
一、简介
在 Java 的java.util.concurrent包中,除了提供底层锁、并发同步等工具类以外,还提供了一组原子操作类,大多以Atomic开头,他们位于java.util.concurrent.atomic包下。
所谓原子类操作,顾名思义,就是这个操作要么全部执行成功,要么全部执行失败,是保证并发编程安全的重要一环。
相比通过synchronized和lock等方式实现的线程安全同步操作,原子类的实现机制则完全不同。它采用的是通过无锁(lock-free)的方式来实现线程安全(thread-safe)访问,底层原理主要基于CAS操作来实现。
某些业务场景下,通过原子类来操作,既可以实现线程安全的要求,又可以实现高效的并发性能,同时编程方面更加简单。
下面我们一起来看看它的具体玩法!
二、常用原子操作类
在java.util.concurrent.atomic包中,因为原子类众多,如果按照类型进行划分,可以分为五大类,每个类型下的原子类可以用如下图来概括(不同 JDK 版本,可能略有不同,本文主要基于 JDK 1.8 进行采样)。
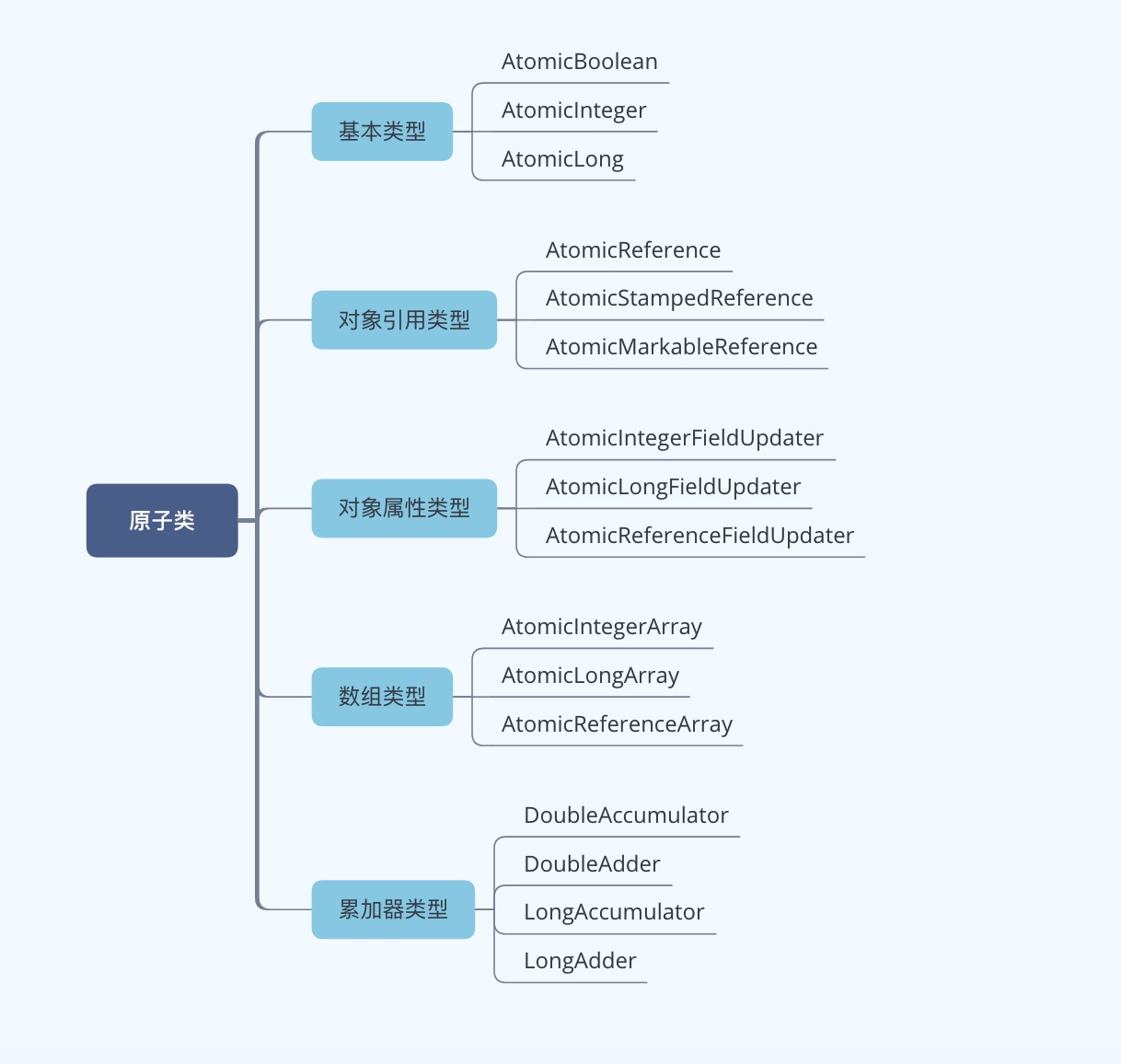
虽然原子操作类很多,但是大体的用法基本类似,只是针对不同的数据类型进行了单独适配,这些原子类都可以保证多线程下数据的安全性,使用起来也比较简单。
2.1、基本类型
基本类型的原子类,也是最常用的原子操作类,JDK为开发者提供了三个基础类型的原子类,内容如下:
AtomicBoolean:布尔类型的原子操作类AtomicInteger:整数类型的原子操作类AtomicLong:长整数类型的原子操作类
以AtomicInteger为例,常用的操作方法如下:
| 方法 | 描述 |
|---|---|
int get() |
获取当前值 |
void set(int newValue) |
设置 value 值 |
int getAndIncrement() |
先取得旧值,然后加1,最后返回旧值 |
int getAndDecrement() |
先取得旧值,然后减1,最后返回旧值 |
int incrementAndGet() |
加1,然后返回新值 |
int decrementAndGet() |
减1,然后返回新值 |
int getAndAdd(int delta) |
先取得旧值,然后增加指定值,最后返回旧值 |
int addAndGet(int delta) |
增加指定值,然后返回新值 |
boolean compareAndSet(int expect, int update) |
直接使用CAS方式,将【旧值】更新成【新值】,核心方法 |
AtomicInteger的使用方式非常简单,使用示例如下:
AtomicInteger atomicInteger = new AtomicInteger();
// 先获取值,再自增,默认初始值为0
int v1 = atomicInteger.getAndIncrement();
System.out.println("v1:" + v1);
// 获取自增后的ID值
int v2 = atomicInteger.incrementAndGet();
System.out.println("v2:" + v2);
// 获取自减后的ID值
int v3 = atomicInteger.decrementAndGet();
System.out.println("v3:" + v3);
// 使用CAS方式,将就旧值更新成 10
boolean v4 = atomicInteger.compareAndSet(v3,10);
System.out.println("v4:" + v4);
// 获取最新值
int v5 = atomicInteger.get();
System.out.println("v5:" + v5);
输出结果:
v1:0
v2:2
v3:1
v4:true
v5:10
下面我们以对某个变量累加 10000 次为例,采用 10 个线程,每个线程累加 1000 次来实现,对比不同的实现方式执行结果的区别(预期结果值为 10000)。
方式一:线程不安全操作实现
public class Demo1 {
/**
* 初始化一个变量
*/
private static volatile int a = 0;
