
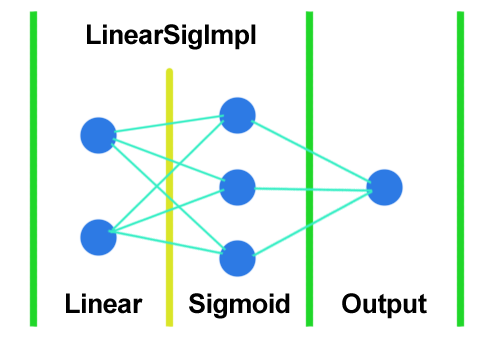
本文以一个例子介绍如何使用libtorch创建一个包含多层神经元的感知机,训练识别异或逻辑。即${ z = x \text{^} y }$。本例的测试环境是VS2017和libtorch1.13.1。从本例可以学到如何复用网络结构,如下方的LinearSigImpl类的写法。该测试网络结构如下图。一个线性层2输入3输出,一个Sigmoid激活函数3输入3输出,一个线性输出层:
头文件代码如下:
class LinearSigImpl : public torch::nn::Module { public: LinearSigImpl(int intput_features, int output_features); torch::Tensor forward(torch::Tensor x); private: torch::nn::Linear ln; torch::nn::Sigmoid bn; }; TORCH_MODULE(LinearSig); class Mlp : public torch::nn::Module { public: Mlp(int in_features, int out_features); torch::Tensor forward(torch::Tensor x); private: LinearSig ln1; torch::nn::Linear output; };
CPP文件:
LinearSigImpl::LinearSigImpl(int in_features, int out_features) : ln(nullptr), bn(nullptr) { ln = register_module("ln", torch::nn::Linear(in_features, out_features)); bn = register_module("bn", torch::nn::Sigmoid()); } torch::Tensor LinearSigImpl::forward(torch::Tensor x) { x = ln->forward(x); x = bn->forward(x); return x; } Mlp::Mlp(int in_features, int out_features) : ln1(nullptr), output(nullptr) { ln1 = register_module("ln1", LinearSig(in_features, 3)); output = register_module("output", torch::nn::Linear(3, out_features)); } torch::Tensor Mlp::forward(torch::Tensor x) { x = ln1->forward(x); x = output->forward(x); return x; } int main() { Mlp linear(2, 1); /* 30个样本。在这里是一行一个样本 */ at::Tensor b = torch::rand({ 30, 2 }); at::Tensor c = torch::zeros({ 30, 1 }); for (int i = 0; i < 30; i++) { b[i][0] = (b[i][0] >= 0.5f); b[i][1] = (b[i][1] >= 0.5f); c[i] = b[i][0].item().toBool() ^ b[i][1].item().toBool(); } //cout << b << endl; //cout << c << endl; /* 训练过程 */ torch::optim::SGD optim(linear.parameters(), torch::optim::SGDOptions(0.01)); torch::nn::MSELoss lossFunc; linear.train(); for (int i = 0; i < 50000; i++) { torch::Tensor predict = linear.forward(b); torch::Tensor loss = lossFunc(predict, c); optim.zero_grad(); loss.backward(); optim.step(); if (i % 2000 == 0) { /* 每2000次循环输出一次损失函数值 */ cout << "LOOP:" << i << ",LOSS=" << loss.item() << endl; } } /* 非线性的网络就不输出网络参数了 */ /* 太过玄学,输出也看不懂 */ /* 做个测试 */ at::Tensor x = torch::tensor({ { 1.0f, 0.0f }, { 0.0f, 1.0f }, { 1.0f, 1.0f }, { 0.0f, 0.0f} }); at::Tensor y = linear.forward(x); cout << "输出为[1100]=" << y; /* 看看能不能泛化 */ x = torch::tensor({ { 0.9f, 0.1f }, { 0.01f, 0.2f } }); y = linear.forward(x); cout << "输出为[10]=" << y; return 0; }
控制台输出如下。如果把0.5作为01分界线,从输出上看网络是有一定的泛化能力的。当然每次运行输出数字都不同,绝大多数泛化结果都正确:
LOOP:0,LOSS=1.56625
LOOP:2000,LOSS=0.222816
LOOP:4000,LOSS=0.220547
LOOP:6000,LOSS=0.218447
LOOP:8000,LOSS=0.215877
LOOP:10000,LOSS=0.212481
LOOP:12000,LOSS=0.207645
LOOP:14000,LOSS=0.199905
LOOP:16000,LOSS=0.187244
LOOP:18000,LOSS=0.168875
LOOP:20000,LOSS=0.145476
LOOP:22000,LOSS=0.118073
LOOP:24000,LOSS=0.087523
LOOP:26000,LOSS=0.0554768
LOOP:28000,LOSS=0.0280211
LOOP:30000,LOSS=0.0109953
LOOP:32000,LOSS=0.00348786
LOOP:34000,LOSS=0.000959343
LOOP:36000,LOSS=0.000243072
LOOP:38000,LOSS=5.89887e-05
LOOP:40000,LOSS=1.40228e-05
LOOP:42000,LOSS=3.3041e-06
LOOP:44000,LOSS=7.82167e-07
LOOP:46000,LOSS=1.85229e-07
LOOP:48000,LOSS=4.43763e-08
输出为[1100]= 0.9999
1.0000
0.0002
0.0001
[ CPUFloatType{4,1} ]输出为[10]= 0.9999
0.4588
[ CPUFloatType{2,1} ]
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。