
本文将在DialogSum数据集上使用2张T4卡对2.7B的microsoft/phi2进行LORA微调。
博客翻译自Kaggle项目 fine-tuning-llm-for-dialogue-summarization
https://www.kaggle.com/code/aisuko/fine-tuning-llm-for-dialogue-summarization
一、安装依赖
首先,安装依赖包
%%capture
!pip install transformers==4.36.2
!pip install accelerate==0.25.0
!pip install evaluate==0.4.1
!pip install datasets==2.15.0
!pip install peft==0.7.1
!pip install bitsandbytes==0.41.3
# !pip install tqdm==4.66.1
然后,在Kaggle中配置HuggingFace的token以及WeightAndBytes(便于监控模型过程)的token

点击Add-ons的Secrets
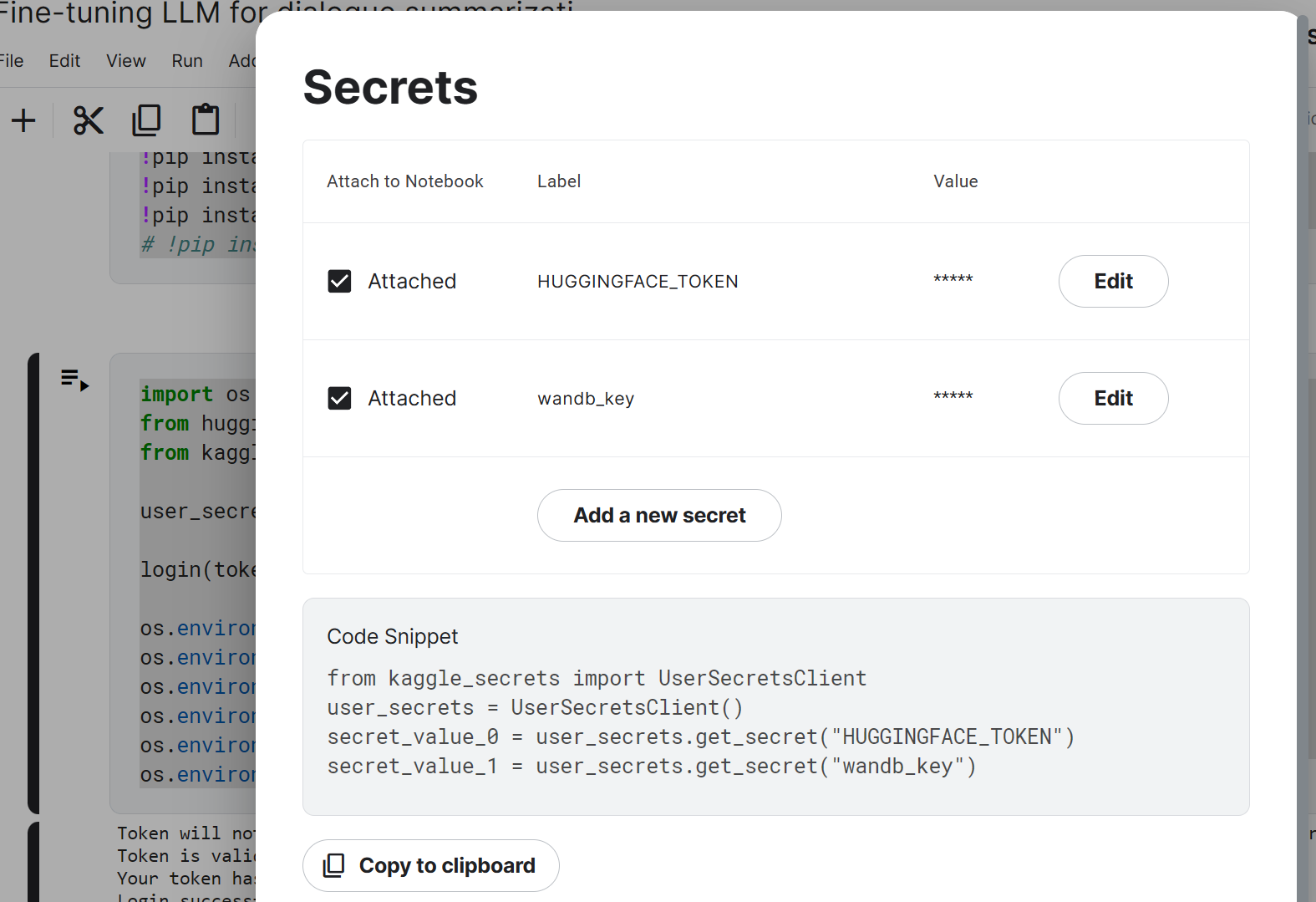
配置自己的相应token
import os
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
login(token=user_secrets.get_secret("HUGGINGFACE_TOKEN"))
os.environ["WANDB_API_KEY"]=user_secrets.get_secret("wandb_key")
# 创建一个Wandb项目,并在下面设立一个任务sft-microsoft-phi2-on-dialogsum
os.environ["WANDB_PROJECT"] = "Supervised-fine-tune-models"
os.environ["WANDB_NOTES"] = "Supervised fine tune models"
os.environ["WANDB_NAME"] = "sft-microsoft-phi2-on-dialogsum"
os.environ["MODEL_NAME"] = "microsoft/phi-2"
os.environ["DATASET_NAME"] = "neil-code/dialogsum-test"
结果
Token will not been saved to git credential helper. Pass `add_to_git_credential=True` if you want to set the git credential as well.
Token is valid (permission: read).
Your token has been saved to /root/.cache/huggingface/token
Login successful
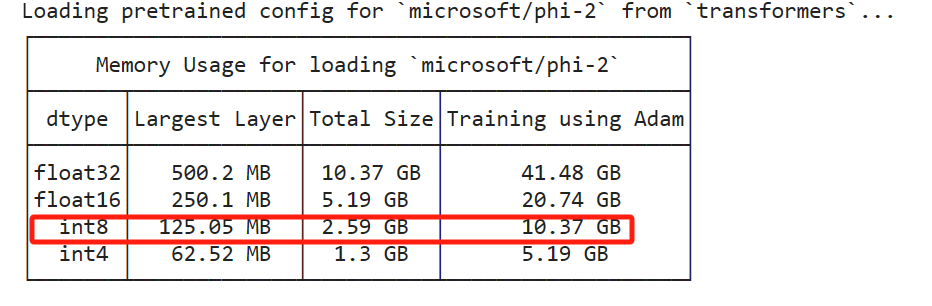
估计微调显存需求
!accelerate estimate-memory microsoft/phi-2 --library_name transformers
二、准备数据
DialogSum是一个包含13,460个人工标注包含摘要和主题的对话摘要数据集。
2.1 dialogsum数据集
使用hugging-face的dataset库加载dialogsum数据集的子集
from datasets import load_dataset
dataset=load_dataset("neil-code/dialogsum-test")
dataset
