1 简介
术语
数据库
数据库是“按照数据结构来组织、存储和管理数据的仓库”。
广义上的数据库,在20世纪60年代已经在计算机中应用了。但这个阶段的数据库结构主要是层次或网状的,且数据和程序之间具备非常强的依赖性,应用较为有限。
现在通常所说的数据库指的是关系型数据库。关系数据库是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,具有结构化程度高,独立性强,冗余度低等优点。1970年关系型数据库的诞生,真正彻底把软件中的数据和程序分开来,成为主流计算机系统不可或缺的组成部分。关系型数据库已经成为目前数据库产品中最重要的一员,几乎所有的数据库厂商新出的数据库产品都支持关系型数据库,即使一些非关系数据库产品也几乎都有支持关系数据库的接口。
关系型数据库的主要用于联机事务处理OLTP(On-Line Transaction Processing)主要进行基本的、日常的事务处理,例如银行交易等场景。
数据仓库
随着数据库的大规模应用,使信息行业的数据爆炸式的增长。为了研究数据之间的关系,挖掘数据隐藏的价值,人们越来越多的需要使用联机分析处理OLAP(On-Line Analytical Processing)进行数据分析,探究一些深层次的关系和信息。但是不同的数据库之间很难做到数据共享,数据之间的集成与分析也存在非常大的挑战。
为解决企业的数据集成与分析问题,数据仓库之父比尔·恩门于1990年提出数据仓库(Data Warehouse)。数据仓库主要功能是将OLTP经年累月所累积的大量数据,通过数据仓库特有的数据储存架构进行OLAP,最终帮助决策者能快速有效地从大量数据中,分析出有价值的信息,提供决策支持。自从数据仓库出现之后,信息产业就开始从以关系型数据库为基础的运营式系统慢慢向决策支持系统发展。
数据仓库VS数据库
数据仓库相比数据库,主要有以下两个特点:
-
数据仓库是面向主题集成的。数据仓库是为了支撑各种业务而建立的,数据来自于分散的操作型数据。因此需要将所需数据从多个异构的数据源中抽取出来,进行加工与集成,按照主题进行重组,最终进入数据仓库。
-
数据仓库主要用于支撑企业决策分析,所涉及的数据操作主要是数据查询。因此数据仓库通过表结构优化、存储方式优化等方式提高查询速度、降低开销。
| 维度 | 数据仓库 | 数据库 |
|---|---|---|
| 应用场景 | OLAP | OLTP |
| 数据来源 | 多数据源 | 单数据源 |
| 数据标准化 | 非标准化Schema | 高度标准化的静态Schema |
