
契子
在实际业务会我们会使用第三方的缓存例如:Reids、Memcache等;但是,并且我们在查询使用缓存时都得尽可能的保证缓存的一致性,在读取时得保证尽可能的保证缓存拿到的是数据库的最新数据,那么在实现的逻辑上一般都为这样:
1、请求线程先读取缓存实现
2、如果缓存没有数据的话触发读取数据库动作
3、将从数据库读取的数据写入缓存
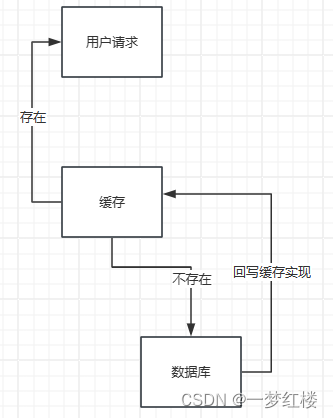
线程安全问题
一般在这里进行缓存加载时都会使用延迟双删的策略来实现缓存的更新,尽可能的避免出现脏缓存的情况。Redis延迟双删:延时双删(redis-mysql)数据一致性思考 – 知乎
那么在用户请求打到服务端的缓存实现时,如果,只是单纯单个用户时那就不用考虑多个线程同时进入缓存策略导致缓存复写性能开销问题;但是,实际业务中肯定会出现多个用户请求同时请求同一ID资源的情况。
出现多个用户请求同一ID资源的情况可能会是这样
1、用户A请求进入缓存A点,并且判断缓存不存在开始读取数据库数据
2、用户B请求进入缓存A点,判断缓存发现缓存也不存在开始读取数据库数据
3、用户A请求读取完数据库数据并且将最新的获取到的数据库数据回写缓存;然后再响应用户端
4、用户B请求读取完数据库数据并且将最新的获取到的数据库数据回写缓存;然后再响应用户端
通过上面的步骤分解我们可以发现3、4点时可能会重复执行,现在举例只是2个请求的情况,试想一下如果实际情况出现很多请求时会不会出现缓存雪崩的情况?缓存雪崩:缓存雪崩产生原因与解决方案 – 知乎
同步锁
看到这里时可能已经想起了单例模式(单例模式 – 知乎)的情况,单例模式也是为了解决多个线程同时调用类变量导致重复创建对象,那么这里同理-多个请求访问导致频繁读取数据库使缓存实现逻辑形同虚设。根据单例模式的情况那我们能不能在这里设计一个同步块或者同步锁呢?很明显也是可以的,我们一起来看下如何实现

Codes
Lock lock = new ReentrantLock();
public List<Resource> getRsource(Long resourceId){
// 查询缓存
List<Resource> resourceEntites = cacheService.findByCacheKey(resourceId);
if(CollectionUtils.isEmpty(resourceEntites)) {
// 加锁
lock.lock();
try {// 如果缓存不存在
// 查询数据库
ResourceEntites = resourceService.findById(resourceId);
// 回写缓存
cacheService.setByCacheKey(resourceId, ResourceEntites);
} finally {
// 释放锁
lock.unlock();
}
}
return resourceEntites;
}如上面代码实现所示使用ReentrantLock所在同步锁,但缓存不存在时会进入查询数据库的逻辑。初看之下逻辑看似并没有什么问,但是,细心的人已经发现问题所在了,首先就是缓存为空判断这里,如果,缓存为空的情况下用户请求的线程会进入数据库代码块,由于同步锁的存在所以此代码块只能同时只能被一个线程所持有,那么后续请求的线程将会阻塞,直到第一次获取到的线程释放锁,那么后续的线程就会被唤醒开始竞争锁;
同步双检锁
这里有各问题就是后续阻塞的线程会进入查询数据库数据的操作,并且也会执行回写缓存的逻辑,因为缓存这里判断已经进入查询数据库的锁机,那么这里也应该与单例模式一样使用双检锁,就是防止后续线程重复执行查询数据库的逻辑。
修改后的代码
Lock lock = new ReentrantLock();
public List<Resource> getRsource(Long resourceId){
// 查询缓存
List<Resource> resourceEntites = cacheService.findByCacheKey(resourceId);
if(CollectionUtils.isEmpty(resourceEntites)) {
// 加锁
lock.lock();
// 再次检查防止阻塞线程复写
if(CollectionUtils.isEmpty(resourceEntites)) {
try {// 如果缓存不存在
// 查询数据库
ResourceEntites = resourceService.findById(resourceId);
// 回写缓存
cacheService.setByCacheKey(resourceId, ResourceEntites);
} finally {
// 释放锁
lock.unlock();
}
}
}
return resourceEntites;
}锁的细粒度问题
写到这里已经解决了多线程下缓存复写的问题了,但是在实际业务中我们缓存可能存在于多个地方并且不同的查询ID获取不同的数据库数据,那么无论是通过同步代码块还是同步锁都是锁住是一块逻辑,在当前这个线程释放前其他任何的线程都无法访问,这时的性能肯定会大大下降,例如:用户A请求的资源ID为1,用户B请求的资源ID为2;用户A线程率先进入同步锁块的代码,此时,用户B请求的线程就被阻塞了;这里从业务逻辑上来说用户B请求的线程不应该被阻塞,因为用户B查询的是资源ID为2的数据,并不会跟用户A线程请求的资源ID为1的数据冲突,但是是通过同步锁时我们无法将锁的细粒度更小化;这时我们就面临着一个问题:如何只锁住当前的资源而不是方法或代码块?
