大模型如火如荼的今天,不学点语言模型(LM)相关的技术实在是说不过去了。只不过由于过往项目用到LM较少,所以学习也主要停留在直面——动眼不动手的水平。Huggingface(HF)也是现在搞LM离不开的工具了。
出于项目需要,以及实践出真知的想法,在此记录一下第一次使用HF和微调ERNIE-gram的过程。
目录
开始的开始
HF已经做的很好了。但是对于第一次上手实操LM的我来说,还是有点陌生的。上手时有几个问题是一直困扰我的:
- HF上这么多模型,我该用哪一个?
- 每个LM的主要作用是对文本进行Embedding,可我的任务是句子对相似性计算,这该怎么搞?
- 我想在自己的数据上继续微调模型,该怎么做?
模型选择
简单描述一下我的任务:给定两个句子,判断两个句子的语义是否等价。
从NLP的角度出发,这是一类STS(Semantic Textual Similarity)任务,本质是在比较两个文本的语义是否相似。通过检索,找到了一些相关的比赛,例如问题匹配的比赛和相关的模型,这里简单罗列一下:
- 千言数据集:问题匹配鲁棒性。
- 千言-问题匹配鲁棒性评测基线。
- Quora Question Pairs。
- ATEC学习赛:NLP之问题相似度计算。
- 第三届魔镜杯大赛—— 语义相似度算法设计。
- LCQMC通用领域问题匹配数据集。
- [Chinese-BERT-wwm]。
通过以上资料,我大致确定了我要使用的模型——ERNIE-Gram[1]。
如何使用选好的模型
首先,我找到了ERNIE-Gram的代码仓库[2]。代码里开源了模型的结构以及微调的代码,相对来说还是比较齐全的。但是有一个最不方便的地方——它是用飞浆写的(不是说飞浆不好,只是一直以来都用pytorch)。当然,很快我又找到了pytorch版的ERNIE-Gram,并且在HF找到了ERNIE-Gram模型。如果我知道怎么使用HF,那么或许我可以很快开始我的微调了,可惜没有如果。
那怎么使用HF上的模型,在自己的数据上进行微调呢?
找到了一篇比较合适的参考资料[3],其中介绍了如何在HF中调用ERNIE模型:
from transformers import BertTokenizer, ErnieModel
tokenizer = BertTokenizer.from_pretrained("nghuyong/ernie-1.0-base-zh")
model = ErnieModel.from_pretrained("nghuyong/ernie-1.0-base-zh")
根据这个,我发现通过HF使用某个模型的方法是从transformers库中导入对应的模型和工具即可。那么,我只需要找到对应的模型名和工具,然后以此作为基座,再添加一些可训练层就可以了?
分析dir(transformers)看看都有哪些和Ernie相关的类:
d = dir(transformers)
dd = [e for e in d if 'ernie' in e.lower()]
len(dd) # 26
print(dd)