| 数据读取优势 | 针对读操作进行优化 | 针对写操作进行优化 |
数据湖
在企业内部,数据是一类重要资产已经成为了共识。随着企业的持续发展,数据不断堆积,企业希望把生产经营中的所有相关数据都完整保存下来,进行有效管理与集中治理,挖掘和探索数据价值。
数据湖就是在这种背景下产生的。数据湖是一个集中存储各类结构化和非结构化数据的大型数据仓库,它可以存储来自多个数据源、多种数据类型的原始数据,数据无需经过结构化处理,就可以进行存取、处理、分析和传输。数据湖能帮助企业快速完成异构数据源的联邦分析、挖掘和探索数据价值。
数据湖的本质,是由“数据存储架构+数据处理工具”组成的解决方案。
-
数据存储架构:要有足够的扩展性和可靠性,可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
-
数据处理工具,则分为两大类:
-
第一类工具,聚焦如何把数据“搬到”湖里。包括定义数据源、制定数据同步策略、移动数据、编制数据目录等。
-
第二类工具,关注如何对湖中的数据进行分析、挖掘、利用。数据湖需要具备完善的数据管理能力、多样化的数据分析能力、全面的数据生命周期管理能力、安全的数据获取和数据发布能力。如果没有这些数据治理工具,元数据缺失,湖里的数据质量就没法保障,最终会由数据湖变质为数据沼泽。
-
随着大数据和AI的发展,数据湖中数据的价值逐渐水涨船高,价值被重新定义。数据湖能给企业带来多种能力,例如实现数据的集中式管理,帮助企业构建更多优化后的运营模型,也能为企业提供其他能力,如预测分析、推荐模型等,这些模型能刺激企业能力的后续增长。
数据仓库与数据湖
数据湖和 数据仓库 之所以相似,是因为它们都存储和处理数据,但每个都具有自己的专长,因此都有自己的用例。正因如此,企业级组织通常会在其分析生态系统中纳入数据湖和数据仓库。这两个存储库协同工作,形成一个安全的端到端系统,用于存储、处理数据并更快获得见解。
数据湖从各种源(业务应用程序、移动应用、IoT 设备、社交媒体或流媒体)中捕获关系型数据和非关系型数据,在读取数据前无需定义数据的结构或架构。读取时的架构可确保任何类型的数据都可以以原始格式存储。因此,数据湖可以容纳任何规模的各种数据类型,从结构化数据到半结构化数据,再到非结构化数据均可容纳。其灵活和可缩放的性质使得它们对于使用不同类型的计算处理工具(如 Apache Spark 或 Azure 机器学习)执行复杂形式的数据分析至关重要。
