
一、引例
假设有这样一组数据,它们是腰围和体重一一对应的数据对。我们将根据表中的数据对去估计体重。
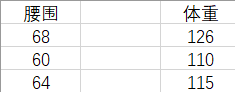
如果现在给出一个新的腰围 62 ,那么体重的估计值是多少呢?
凭经验,我们认为腰围和体重是正相关的,所以我们会自然地『关注』和 62 差距更小的那些腰围,来去估计体重。也就是更加关注表格中腰围是 60 和 64 的『腰围-体重对』(waistline-weight pairs)。即,我们会估计此人的体重在 110 ~ 115 之间。这是一种定性的分析。
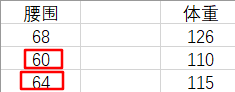
下面我们来算一下具体值。我们选取一种简单直观的方法来计算:
由于 62 距离 60 和 64 的距离是相等的,所以我们取 110 和 115 的平均值作为 62 腰围对应的体重。
\[\frac{110 + 115}{2}=112.5 \]
也可以这样认为,由于 62 距离 60 和 64 是最近的,所以我们更加『注意』它们,又由于 62 到它俩的距离相等,所以我们给这两对『腰围-体重对』各分配 0.5 的权重。
\[0.5\times 110+0.5\times 115=112.5 \]
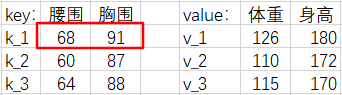
但是,我们到现在还没有用到过 68 –> 126 这个『腰围-体重对』,我们应该再分一些权重给它,让我们的估计结果更准确。
我们上面的讨论可以总结为公式:$$体重估计值=权重1×体重1+权重2×体重2+权重3×体重3$$
这个权重应该如何计算呢?
二、注意力机制
我们把『腰围-体重对』改写成 Python 语法中(字典)的『键-值对』(key-value pairs),把给出的新腰围 62 叫请求(query),简称 \(q\) .
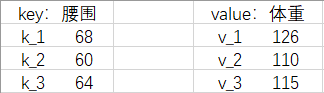
现在我们给那些值起了新的名字,所以公式可以写为:$$f(q)=\alpha (q, k_1)\cdot v_1 + \alpha (q, k_2)\cdot v_2 + \alpha (q, k_3)\cdot v_3=\Sigma _{i=1}^{3}\alpha (q, k_i)\cdot v_i$$
这个公式描述了『注意力机制』。其中,\(f(q)\) 表示注意力机制的输出。 \(\alpha (q, k_i)\) 表示『注意力权重』。它和 \(q\),\(k_i\) 的相似度有关,相似度越高,注意力权重越高。
它是如何计算的呢?方法有很多,在本例中,我们使用高斯核计算:
\[GS(q, k_i)=e^{-\frac{1}{2}(q-k_i)^2} \]
我们取\((-\frac{1}{2}(q-k_i)^2)\)部分进行下一步计算,并把它叫做『注意力分数』。显然,现在这个注意力分数是个绝对值很大的数,没法作为权重使用。所以下面我们要对其进行归一化,把注意力分数转换为 [0, 1] 间的注意力权重(用 \(\alpha (q, k_i)\) 表示)。本例选用 Softmax 进行归一化:
\[\alpha (q, k_i) = \text{Softmax}(-\frac{1}{2}(q-k_i)^2) = \frac{e^{-\frac{1}{2}(q-k_i)^2}}{\Sigma _{i=1}^{3}e^{-\frac{1}{2}(q-k_i)^2}} \]
我们发现,好巧不巧地,\(\alpha (q, k_i)\) 最终又变成高斯核的表达式。
本例中的高斯核计算的相似度为:$$GS(62, 68)= 1.52×10^{-8}$$ $$GS(62, 60)= 0.135$$ $$GS(62, 64)= 0.135$$
\(GS(q, k_1)\) 太小了,我们直接近似为 0 .