训练:1999, 验证:499,测试:499
DatasetDict({
train: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 1999
})
validation: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 499
})
test: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 499
})
})
每个样本的字段:[‘id’, ‘dialogue’, ‘summary’, ‘topic’]
样本的内容包含对话正文、摘要以及话题
print(dataset["train"][0])
查看一个样本
{'id': 'train_0',
'dialogue': "#Person1#: Hi, Mr. Smith. I'm Doctor Hawkins. Why are you here today?\n#Person2#: I found it would be a good idea to get a check-up.\n#Person1#: Yes, well, you haven't had one for 5 years. You should have one every year.\n#Person2#: I know. I figure as long as there is nothing wrong, why go see the doctor?\n#Person1#: Well, the best way to avoid serious illnesses is to find out about them early. So try to come at least once a year for your own good.\n#Person2#: Ok.\n#Person1#: Let me see here. Your eyes and ears look fine. Take a deep breath, please. Do you smoke, Mr. Smith?\n#Person2#: Yes.\n#Person1#: Smoking is the leading cause of lung cancer and heart disease, you know. You really should quit.\n#Person2#: I've tried hundreds of times, but I just can't seem to kick the habit.\n#Person1#: Well, we have classes and some medications that might help. I'll give you more information before you leave.\n#Person2#: Ok, thanks doctor.",
'summary': "Mr. Smith's getting a check-up, and Doctor Hawkins advises him to have one every year. Hawkins'll give some information about their classes and medications to help Mr. Smith quit smoking.",
'topic': 'get a check-up'}
可以看到,每轮对话是以#PersonX#开头(代表对话的角色),换行符\n结尾
#Person1#: Hi, Mr. Smith. I'm Doctor Hawkins. Why are you here today?