我们应该实现一个可以根据当前的入参的资源ID为据点的同步锁,只有在访问同一ID或资源的时候才会阻塞线程,不同ID的时候还是按照正常情况执行以提高性能;

分段锁
综述以上的情况这里需要引入一个锁概念:分段锁
此锁实现的思路来自于JDK7下的ConcurrentHashMap实现原理,JDK7下的ConcurrentHashMap利用了Fragment的概念来实现的:ConcurrentHashMap并发安全的实现原理~java7_hashmap为什么1.7要用分段锁保证并发-CSDN博客
我们来看代码的实现
**
* 并发分段锁
* 原理是利用ConcurrentHashMap储存锁,ReentrantReadWriteLock实现读共享、写互斥
* 在ReentrantReadWriteLock中存在两种锁的实现,读写和写锁、在多线程数据安全性情况下,读读并行、读写、写读互斥
* 使用读锁可以大幅度提高多线程Read的并发性能,而在,写的情况由于考虑多线程数据安全问题,读锁加锁时会与写锁互斥、写锁加锁时也会与读锁互斥
* 在Jvm中锁的细粒度默认最小只有对象锁、类锁,无论是类锁还是对象锁最小原子性都只能针对某个对象内进行加锁,如果,多个线程根据不同的ID查询不同数据库数据时,如果使用对象锁那么就会导致先来线程先获取锁
* 没有释放锁那么后续的多个线程将会阻塞,但是,从逻辑上来说多个线程只有在查询同一ID时才需要阻塞;这里通过ConcurrentHashMap来存储Lock对象从而达到锁住ID的效果
* 通过ConcurrentHashMap来存储Lock对象,K为当前锁的对象,这里为取K的Hashcode ^ Hashcode >>> 16,高16低16位降低哈希冲突,提高锁的分布
* ConcurrentHashMap本身是通过Cas和Sync來保证多线程下的数据安全,避免链表闭环
* 在Jdk1.8之后ConcurrentHashMap的实现换成Cas和Sync,而在Jdk1.7时使用的则是Segment的数据结构来实现,在1.7中在解决多线程数据安全问题则是通过分段来实现
*
* @Author: Song L.Lu
* @Since: 2023-06-12 14:13
**/
public class ConcurrentReadWriteLock<K> extends ConcurrentHashMap<Integer, ReentrantReadWriteLock> {
public ConcurrentReadWriteLock() {
// 初始化HashMap容量为16
super(16);
}
/**
* 获取读锁
*
* @param k
*/
public void readLock(K k) {
Assert.notNull(k, "Lock key must not be null");
ReentrantReadWriteLock lock = acquireNx(k);
lock.readLock().lock();
}
/**
* 释放读锁
*
* @param k
*/
public void releaseReadLock(K k) {
Assert.notNull(k, "Lock key must not be null");
try {
ReentrantReadWriteLock lock = acquire(k);
if (exists(k))
if (lock.getReadHoldCount() > 0)
lock.readLock().unlock();
} finally {
release(k);
}
}
/**
* 获取写入锁
*
* @param k
*/
public void writeLock(K k) {
Assert.notNull(k, "Lock key must not be null");
ReentrantReadWriteLock lock = acquireNx(k);
lock.writeLock().lock();
}
/**
* 释放写入锁
*
* @param k
*/
public void releaseWriteLock(K k) {
Assert.notNull(k, "Lock key must not be null");
try {
ReentrantReadWriteLock lock = acquire(k);
if (exists(k))
lock.writeLock().unlock();
} finally {
release(k);
}
}
/**
* 尝试从HashMap获取已经存在的所对象
* 如果,所不存在则将创建新的锁放入HashMap
*
* @param k 需要锁住的对象,本质是取的时该对象中的Hashcode
* @return
*/
private ReentrantReadWriteLock acquireNx(K k) {
int hashcode = hashcode(k);
// 尝试从HashMap获取锁对象
ReentrantReadWriteLock lock = get(hashcode);
if (Objects.isNull(lock)) { // 如果没有锁对象则创建一个新的锁对象
try {
// 这里使用ConcurrentHashMap作为锁对象的存储结构,避免,在多线程环境带来的数据安全性问题
putIfAbsent(hashcode, new ReentrantReadWriteLock());
lock = get(hashcode);
} catch (Throwable t) {
release(k); // 避免死锁
}
}
return lock;
}
/**
* 尝试从HashMap获取已经存在的所对象
*
* @param k 需要锁住的对象,本质是取的时该对象中的Hashcode
* @return
*/
private ReentrantReadWriteLock acquire(K k) {
// 尝试从HashMap获取锁对象
int hashcode = hashcode(k);
return get(hashcode);
}
/**
* 释放锁,从HashMap移除该锁
*
* @param k
*/
private void release(K k) {
remove((hashcode(k)));
}
/**
* 锁对象是否存在
*
* @param k
* @return
*/
private boolean exists(K k) {
return containsKey(hashcode(k));
}
/**
* 生产锁对象的Hashcode
* 取出当前对象的Hashcode,通过>>>无符号右移16位,将该对象的Hashcode的高16位和低16位进行或异运算;降低Hash冲突
*
* @param k
* @return
*/
private int hashcode(K k) {
int hashcode = k.hashCode();
return k.hashCode() ^ (hashcode >>> 16);
}
}其原理就是利用Map存储当前的锁实现,Map的K为资源ID,V为同步锁;
结束语
当然这里还是有需要优化的情况,例如:如何维护当前的锁对象,需不需要使用对象池的方式来维护锁?如果使用了对象池那么内存不足是否使用内存淘汰策略来保证对象择优?