public static void main(String[] args) throws InterruptedException {
final int threads = 10;
CountDownLatch countDownLatch = new CountDownLatch(threads);
for (int i = 0; i < threads; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 1000; j++) {
a++;
}
countDownLatch.countDown();
}
}).start();
}
// 阻塞等待10个线程执行完毕
countDownLatch.await();
// 输出结果值
System.out.println("结果值:" + a);
}
}
输出结果:
结果值:9527
从日志上可以很清晰的看到,实际结果值与预期不符,即使变量a加了volatile关键字,也无法保证累加结果的正确性。
针对volatile关键字,在之前的文章中我们有所介绍,它只能保证变量的可见性和程序的有序性,无法保证程序操作的原子性,导致运行结果与预期不符。
方式二:线程同步安全操作实现
public class Demo2 {
/**
* 初始化一个变量
*/
private static int a = 0;
public static void main(String[] args) throws InterruptedException {
final int threads = 10;
CountDownLatch countDownLatch = new CountDownLatch(threads);
for (int i = 0; i < threads; i++) {
new Thread(new Runnable() {
@Override
public void run() {
synchronized (Demo2.class){
for (int j = 0; j < 1000; j++) {
a++;
}
}
countDownLatch.countDown();
}
}).start();
}
// 阻塞等待10个线程执行完毕
countDownLatch.await();
// 输出结果值
System.out.println("结果值:" + a);
}
}
输出结果:
结果值:10000
当多个线程操作同一个变量或者方法的时候,可以在方法上加synchronized关键字,可以同时实现变量的可见性、程序的有序性、操作的原子性,达到运行结果与预期一致的效果。
同时也可以采用Lock锁来实现多线程操作安全的效果,执行结果也会与预期一致。
方式三:原子类操作实现
public class Demo3 {
/**
* 初始化一个原子操作类
*/
private static AtomicInteger a = new AtomicInteger();
public static void main(String[] args) throws InterruptedException {
final int threads = 10;
CountDownLatch countDownLatch = new CountDownLatch(threads);
for (int i = 0; i < threads; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 1000; j++) {
// 采用原子性操作累加
a.incrementAndGet();
}
countDownLatch.countDown();
}
}).start();
}
// 阻塞等待10个线程执行完毕
countDownLatch.await();
// 输出结果值
System.out.println("结果值:" + a.get());
}
}
输出结果:
结果值:10000
从日志结果上可见,原子操作类也可以实现在多线程环境下执行结果与预期一致的效果,关于底层实现原理,我们等会在后文中进行介绍。
与synchronized和Lock等实现方式相比,原子操作类因为采用无锁的方式实现,因此某些场景下可以带来更高的执行效率。