相比之下,数据仓库在本质上是关系型仓库。结构或架构会根据业务和产品要求进行建模或预定义,而这些要求又针对 SQL 查询操作进行精选、合规和优化。数据库可容纳所有结构类型的数据(包括原始和未处理的数据),而数据仓库则存储根据特定目的处理和转换的数据,这些数据可用于支持分析或操作报告。这使得数据仓库非常适合于生成更标准化的 BI 分析,或为已定义的业务用例提供服务。
| 数据湖 | 数据仓库 | |
|---|---|---|
| 类型 | 结构化、半结构化、非结构化 | 结构化 |
| 关系型、非关系型 | 关系型 | |
| 架构 | 读取时的架构 | 写入时的架构 |
| 格式 | 原始、未筛选 | 已处理、已审核 |
| 源 | 大数据、IoT、社交媒体、流数据 | 应用程序、业务、事务数据、批处理报告 |
| 可伸缩性 | 轻松缩放,成本低 | 完成缩放很困难且成本高昂 |
| 用户 | 数据科学家、数据工程师 | 数据仓库专业人员、业务分析师 |
| 用例 | 机器学习、预测分析、实时分析 | 核心报告、BI |
湖仓一体/LakeHouse/数据湖屋
传统的数据湖尽管有许多优点,但并非没有缺点。由于数据湖可以容纳来自各种源的所有类型的数据,因此可能会出现与质量控制、数据损坏和分区不当相关的问题。管理不佳的数据湖不仅会影响数据完整性,而且还可能导致瓶颈、性能缓慢和安全风险。这就是数据湖屋发挥作用的地方。
湖仓一体,又被称为Lake House,其出发点是通过数据仓库和数据湖的打通和融合,让数据流动起来,减少重复建设。Lake House架构最重要的一点,是实现数据仓库和数据湖的数据/元数据无缝打通和自由流动。湖里的“显性价值”数据可以流到仓里,甚至可以直接被数仓使用;而仓里的“隐性价值”数据,也可以流到湖里,低成本长久保存,供未来的数据挖掘使用。
数据湖屋通过直接在云数据湖上添加 增量湖存储层增量湖存储层 来应对传统数据湖的挑战。该存储层提供灵活的分析体系结构,可处理 ACID(原子性、一致性、隔离性和持久性)事务,以实现数据可靠性、流集成和高级功能(如数据版本控制和架构强制)。这样可以在湖上进行一系列分析活动,并且完全不会影响核心数据一致性。虽然湖屋的需求取决于需求的复杂程度,但其灵活性和范围使其成为许多企业组织的最佳解决方案。
| 数据湖 | 湖仓一体/LakeHouse/数据湖屋 | |
|---|---|---|
| 类型 | 结构化、半结构化、非结构化 | 结构化、半结构化、非结构化 |
| 关系型、非关系型 | 关系型、非关系型 | |
| 架构 | 读取时的架构 | 读取时的架构、写入时的架构 |