#Person2#: I found it would be a good idea to get a check-up.
#Person1#: Yes, well, you haven't had one for 5 years. You should have one every year.
#Person2#: I know. I figure as long as there is nothing wrong, why go see the doctor?
#Person1#: Well, the best way to avoid serious illnesses is to find out about them early. So try to come at least once a year for your own good.
#Person2#: Ok.
#Person1#: Let me see here. Your eyes and ears look fine. Take a deep breath, please. Do you smoke, Mr. Smith?
#Person2#: Yes.
#Person1#: Smoking is the leading cause of lung cancer and heart disease, you know. You really should quit.
#Person2#: I've tried hundreds of times, but I just can't seem to kick the habit.
#Person1#: Well, we have classes and some medications that might help. I'll give you more information before you leave.
#Person2#: Ok, thanks doctor.
[可选项] 减少数据规模
为了在有限的计算资源上进行微调,可以减少数据的规模
smaller_training=dataset['train'].select(range(100))
smaller_validation=dataset['validation'].select(range(80))
smaller_test=dataset['test'].select(range(80))
dataset['train']=smaller_training
dataset['validation']=smaller_validation
dataset['test']=smaller_test
在这里,我将微调的训练集从1999降到了100,验证和测试为80
dataset
查看数据
DatasetDict({
train: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 100
})
validation: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 80
})
test: Dataset({
features: ['id', 'dialogue', 'summary', 'topic'],
num_rows: 80
})
})
2.2 加载分词器tokenizer
from transformers import AutoTokenizer
# see https://github.com/huggingface/transformers/issues/18388 for description about padding
tokenizer=AutoTokenizer.from_pretrained(
'microsoft/phi-2',
padding_side='left',
add_eos_token=True,
add_bos_token=True,
use_fast=False
)
tokenizer.pad_token=tokenizer.eos_token
导入DataCollatorForLanguageModeling
使用序列结束token作为padding token,并将mlm设置为False。这将使用输入作为向右移动一个元素的标签:
from transformers import DataCollatorForLanguageModeling
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
DataCollatorForLanguageModeling能高效地将dataset(即train_dataset或eval_dataset中的样本)中一批样本转化输入格式,而且能在batch层面按最长序列进行dynamically padding
DataCollatorForLanguageModeling继承自DataCollatorMixin(根据输入return_tensors的类型,决定调用处理哪种类型矩阵torch、tensorflow、numpy的方法)
- mlm设为False (为True是做BERT的掩词预训练)
- 主要使用_torch_collate_batch来构造batch样本输入
@dataclass
class DataCollatorForLanguageModeling(DataCollatorMixin):
"""
Data collator used for language modeling. Inputs are dynamically padded to the maximum length of a batch if they are not all of the same length.
Args:
tokenizer ([`PreTrainedTokenizer`] or [`PreTrainedTokenizerFast`]):
The tokenizer used for encoding the data.
mlm (`bool`, *optional*, defaults to `True`):
Whether or not to use masked language modeling. If set to `False`, the labels are the same as the inputs
with the padding tokens ignored (by setting them to -100). Otherwise, the labels are -100 for non-masked
tokens and the value to predict for the masked token.
mlm_probability (`float`, *optional*, defaults to 0.15):
The probability with which to (randomly) mask tokens in the input, when `mlm` is set to `True`.
pad_to_multiple_of (`int`, *optional*):
If set will pad the sequence to a multiple of the provided value.
return_tensors (`str`):
The type of Tensor to return. Allowable values are "np", "pt" and "tf".