2.2、对象引用类型
上文提到的基本类型的原子类,只能更新一个变量,如果需要原子性更新多个变量,这个时候可以采用对象引用类型的原子操作类,将多个变量封装到一个对象中,JDK为开发者提供了三个对象引用类型的原子类,内容如下:
AtomicReference:对象引用类型的原子操作类AtomicStampedReference:带有版本号的对象引用类型的原子操作类,可以解决 ABA 问题AtomicMarkableReference:带有标记的对象引用类型的原子操作类
以AtomicReference为例,构造一个对象引用,具体用法如下:
public class User {
private String name;
private Integer age;
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
AtomicReference<User> atomicReference = new AtomicReference<>();
// 设置原始值
User user1 = new User("张三", 20);
atomicReference.set(user1);
// 采用CAS方式,将user1更新成user2
User user2 = new User("李四", 21);
atomicReference.compareAndSet(user1, user2);
System.out.println("更新后的对象:" + atomicReference.get().toString());
输出结果:
更新后的对象:User{name='李四', age=21}
2.3、对象属性类型
在某项场景下,可能你只想原子性更新对象中的某个属性值,此时可以采用对象属性类型的原子操作类,JDK为开发者提供了三个对象属性类型的原子类,内容如下:
AtomicIntegerFieldUpdater:属性为整数类型的原子操作类AtomicLongFieldUpdater:属性为长整数类型的原子操作类AtomicReferenceFieldUpdater:属性为对象类型的原子操作类
需要注意的是,这些原子操作类需要满足以下条件才可以使用。
- 1.被操作的字段不能是 static 类型
- 2.被操纵的字段不能是 final 类型
- 3.被操作的字段必须是 volatile 修饰的
- 4.属性必须对于当前的 Updater 所在区域是可见的,简单的说就是尽量使用
public修饰字段
以AtomicIntegerFieldUpdater为例,构造一个整数类型的属性引用,具体用法如下:
public class User {
private String name;
/**
* age 字段加上 volatile 关键字,并且改成 public 修饰
*/
public volatile int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
}
User user = new User("张三", 20);
AtomicIntegerFieldUpdater<User> fieldUpdater = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
// 将 age 的年龄原子性操作加 1
fieldUpdater.getAndIncrement(user);
System.out.println("更新后的属性值:" + fieldUpdater.get(user));
输出结果:
更新后的属性值:21
2.4、数组类型
数组类型的原子操作类,并不是指对数组本身的原子操作,而是对数组中的元素进行原子性操作,这一点需要特别注意,如果要针对整个数组进行更新,可以采用对象引入类型的原子操作类进行处理。
JDK为开发者提供了三个数组类型的原子类,内容如下:
AtomicIntegerArray:数组为整数类型的原子操作类AtomicLongArray:数组为长整数类型的原子操作类AtomicReferenceArray:数组为对象类型的原子操作类
以AtomicIntegerArray为例,具体用法如下:
int[] value = new int[]{0, 3, 5};