| 格式 | 原始、未筛选、已处理、已精选 | 原始、未筛选、已处理、已精选、增量格式化文件 |
| 源 | 大数据、IoT、社交媒体、流数据 | 大数据、IoT、社交媒体、流数据、应用程序、业务、事务数据、批处理报告 |
| 可伸缩性 | 轻松缩放,成本低 | 轻松缩放,成本低 |
| 用户 | 数据科学家 | 业务分析师、数据工程师、数据科学家 |
| 用例 | 机器学习、预测分析 | 核心报告、BI、机器学习、预测分析 |
相关企业
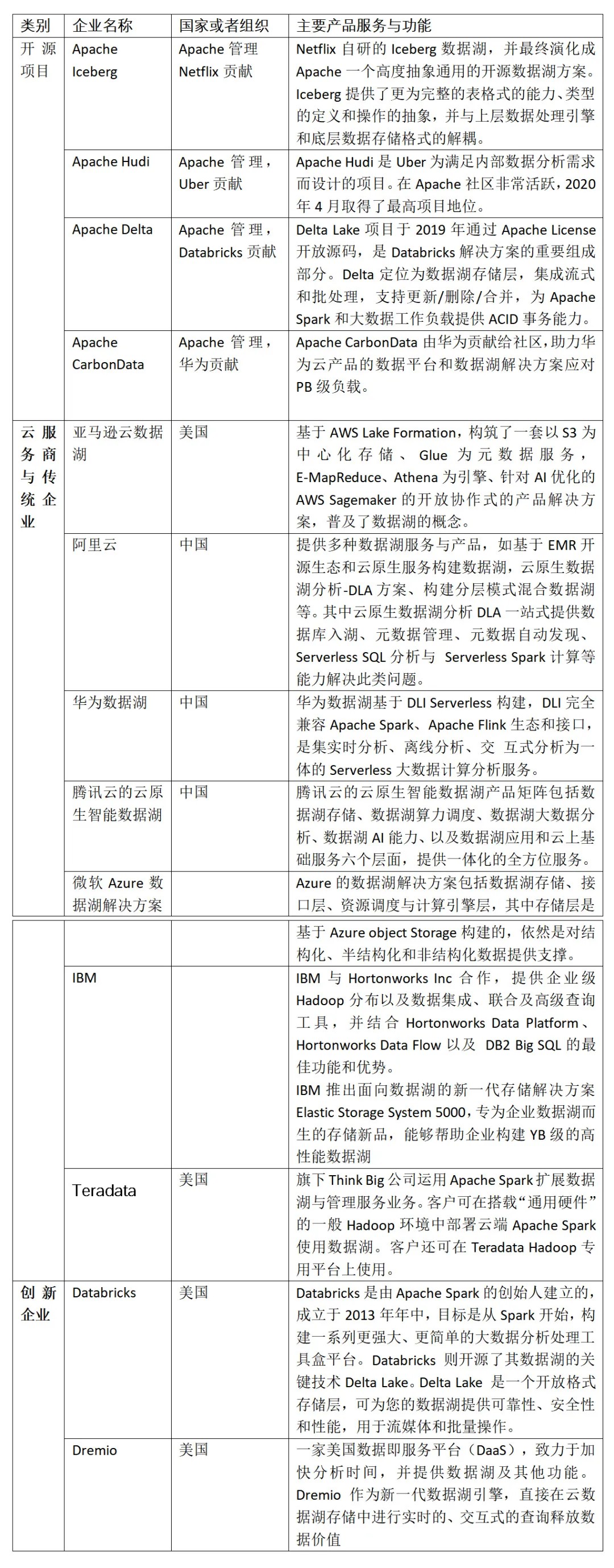
2 开源数据湖组件
市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中广大人民群众的痛点,加上项目各成员积极地社区建设,包括技术细节分享、国内社区推广等等,也在逐步地吸引潜在用户的目光。Apache Iceberg 目前看则会显得相对平庸一些,简单说社区关注度暂时比不上 Delta,功能也不如 Hudi 丰富,但却是一个野心勃勃的项目,因为它具有高度抽象和非常优雅的设计,为成为一个通用的数据湖方案奠定了良好基础。
特性对比
三个引擎的初衷场景并不完全相同
-
Hudi 为了 incremental 的 upserts
-
Iceberg 定位于⾼性能的分析与可靠的数据管理
-
Delta 定位于流批⼀体的数据处理。
这种场景的不同也造成了三者在设计上的差别。尤其是 Hudi,其设计与另外两个相⽐差别更为明显。
Delta、Hudi、Iceberg三个开源项⽬中,Delta和Hudi跟Spark的代码深度绑定,尤其是写⼊路径。这两个项⽬设计之初,都基本上把Spark作为他们的默认计算引擎了。⽽Apache Iceberg的⽅向⾮常坚定,宗旨就是要做⼀个通⽤化设计的Table Format。
Iceberg完美的解耦了计算引擎和底下的存储系统,便于多样化计算引擎和⽂件格式,很好的完成了数据湖架构中的Table Format这⼀层的实现,因此也更容易成为Table Format层的开源事实标准。另⼀⽅⾯,Apache Iceberg也在朝着流批⼀体的数据存储层发展,manifest和snapshot的设计,有效地隔离不同transaction的变更,⾮常⽅便批处理和增量计算。并且,Apache Flink已经是⼀个流批⼀体的计算引擎,⼆者都可以完美匹配,合⼒打造流批⼀体的数据湖架构。

Hudi
Hudi 是一个流式数据湖平台,提供 ACID 功能,支持实时消费增量数据、离线批量更新数据,并且可以通过 Spark、Flink、Presto 等计算引擎进行查询。
