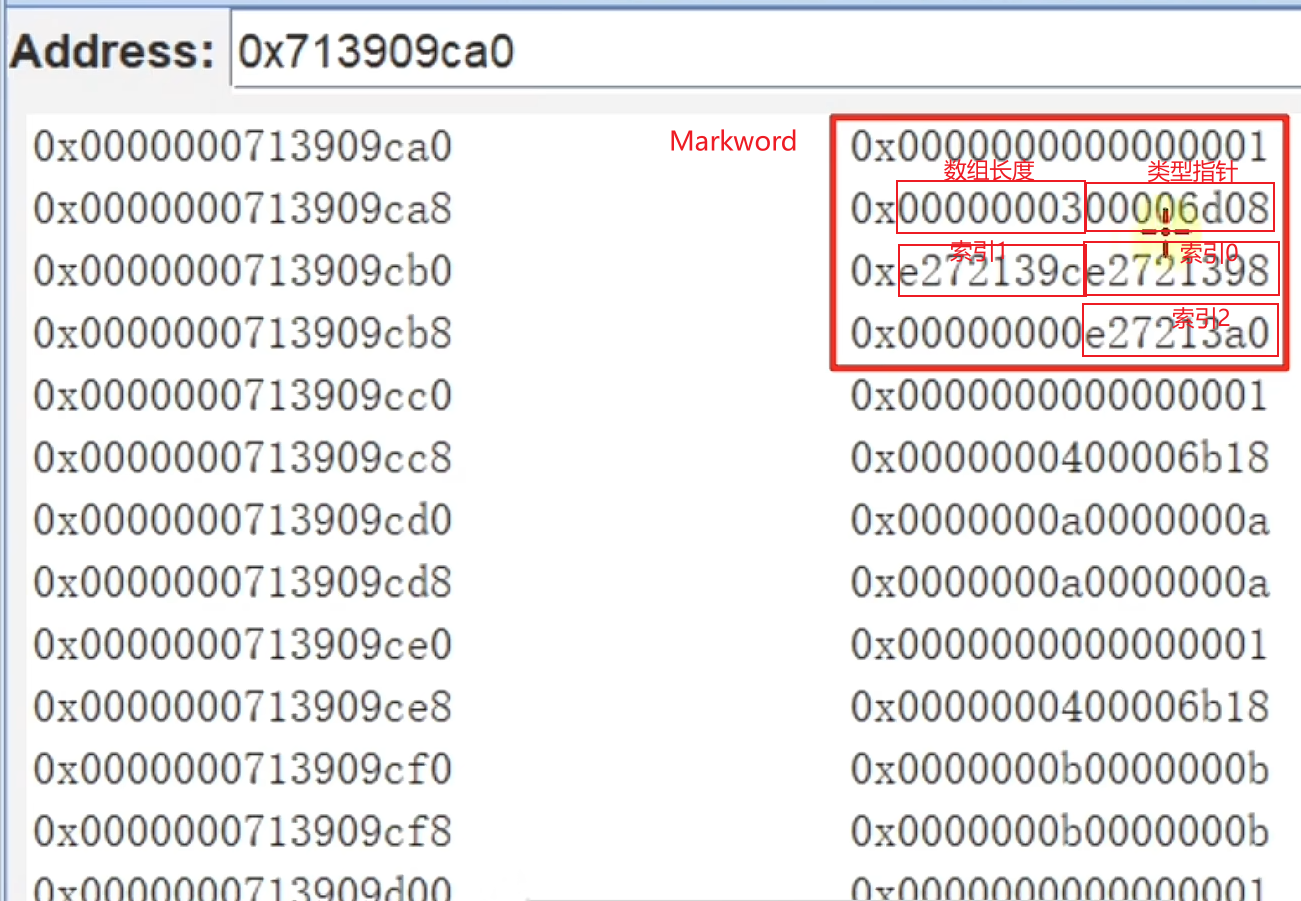
这里的元素引用地址都是压缩后的,需要解压缩 * 8得到真实地址:
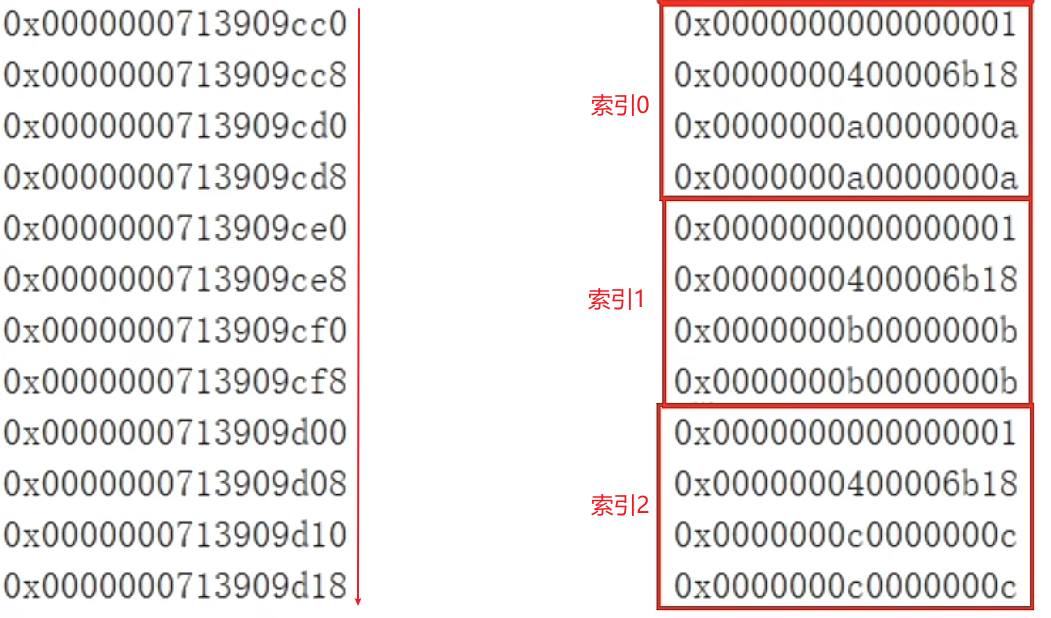
此时的数组是连续的,如果对其中一个数组元素赋一个新值:
arr[0] = new int[]{0x0f,0x0f,0x0f,0x0f};
这个新数组与原来的数组的内存地址大概率是不连续的

地址是不连续的
如果是引用数据类型的二维数组,其中的一维数组的内存地址也是不连续的:
Teacher[][] teachers = {
{new Teacher(0x0a),new Teacher(0x0b)},
{new Teacher(0x0c),new Teacher(0x0d)},
}