AtomicIntegerArray array = new AtomicIntegerArray(value);
// 将下标为[0]的元素,原子性操作加 1
array.getAndIncrement(0);
System.out.println("下标为[0]的元素,更新后的值:" + array.get(0));
输出结果:
下标为[0]的元素,更新后的值:1
2.5、累加器类型
累加器类型的原子操作类,是从 jdk 1.8 开始加入的,专门用来执行数值类型的数据累加操作,性能更好。
它的实现原理与基本数据类型的原子类略有不同,当多线程竞争时采用分段累加的思路来实现目标值,在多线程环境中,它比AtomicLong性能要高出不少,特别是写多的场景。
JDK为开发者提供了四个累加器类型的原子类,内容如下:
LongAdder:长整数类型的原子累加操作类LongAccumulator:LongAdder的功能增强版,它支持自定义的函数操作DoubleAdder:浮点数类型的原子累加操作类DoubleAccumulator:同样的,也是DoubleAdder的功能增强版,支持自定义的函数操作
以LongAdder为例,具体用法如下:
LongAdder adder = new LongAdder();
// 自增加 1,默认初始值为0
adder.increment();
adder.increment();
adder.increment();
System.out.println("最新值:" + adder.longValue());
输出结果:
最新值:3
三、原理解析
在上文中,我们提到了原子类的底层主要基于CAS来实现,CAS的全称是:Compare and Swap,翻译过来就是:比较并替换。
CAS是实现并发算法时常用的一种技术,它包含三个操作数:内存位置、预期原值及新值。在执行CAS操作的时候,会将内存位置的值与预期原值比较,如果一致,会将该位置的值更新为新值;否则,不做任何操作。
我们还是以上文介绍的AtomicInteger为例,部分源码内容如下:
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
// 使用 Unsafe.compareAndSwapInt 方法进行 CAS 操作
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// 变量使用 volatile 保证可见性
private volatile int value;
/**
* get 方法
*/
public final int get() {
return value;
}
/**
* 原子性自增操作
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
}
从源码上可以清晰的看出,变量value使用了volatile关键字,保证数据可见性和程序的有序性;原子性自增操作incrementAndGet()方法,路由到Unsafe.getAndAddInt()方法上。
我们继续往下看Unsafe.getAndAddInt()这个方法,部分源码内容如下:
public final class Unsafe {
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
// 1.循环比较并替换,只有成功才返回
do {
// 2.调用底层方法得到 value 值
var5 = this.getIntVolatile(var1, var2);
// 3.通过var1和var2得到底层值,var5为当前值,如果底层值与当前值相同,则将值设为var5+var4
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
// 4.如果替换成功,返回当前值
return var5;
}
/**
* CAS 核心方法,由其他语言实现,不再分析
*/
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
}
从以上的源码可以清晰的看到,incrementAndGet()方法主要基于Unsafe.compareAndSwapInt方法来实现,同时进行了循环比较与替换的操作,只有替换成功才会返回,这个过程也被称为自旋操作,确保程序执行成功,进一步保证了操作的原子性。