Hudi 表由 timeline 和 file group两大项构成。Timeline 由一个个 commit 构成,一次写入过程对应时间线中的一个 commit,记录本次写入修改的文件。相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group 中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 base file 和 log file, log file 记录对 base file 的修改,通过 compaction 合并成新的 base file,多个版本的 base file 会同时存在。在表的更新方面,Hudi 表分为 COW 和 MOR 两种类型:
-
COW 表: 适用于离线批量更新场景,对于更新数据,会先读取旧的 base file,然后合并更新数据,生成新的 base file。
-
MOR 表:适用于实时高频更新场景,更新数据会直接写入 log file 中,读时再进行合并。为了减少读放大的问题,会定期合并 log file 到 base file 中。
对于更新数据,Hudi 通过索引快速定位数据所属的 file group。目前 Hudi 已支持 Bloom Filter Index、Hbase index 以及 Bucket Index,其中 Bucket Index 尚未合并到主分支。
-
字节跳动基于Hudi的优化方案:https://developer.volcengine.com/articles/7220345269954003004
技术内容

IceBerg
Iceberg 是一种适用于 HDFS 或者对象存储的表格式,把底层的 Parquet、ORC 等数据文件组织成一张表,向上层的 Spark,Flink 计算引擎提供表层面的语义,作用类似于 Hive Meta Store,但是和 Hive Meta Store 相比:
-
Iceberg 能避免 File Listing 的开销;
-
也能够提供更丰富的语义,包括 Schema 演进、快照、行级更新、 ACID 增量读等。
Iceberg 相较于 Hive 表是基于设计的文件组织形式实现的上述优点,和 Hive Metastore 把元数据存在 MySQL 上的数据库不一样, Iceberg 是把元数据以文件的形式存在 HDFS 或对象存储上。最上层的 Catalog 也就是表的目录指向了每个表当前版本对应的 Metadata File,由于 Iceberg 使用 MVCC,所以每次对表的变更都会产生一个新版本的 Metadata File。
