英文原文:
https://towardsdatascience.com/robotic-control-with-graph-networks-f1b8d22b8c86

强化学习算法是不是另一种形式的AI4Science?
强化学习是一种时序决策算法,比较经典的应用场景就是机器人控制,但是实际上机器人控制是有两种主流的控制算法的:一类是把机器人控制问题看作是自动控制问题,结合物理规则进行数学建模,这时候的机器人控制问题就被转换为一种类似Scince问题的形式,对机器人下个时序的决策就是在根据建立好的数学模型进行方程式的求解,该种方式最大的优势就是可以获得较为精确的解,但其缺点就是计算复杂并且难以自动化建模,从而难以有较好的适用范围,需要较大的人力投入和较长的周期,对于复杂场景难以应付;另一类则是使用AI方法,也就是机器学习方法中的强化学习算法,这时候不需要对机器人的动力学(dynamic)进行建模,而是采用trial-and-error 的方法通过对环境的不断交互来采集数据并用这些数据训练强化学习算法,该种方法的优点就是不需要人力去对机器人的动力学建模,自动化求解程度高,适用的场景更广,可以解决更复杂的问题,求解周期更短,其缺点就是依赖数据,往往需要较大的数据量,并且有sim2real的问题,并且在real的时候难免要用到真实机器人进行较长时间的真实场景下的数据采样,对真实机器人造成一定损害甚至是损坏,并且求解的往往是近似解,在简单场景下往往自动控制算法的解要优于强化学习算法。
可以看到,如果单纯的只从机器人控制问题出发按照传统自动控制的角度来看,机器人控制其实也可以被视作一种Science问题,而强化学习算法也是在一定程度上起到了对自动控制算法的替代,在如此问题背景的限制下强化学习算法也可以被看做是一种AI4Science算法。
本文主要的讨论是:
https://towardsdatascience.com/robotic-control-with-graph-networks-f1b8d22b8c86
这篇blog中最开始讨论强化学习算法是一种融合进环境动力学(dynamic)的决策方法,解决机器人控制的深度强化学习算法可以看作是一种显示/隐式的拟合环境动力学(dynamic)后的决策算法,而深度强化学习算法所使用的神经网络可以看作是对这个动力学(dynamic)的近似器(approximator)。
既然深度强化学习算法可以被看作是一种基于动力学(dynamic)近似器(approximator),那么就必然存在使用那个类型的神经网络作为近似器(approximator)可以有更好的性能表现(performance)。
由于不同的模型,不同类型的神经网络有着不同bias,因此不同的神经网络对不同的问题有着不同的表现能力,比如:线性分类问题如果使用非线性模型进行拟合是没有使用线性模型拟合的性能表现好的;对于图像分类问题,使用全连接网络是没有使用CNN网络性能表现好的;正如同这些cases一样,对于机器人控制问题如果使用深度强化学习算法的话,使用图神经网络可以提高算法的performance。
给出一个机器人控制的示意图:
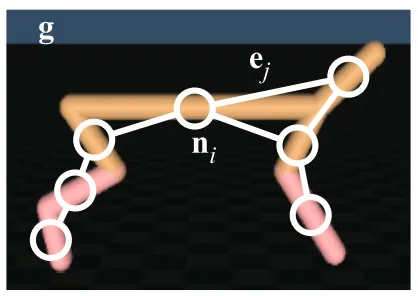
可以看到,在关节型的机器人控制问题上,图网络可以更好的表现机器人关节间的拓扑关系,并且由于图网络更关注的是关节点之间的拓扑关系而不是关节点之间的距离关系,因此机器人的躯干和四肢的长短并不会影响图网络的拓扑关系,因而使用图网络来对关节型机器人的深度强化学习算法做拟合会有更好的泛化性,取得更高的performance。
PS. 要注意,这里之所以可以使用图网络来作为强化学习算法的拟合函数,其原因在于关节型机器人的各关节之间的拓扑关系具有不变性。可以说,用图网络提高机器人控制算法性能是用于在关节型的机器人中的,如果是非关节型的机器人那么也很难适用这里提到的图神经网络的。
相关论文:
Relational inductive biases, deep learning, and graph networks
Graph Networks as Learnable Physics Engines for Inference and Control