<Tip>
For best performance, this data collator should be used with a dataset having items that are dictionaries or
BatchEncoding, with the `"special_tokens_mask"` key, as returned by a [`PreTrainedTokenizer`] or a
[`PreTrainedTokenizerFast`] with the argument `return_special_tokens_mask=True`.
</Tip>"""
tokenizer: PreTrainedTokenizerBase
mlm: bool = True
mlm_probability: float = 0.15
pad_to_multiple_of: Optional[int] = None
tf_experimental_compile: bool = False
return_tensors: str = "pt"
def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]:
# Handle dict or lists with proper padding and conversion to tensor.
if isinstance(examples[0], Mapping):
batch = pad_without_fast_tokenizer_warning(
self.tokenizer, examples, return_tensors="pt", pad_to_multiple_of=self.pad_to_multiple_of
)
else:
batch = {
"input_ids": _torch_collate_batch(examples, self.tokenizer, pad_to_multiple_of=self.pad_to_multiple_of)
}
# If special token mask has been preprocessed, pop it from the dict.
special_tokens_mask = batch.pop("special_tokens_mask", None)
if self.mlm:
batch["input_ids"], batch["labels"] = self.torch_mask_tokens(
batch["input_ids"], special_tokens_mask=special_tokens_mask
)
else:
labels = batch["input_ids"].clone()
if self.tokenizer.pad_token_id is not None:
labels[labels == self.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
def _torch_collate_batch(examples, tokenizer, pad_to_multiple_of: Optional[int] = None):
"""Collate `examples` into a batch, using the information in `tokenizer` for padding if necessary."""
import torch
# Tensorize if necessary.
if isinstance(examples[0], (list, tuple, np.ndarray)):
examples = [torch.tensor(e, dtype=torch.long) for e in examples]
length_of_first = examples[0].size(0)
# Check if padding is necessary.
are_tensors_same_length = all(x.size(0) == length_of_first for x in examples)
if are_tensors_same_length and (pad_to_multiple_of is None or length_of_first % pad_to_multiple_of == 0):
return torch.stack(examples, dim=0)
# If yes, check if we have a `pad_token`.
if tokenizer._pad_token is None:
raise ValueError(
"You are attempting to pad samples but the tokenizer you are using"
f" ({tokenizer.__class__.__name__}) does not have a pad token."
)
# Creating the full tensor and filling it with our data.
max_length = max(x.size(0) for x in examples)
if pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
result = examples[0].new_full([len(examples), max_length], tokenizer.pad_token_id)
for i, example in enumerate(examples):
if tokenizer.padding_side == "right":
result[i, : example.shape[0]] = example
else:
result[i, -example.shape[0] :] = example
return result
测试一下
from transformers import DataCollatorForLanguageModeling
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
features = [tokenizer('实事求是'), tokenizer('没有调查就没发言权')]
print(data_collator(features))
{'input_ids': tensor([[50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 22522, 252, 12859, 233, 162, 109, 224, 42468], [50256, 162, 110, 94, 17312, 231, 164, 108, 225, 162, 253, 98, 22887, 109, 162, 110, 94, 20998, 239, 164, 101, 222, 30266, 225]]),
'attention_mask': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
'labels': tensor([[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 22522, 252, 12859, 233, 162, 109, 224, 42468], [-100, 162, 110, 94, 17312, 231, 164, 108, 225, 162, 253, 98, 22887, 109, 162, 110, 94, 20998, 239, 164, 101, 222, 30266, 225]])}
可以看到,两个样本进行了token化并padding构成了一个batch(在序列左边padding了50256 token,相应label变成-100)
2.2 处理数据
我们需要创建一些预处理函数来格式化输入数据集,确保其适合微调过程。
在这里,我们将对话摘要(提示-回应)对转换为LLM(大型语言模型)的明确指令。
from functools import partial
from transformers import set_seed
seed=42
set_seed(seed)
def create_prompt_formats(sample):
"""构造微调的prompt格式: ('instruction','output')"""
INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
INSTRUCTION_KEY = "### Instruct: Summarize the below conversation."