其它的方法实现思路也类似。
如果我们自己通过CAS编写incrementAndGet(),大概长这样:
public int incrementAndGet(AtomicInteger var) {
int prev, next;
do {
prev = var.get();
next = prev + 1;
} while ( !var.compareAndSet(prev, next));
return next;
}
当并发数量比较低的时候,采用CAS这种方式可以实现更快的执行效率;当并发数量比较高的时候,因为存在循环比较与替换的逻辑,如果长时间循环,可能会更加消耗 CPU 资源,此时采用synchronized或Lock来实现线程同步,可能会更有优势。
四、ABA问题
从上文的分析中,我们知道 CAS 在操作的时候会检查预期原值是否发生变化,当预期原值没有发生变化才会更新值。
在实际业务中,可能会出现这么一个现象:线程 t1 正尝试将共享变量的值 A 进行修改,但还没修改;此时另一个线程 t2 获取到 CPU 时间片,将共享变量的值 A 修改成 B,然后又修改为 A,此时线程 t1 检查发现共享变量的值没有发生变化,就会主动去更新值,导致出现了错误更新,但是实际上原始值在这个过程中发生了好几次变化。这个现象我们称它为 ABA 问题。
ABA 问题的解决思路就是使用版本号,在变量前面追加上版本号,每次变量更新的时候把版本号加 1,原来的A-B-A就会变成1A-2B-3A。
在java.util.concurrent.atomic包下提供了AtomicStampedReference类,它支持指定版本号来更新,可以通过它来解决 ABA 问题。
在AtomicStampedReference类的compareAndSet()方法中,会检查当前引用是否等于预期引用,并且当前版本号是否等于预期版本号,如果全部相等,则以原子方式将该引用的值设置为给定的更新值,同时更新版本号。
具体示例如下:
// 初始化一个带版本号的原子操作类,原始值:a,原始版本号:1
AtomicStampedReference<String> reference = new AtomicStampedReference<>("a", 1);
// 将a更为b,同时将版本号加1,第一个参数:预期原值;第二个参数:更新后的新值;第三个参数:预期原版本号;第四个参数:更新后的版本号
boolean result1 = reference.compareAndSet("a", "b", reference.getStamp(), reference.getStamp() + 1);
System.out.println("第一次更新:" + result1);
// 将b更为a,因为预期原版本号不对,所以更新失败
boolean result2 = reference.compareAndSet("b", "a", 1, reference.getStamp());
System.out.println("第二次更新:" + result2);
输出结果:
第一次更新:true
第二次更新:false
五、小结
本文主要围绕AtomicInteger的用法和原理进行一次知识总结,JUC包下的原子操作类非常的多,但是大体用法基本相似,只是针对不同的数据类型做了细分处理。
在实际业务开发中,原子操作类通常用于计数器,累加器等场景,比如编写一个多线程安全的全局唯一 ID 生成器。
public class IdGenerator {
private static AtomicLong atomic = new AtomicLong(0);
public long getNextId() {
return atomic.incrementAndGet();
}
}
希望本篇的知识总结,能帮助到大家!
六、参考
1.https://www.liaoxuefeng.com/wiki/1252599548343744/1306581083881506
2.https://blog.csdn.net/zzti_erlie/article/details/123001758
3.https://juejin.cn/post/7057032581165875231