3 湖仓一体
湖仓一体是指融合数据湖与数据仓库的优势,形成一体化、开放式数据处理平台的技术。通过湖仓一体技术,可使得数据处理平台底层支持多数据类型统一存储,实现数据在数据湖、数据仓库之间无缝调度和管理,并使得上层通过统一接口进行访问查询和分析。
企业需求的驱动下,数据湖与数据仓库在原本的范式之上向其限制范围扩展,逐渐形成了“湖上建仓”与“仓外挂湖”两种湖仓一体实现路径。湖上建仓和仓外挂湖虽然出发点不同,但最终湖仓一体的目标一致。
湖上建仓
解决数据湖限制的新系统开始出现,LakeHouse是一种结合了数据湖和数据仓库优势的新范式。LakeHouse使用新的系统设计:直接在用于数据湖的低成本存储上实现与数据仓库中类似的数据结构和数据管理功能。如果你现在需要重新设计数据仓库,鉴于现在存储(以对象存储的形式)廉价且高可靠,不妨可以使用LakeHouse。
-
数据仓库:数仓这样的一种数据存储架构,它主要存储的是以关系型数据库组织起来的结构化数据。数据通过转换、整合以及清理,并导入到目标表中。在数仓中,数据存储的结构与其定义的schema是强匹配的。
-
数据湖:数据湖这样的一种数据存储结构,它可以存储任何类型的数据,包括像图片、文档这样的非结构化数据。数据湖通常更大,其存储成本也更为廉价。存储其中的数据不需要满足特定的schema,数据湖也不会尝试去将特定的schema施行其上。相反的是,数据的拥有者通常会在读取数据的时候解析schema(schema-on-read),当处理相应的数据时,将转换施加其上。
当初许多的公司往往同时会搭建数仓、数据湖这两种存储架构,一个大的数仓和多个小的数据湖。这样,数据在这两种存储中就会有肯定的冗余。
Data Lakehouse的出现试图去交融数仓和数据湖这两者之间的差别,通过将数仓构建在数据湖上,使得存储变得更为便宜和弹性,同时lakehouse能够有效地提升数据质量,减小数据冗余。在lakehouse的构建中,ETL起了非常重要的作用,它能够将未经规整的数据湖层数据转换成数仓层结构化的数据。Data Lakehouse概念是由Databricks在此文[1]中提出的,在提出概念的同时,也列出了如下一些特性:
-
事务支持:Lakehouse可以处理多条不同的数据管道。这意味着它可以在不破坏数据完整性的前提下支持并发的读写事务。
-