RESPONSE_KEY = "### Output:"
END_KEY = "### End"
blurb = f"\n{INTRO_BLURB}"
instruction = f"{INSTRUCTION_KEY}"
input_context = f"{sample['dialogue']}" if sample["dialogue"] else None
response = f"{RESPONSE_KEY}\n{sample['summary']}"
end = f"{END_KEY}"
parts = [part for part in [blurb, instruction, input_context, response, end] if part]
formatted_prompt = "\n\n".join(parts)
sample["text"] = formatted_prompt
return sample
# 获取模型的上下文长度
def get_max_length(model):
conf = model.config
max_length = None
for length_setting in ["n_positions", "max_position_embeddings", "seq_length"]:
max_length = getattr(model.config, length_setting, None)
if max_length:
print(f"Found max lenth: {max_length}")
break
if not max_length:
max_length = 1024
print(f"Using default max length: {max_length}")
return max_length
# 预处理batch样本(分词后,按最大长度截断token序列并构造成batch)
def preprocess_batch(batch, tokenizer, max_length):
""" Tokenizing a batch """
return tokenizer(batch["text"], max_length=max_length, truncation=True)
# SOURCE https://github.com/databrickslabs/dolly/blob/master/training/trainer.py
def preprocess_dataset(tokenizer: AutoTokenizer, max_length: int,seed, dataset):
"""Format & tokenize it so it is ready for training
:param tokenizer (AutoTokenizer): Model Tokenizer
:param max_length (int): Maximum number of tokens to emit from tokenizer
"""
# 对每一个样本添加prompt
print("Preprocessing dataset...")
dataset = dataset.map(create_prompt_formats)#, batched=True)
# 对dataset中的每一个batch进行preprocess_batch预处理,然后移除'instruction', 'context', 'response', 'category'字段
_preprocessing_function = partial(preprocess_batch, max_length=max_length, tokenizer=tokenizer)
dataset = dataset.map(
_preprocessing_function,
batched=True,
remove_columns=['id', 'topic', 'dialogue', 'summary'],
)
# 保留input_ids短于max_length的样本
dataset = dataset.filter(lambda sample: len(sample["input_ids"]) < max_length)
dataset = dataset.shuffle(seed=seed)
return dataset
数据集处理
train_dataset = preprocess_dataset(tokenizer, max_length, seed, dataset['train'])
eval_dataset = preprocess_dataset(tokenizer, max_length, seed, dataset['validation'])
train_dataset
三、训练
3.1 加载模型
使用QLora量化模型减少微调所需的显存要求。
bitsandbytes设置经验法则是:
- 如果内存有限制,使用double_quant
- 使用NF4以获得更高的精度
- 使用16 bit float加快微调速度
import torch
from transformers import BitsAndBytesConfig, AutoModelForCausalLM
# 设置bitsandbytes参数,参考官方文章:https://zhuanlan.zhihu.com/p/665601576
# 使用NF4量化加载 4bit模型的示例 (以4bit存储权重)
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True, # 使用了两轮量化
bnb_4bit_compute_type=torch.float16, # 计算时使用16bit
llm_int8_enable_fp32_cpu_offload=True
)
model=AutoModelForCausalLM.from_pretrained(
'microsoft/phi-2',
device_map='auto',
quantization_config=bnb_config,
# Solving the issue: ValueError: PhiForCausalLM does not support `device_map='auto'`. To implement support, the model class needs to implement the `_no_split_modules` attribute.
trust_remote_code=True,
# attn_implementation="flash_attention_2", # Does not be supported in here
torch_dtype=torch.float16
)
模型参数在5.5G左右
model.safetensors.index.json: 100%
35.7k/35.7k [00:00<00:00, 2.46MB/s]
Downloading shards: 100%
2/2 [00:23<00:00, 10.09s/it]
model-00001-of-00002.safetensors: 100%
5.00G/5.00G [00:20<00:00, 249MB/s]
model-00002-of-00002.safetensors: 100%
564M/564M [00:02<00:00, 240MB/s]
Loading checkpoint shards: 100%
2/2 [00:00<00:00, 2.39it/s]
generation_config.json: 100%
124/124 [00:00<00:00, 9.46kB/s]
adapter_config.json: 100%
617/617 [00:00<00:00, 39.0kB/s]
model.config.quantization_config
Loading widget...