注意力权重计算结果为:$$\alpha (62, 68) = 0$$ $$\alpha (62, 60) = 0.5$$ $$\alpha (62, 64) = 0.5$$
体重估计值为:$$f(q) = \alpha (62, 68) \times 126 + \alpha (62, 60) \times 110 + \alpha (62, 64) \times 115 = 112.5$$
三、多维情况
我们现在加入【胸围】和【身高】数据,把 \(q\), \(k\), \(v\) 变成多维的。
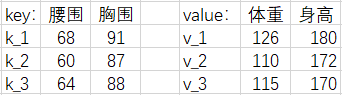
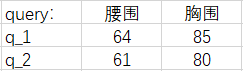
注意力分数 \(\alpha (q_i, k_i)\) 可以用以下模型计算:
| 模型 | 公式 |
|---|---|
| 加性模型 | \(\alpha(q_i, k_i) = \text{softmax}(W_q q_i + W_k k_i + b)\) |
| 点积模型 | \(\alpha(q_i, k_i) = \frac{q_i \cdot k_i}{\sqrt{d}}\) |
| 缩放点积模型 | \(\alpha(q_i, k_i) = \frac{q_i \cdot k_i}{\sqrt{d_k}}\) |
我们以『点积模型』为例,计算一下 \(q_1\),\(k_1\) 的注意力分数 \(\alpha(q_1, k_1)\) 。
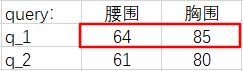
\[q_1=[64, 85] \]
\[k_1^T= \begin{bmatrix} 68 \\ 91 \end{bmatrix} \]
则有
\[\alpha(q_1, k_1) = \text{Softmax}(q_1 k_1^T) = \text{Softmax}(64 \times 68 + 85 \times 91) = \text{Softmax}(12087) \]
其他注意力分数同理。
那么现在,多维情况下的注意力输出 \(f(q)\) 可以表示为下式:
\[f(q)=\Sigma _{i=1}^{3}\alpha (q_i, k_i^T)\cdot v_i = \text{Softmax}(q_i k_i^T)\cdot v_i \]
为了方便计算,我们写成矩阵形式。
\[Q = \begin{bmatrix} 64 & 85 \\ 61 & 80 \\ \end{bmatrix} \]
\[K^T = \begin{bmatrix} 68 & 60 & 64 \\ 91 & 87 & 88 \\ \end{bmatrix} \]
\[V = \begin{bmatrix} 126 & 180 \\ 110 & 172 \\ 115 & 170 \\ \end{bmatrix} \]
\[f(Q)=\text{Softmax}(QK^T)V \]
为了缓解梯度消失的问题,我们还会除以一个特征维度 $ \sqrt{d_k} $ ,即:
\[f(Q)=\text{Softmax}(QK^T/\sqrt{d_k})V \]
这一系列操作,被称为『缩放点积注意力模型』(scaled dot-product attention)
如果 \(Q\), \(K\), \(V\) 是同一个矩阵,会发生什么?
四、自注意力机制
我们用 \(X\) 表示这三个相同的矩阵:
\[X=Q=K=V=\begin{bmatrix} 67 & 91 \\ 60 & 87 \\ 64 & 84 \\ \end{bmatrix}\]
则上述的注意力机制表达式可以写成:
\[f(X)=\text{Softmax}(XX^T/\sqrt{d_k})X \]
这个公式描述了『自注意力机制』(Self-Attention Mechanism)。在实际应用中,可能会对 \(X\) 做不同的线性变换再输入,比如 Transformer 模型。这可能是因为 \(X\) 转换空间后,能更加专注注意力的学习。
三个可学习的权重矩阵 \(W_Q\), \(W_K\), \(W_V\) 可以将输入 \(X\) 投影到查询、键和值的空间。
\[f(X)=\text{Softmax}(XW_Q(XW_K)^T/\sqrt{d_k})XW_V \]
该公式执行以下步骤:
- 使用权重矩阵 \(W_Q\) 和 \(W_K\) 将输入序列 \(X\) 投影到查询空间和键空间,得到 \(XW_Q\) 和 \(XW_K\)。
- 计算自注意力分数:\((XW_Q)(XW_K)^T\),并除以 \(\sqrt{d_k}\) 进行缩放。
- 对自注意力分数进行 Softmax 操作,得到注意力权重。
- 使用权重矩阵 \(W_V\) 将输入序列 \(X\) 投影到值空间,得到 \(XW_V\)。
- 将 Softmax 的结果乘以 \(XW_V\),得到最终的输出。
这个带有权重矩阵的自注意力机制允许模型学习不同位置的查询、键和值的映射关系,从而更灵活地捕捉序列中的信息。在Transformer等模型中,这样的自注意力机制广泛用于提高序列建模的效果。
相关概念推荐阅读:高斯核是什么?,Softmax 函数是什么?
推荐B站视频:注意力机制的本质(BV1dt4y1J7ov),65 注意力分数【动手学深度学习v2】(BV1Tb4y167rb)