模式执行和治理(Schema enforcement and governance):LakeHouse应该有一种可以支持模式执行和演进、支持DW模式的范式(如star/snowflake-schemas)。该系统应该能够推理数据完整性,并具有健壮的治理和审计机制。
-
Schemas:数仓会在所有存储其上的数据上施加Schema,而数据湖则不会。Lakehouse的架构可以根据应用的需求为绝大多数的数据施加schema,使其标准化。
-
BI支持:LakeHouse可以直接在源数据上使用BI工具。这样可以提高数据新鲜度,减少等待时间,降低必须同时在数据湖和数据仓库中操作两个数据副本的成本
-
存储与计算分离:这意味着存储和计算使用单独的集群,因此这些系统能够支持更多用户并发和更大数据量。一些现代数据仓库也具有此属性。
-
报表以及分析应用的支持:报表和分析应用都可以使用这一存储架构。Lakehouse里面所保存的数据经过了清理和整合的过程,它可以用来加速分析。同时相比于数仓,它能够保存更多的数据,数据的时效性也会更高,能显著提升报表的质量。
-
数据类型扩展:数仓仅可以支持结构化数据,而Lakehouse的结构可以支持更多不同类型的数据,包括文件、视频、音频和系统日志。
-
端到端的流式支持:Lakehouse可以支持流式分析,从而能够满足实时报表的需求,实时报表在现在越来越多的企业中重要性在逐渐提高。
-
开放性:Lakehouse在其构建中通常会使Iceberg,Hudi,Delta Lake等组件,首先这些组件是开源开放的,其次这些组件采用了Parquet,ORC这样开放兼容的存储格式作为下层的数据存储格式,因此不同的引擎,不同的语言都可以在Lakehouse上进行操作
Lakehouse的概念最早是由Databricks所提出的,而其他的类似的产品有Azure Synapse Analytics。Lakehouse技术仍然在发展中,因此上面所述的这些特性也会被不断的修订和改进。

案例-AWS-智能湖仓

案例-Databricks –Delta Lake
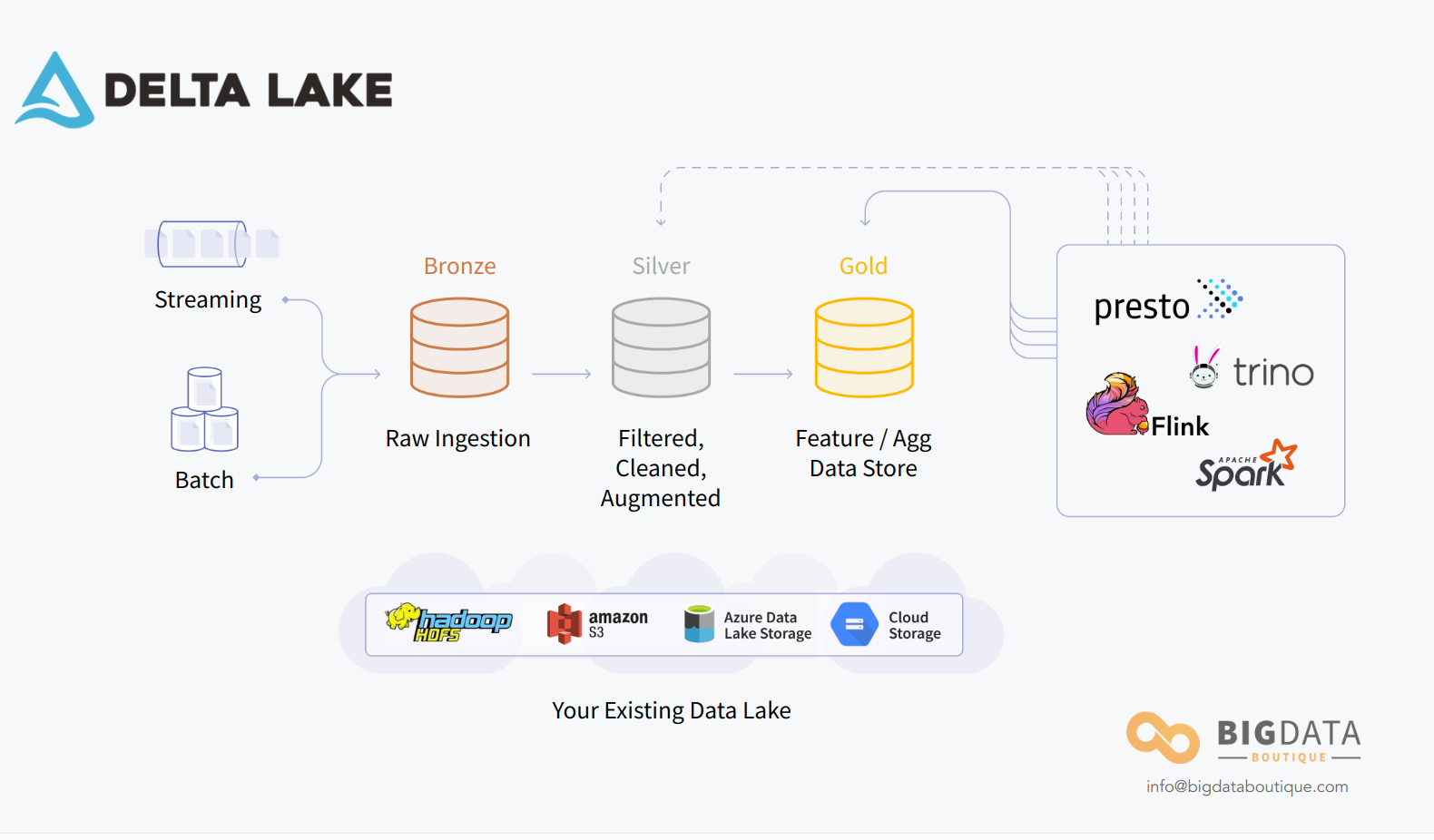
仓外挂湖
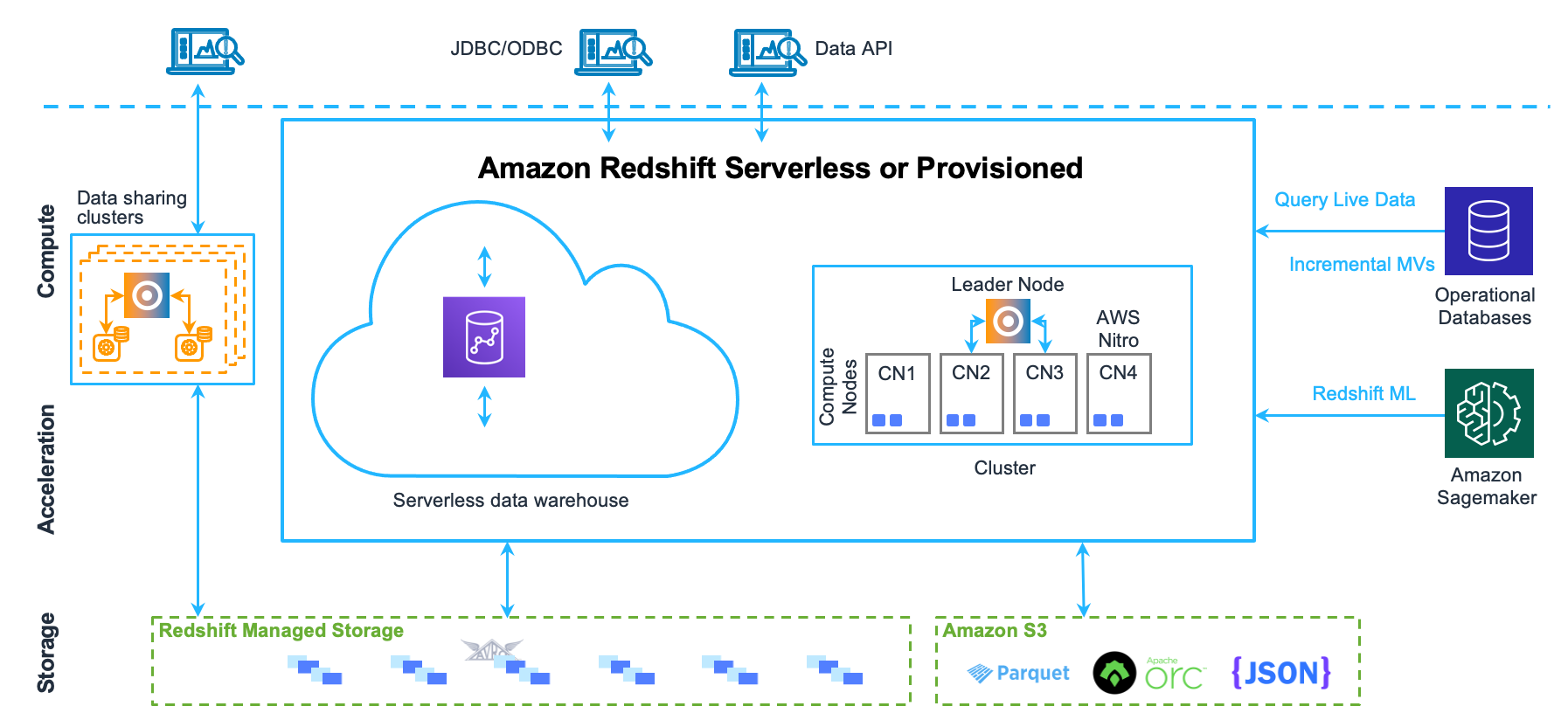
仓外挂湖是指以 MPP 数据库为基础,使用可插拔架构,通过开放接口对接外部存储实现统一存储,在存储底层共享一份数据,计算、存储完全分离,实现从强管理到兼容开放存储和多引擎。代表产品: Snowflake、AWS Redshift、阿里云 MaxCompute/Hologres 湖仓一体。
