分类模型评估时,scikit-learn提供了混淆矩阵和分类报告是两个非常实用且常用的工具。
它们为我们提供了详细的信息,帮助我们了解模型的优缺点,从而进一步优化模型。
这两个工具之所以单独出来介绍,是因为它们的输出内容特别适合用在模型的评估报告中。
1. 混淆矩阵
混淆矩阵(Confusion Matrix)用于直观地展示模型预测结果与实际标签之间的对应关系。
它是一个表格,其行表示实际的类别标签,而列表示模型预测的类别标签。
通过混淆矩阵,可以清晰地看到模型的哪些预测是正确的,哪些是错误的,以及错误预测的具体分布情况。
1.1. 使用示例
下面用手写数字识别的示例,演示最后如何用混淆矩阵来可视化的评估模型训练结果的。
首先,读取手写数字数据集(这个数据集是scikit-learn中自带的):
import matplotlib.pyplot as plt
from sklearn import datasets
# 加载手写数据集
data = datasets.load_digits()
_, axes = plt.subplots(nrows=2, ncols=4, figsize=(10, 6))
for ax, image, label in zip(np.append(axes[0], axes[1]), data.images, data.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title("目标值: {}".format(label))

然后,用支持向量机来训练数据,得到一个分类模型(reg):
from sklearn.svm import SVC
n_samples = len(data.images)
X = data.images.reshape((n_samples, -1))
y = data.target
# 定义
reg = SVC()
# 训练模型
reg.fit(X, y)
最后,用得到的分类模型来预测数据,再用混淆矩阵来分析预测值和真实值。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 用训练好的模型进行预测
y_pred = reg.predict(X)
cm = confusion_matrix(y, y_pred)
g = ConfusionMatrixDisplay(confusion_matrix=cm)
g.plot()
plt.show()
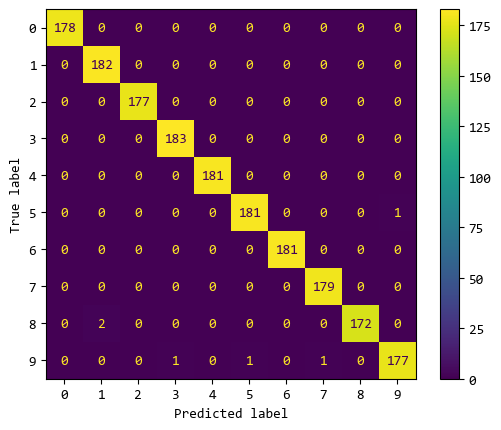
混淆矩阵中,横轴是预测值,纵轴是真实值。
对角线上预测值与真实值符合的情况,可以看出模型分类效果不错,大部分数据都能正确分类的。
也有极个别分类错误的情况,比如:
8被识别成1的错误有2个;5被识别成9的错误有1个;9被识别成3的错误有1个;- … … 等等
2. 分类报告
分类报告提供了模型在各个类别上的详细性能指标。
通常包括准确率(Precision)、召回率(Recall)、F1分数(F1-Score)等评估指标,这些指标能够帮助我们更全面地了解模型的性能。
2.1. 使用示例
基于上面训练的手写数字识别模型,看看模型的各项指标。
from sklearn.metrics import classification_report
# 这里的y 和 y_pred 是上一节示例中的值
report = classification_report(y, y_pred)
print(report)
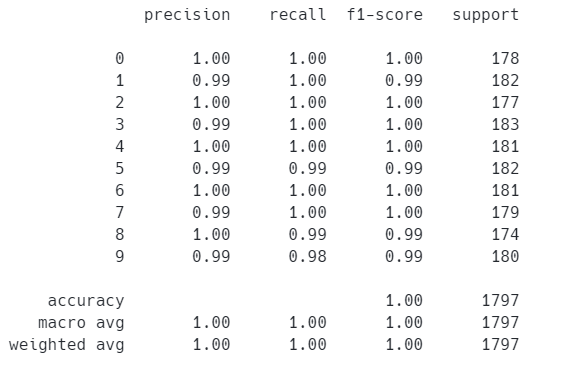
报告中列出了手写数字0~9的识别情况。
3. 总结
总的来说,分类报告与混淆矩阵一起使用,能够更全面地评估模型的性能,指导模型的优化和改进。
而且它们生成的评估表格和图形,也能够应用于我们的分析报告中。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。