# ====
['ERNIE_M_PRETRAINED_CONFIG_ARCHIVE_MAP', 'ERNIE_M_PRETRAINED_MODEL_ARCHIVE_LIST', 'ERNIE_PRETRAINED_CONFIG_ARCHIVE_MAP', 'ERNIE_PRETRAINED_MODEL_ARCHIVE_LIST', 'ErnieConfig', 'ErnieForCausalLM', 'ErnieForMaskedLM', 'ErnieForMultipleChoice', 'ErnieForNextSentencePrediction', 'ErnieForPreTraining', 'ErnieForQuestionAnswering', 'ErnieForSequenceClassification', 'ErnieForTokenClassification', 'ErnieMConfig', 'ErnieMForInformationExtraction', 'ErnieMForMultipleChoice', 'ErnieMForQuestionAnswering', 'ErnieMForSequenceClassification', 'ErnieMForTokenClassification', 'ErnieMModel', 'ErnieMPreTrainedModel', 'ErnieMTokenizer', 'ErnieModel', 'ErniePreTrainedModel', 'models.ernie', 'models.ernie_m']
为了更好了解每个类是干啥的,直接上transformers库来看各个类的介绍[4]。很快啊,我就发现ErnieForSequenceClassification很适合我的任务:
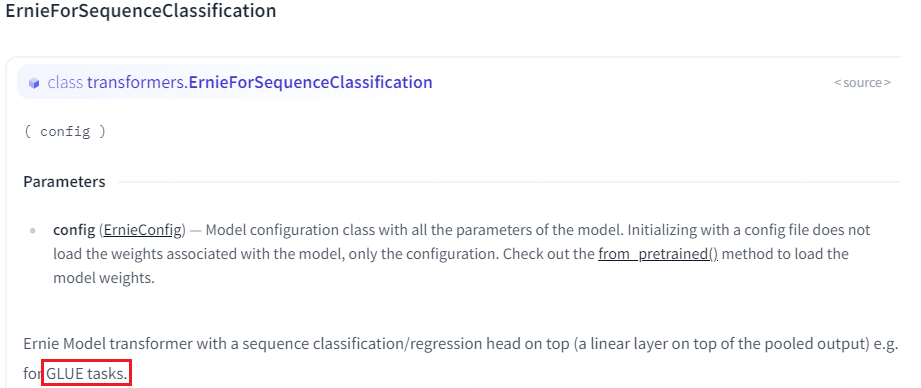
图中的GLUE(General Language Understanding Evaluation )[5]是一系列评测任务集合,显然,我的任务属于Similarity那一类。

很好,大致可以确定该怎么使用HF上的Ernie-Gram模型来完成我的任务了(可惜没有对应的示例)。
怎么微调
在实操之前,对于在预训练好的模型上进行微调,我的想法是:把预训练模型包起来,添加一个分类层,学习分类层的参数就可以了。
但是如果我选择了ErnieForSequenceClassification,通过源码可以发现该类其实是在ErnieModel的基础上添加了一个分类层,那我是否直接加载模型后,选择训练哪些参数就可以了呢?
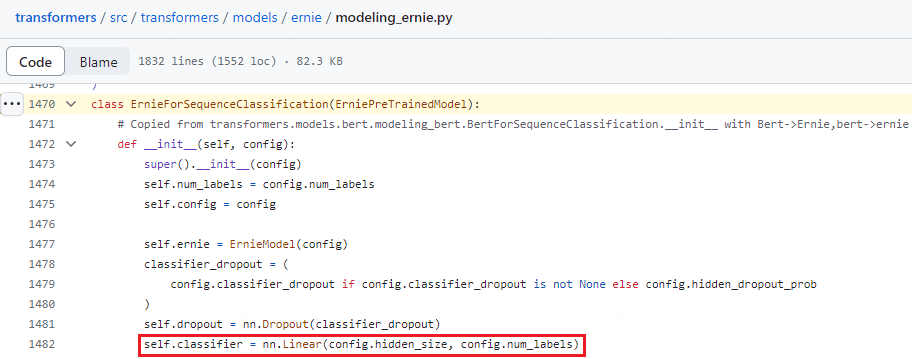
其实,广义的来说,这等价于一个问题:在HuggingFace中如何微调模型?[6][7][8]。
其实,微调和平常的模型训练没有太大区别,只不过需要加载预训练好的模型,以及利用现成的工具搭建训练流程,其中主要涉及到的就两点:模型的定义、训练流程的搭建。
模型定义
由于transformers中已经定义好了很多模型,如果某个完全符合要求,那就可以直接使用了。根据自己的需求,选择冻结和训练哪些参数就可以了。
但是有些时候只是用预训练的模型作为自己模型的一部分,这个时候就需要我们做一些额外的工作了——把预训练模型作为一块积木,搭建我们自己的模型。正如ErnieForSequenceClassification所做的一样。
训练流程
训练流程类似。可以重头自己搭建训练流程,或者使用transformes自带的Trainer接口。
这里直接参考HF的教程即可:Fine-tuning a model with the Trainer API、自己搭建训练流程。