MPP 数据库技术体系,从关系型数据库演进而来,对事务一致性、联机分析处理性能都有较好的支撑,但在分析场景方面存在较大的局限性,主要以结构化数据分析为主,无法支撑半/非结构化数据存储、实时计算、机器学习等场景。所以实现途径中,实现方向为增加存储能力,提升查询引擎效率。
总的来看,“仓外挂湖”路径本质是在仓的基础上增加湖的多类型存储等能力,需解决以下五大技术难点:
-
一是统一元数据管理。打通不同数据系统,具备数据共享和跨库分析的能力,并支持互联互通、计算下推、协同计算,实现数据多平之间透明流动。仓外挂湖路径目前主要是将对接外部存储如Hadoop、对象存储等的元数据进行采集,统一存储、管理。
-
二是存储开放性。仓外挂湖路径的存储开放性主要表现在:存储介质兼容方面,将非数仓自身存储如 Hadoop、云对象存储等的数据纳入管理;数据格式方面,采用开放、标准化的数据格式,既包含Hudi、 Iceberg、Delta Lake 等开放格式,也包括 Parquet、ORC、CSV 等存储格式的支持。
-
三是扩展查询引擎。仓外挂湖路径保留原 MPP 计算引擎计算能力的基础之上,主要是增加批处理和实时数据处理的能力。其中批处理方面是融合更轻量级、高效率的计算能力,而实时处理方面则是通过微批以及增量计算的方式,增强流的计算能力。
-
四是存算分离。仓外挂湖需进行存算分离架构改造,而传统的 MPP 存算耦合架构,不具备云原生能力。目前,仓外挂湖路径主要基于存算分离架构改造后的云原生 MPP 数据库实现。
-
五是弹性伸缩。基于 K8S、Docker 等容器化技术对 MPP 体系的组件、服务进行容器化改造。目前该路径有实现计算层、存储层弹性伸缩,少量产品实现了根据业务负载自动弹性伸缩计算资源。
案例-阿里-湖仓一体

案例-AWS Redshift
4 企业案例
腾讯
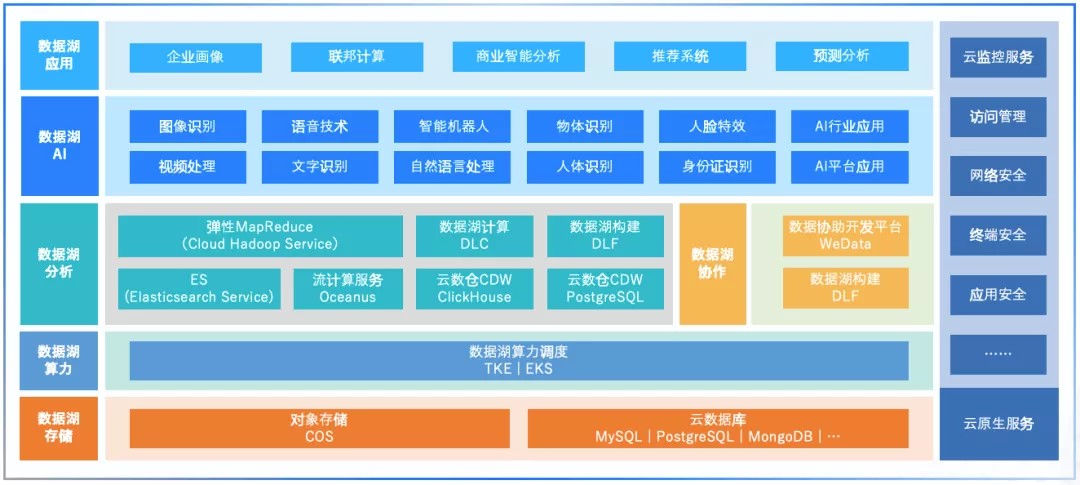
阿里-湖仓一体
参考
-
数据湖、数据仓库定义
-
湖仓一体:https://help.aliyun.com/zh/maxcompute/user-guide/lakehouse-of-maxcompute
-
亚马逊智能湖仓:https://aws.amazon.com/cn/blogs/china/build-intelligent-lake-warehouse-on-amazon-cloud-technology/
-
字节数据湖:https://developer.volcengine.com/articles/7220345269954003004