BitsAndBytesConfig {
"bnb_4bit_compute_dtype": "float32",
"bnb_4bit_quant_type": "nf4",
"bnb_4bit_use_double_quant": true,
"llm_int8_enable_fp32_cpu_offload": true,
"llm_int8_has_fp16_weight": false,
"llm_int8_skip_modules": null,
"llm_int8_threshold": 6.0,
"load_in_4bit": true,
"load_in_8bit": false,
"quant_method": "bitsandbytes"
}
查看模型上下文最大长度
max_length=get_max_length(model)
Found max lenth: 2048
通过 prepare_model_for_kbit_training(model)方法让量化模型变成可lora训练
from peft import prepare_model_for_kbit_trainin
# save memory
model.gradient_checkpointing_enable()
model=prepare_model_for_kbit_training(model, use_gradient_checkpointing=True)
model
模型结构
PhiForCausalLM(
(model): PhiModel(
(embed_tokens): Embedding(51200, 2560)
(embed_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-31): 32 x PhiDecoderLayer(
(self_attn): PhiAttention(
(q_proj): Linear4bit(in_features=2560, out_features=2560, bias=True)
(k_proj): Linear4bit(in_features=2560, out_features=2560, bias=True)
(v_proj): Linear4bit(in_features=2560, out_features=2560, bias=True)
(dense): Linear4bit(in_features=2560, out_features=2560, bias=True)
(rotary_emb): PhiRotaryEmbedding()
)
(mlp): PhiMLP(
(activation_fn): NewGELUActivation()
(fc1): Linear4bit(in_features=2560, out_features=10240, bias=True)
(fc2): Linear4bit(in_features=10240, out_features=2560, bias=True)
)
(input_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
)
(final_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2560, out_features=51200, bias=True)
)
from peft import LoraConfig, TaskType, get_peft_model
# lora的秩设为16
# 微调参数设为:PhiAttention的QKV的投影矩阵和dense,以及PhiMLP的两层前馈神经网络参数
peft_config=LoraConfig(
r=16,
lora_alpha=32,
target_modules=[
'q_proj',
'k_proj',
'v_proj',
'dense',
'fc1',
'fc2',
],
bias="none",
lora_dropout=0.05,
task_type=TaskType.CAUSAL_LM
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()
查看微调可训练参数
trainable params: 23,592,960 || all params: 2,803,276,800 || trainable%: 0.8416207775129448
使用Trainer进行训练
import time
from transformers import TrainingArguments, Trainer
training_args=TrainingArguments(
output_dir=os.getenv("WANDB_NAME"),
overwrite_output_dir=True,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=5,
gradient_checkpointing=True, # 启用gradient checkpointing
gradient_checkpointing_kwargs={"use_reentrant": False},
warmup_steps=50,
max_steps=100, # Total number of training steps
num_train_epochs=2, # 训练epoch数量
learning_rate=5e-5, # 学习率
weight_decay=0.01, # AdamW的权重衰减系数,等价于L2正则
optim="paged_adamw_8bit", # Keep the optimizer state and quantize it
# bf16=True, # Do not supported in Kaggle environment, require Ampere....
fp16=True, # use fp16 16bit(mixed) precision training instead of 32-bit training.
logging_dir='./logs',
logging_strategy="steps",
logging_steps=10,
save_strategy="steps",
save_steps=100,
save_total_limit=2, # Limit the total number of checkpoints
do_eval=True,
evaluation_strategy="steps",
eval_steps=50,
load_best_model_at_end=True, # Load the best model at the end of training,
report_to="wandb",
run_name=os.getenv("WANDB_NAME")
)
peft_model.config.use_cache=False
trainer=Trainer(
model=peft_model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator # 在dataset上构造batch样本
)
start_time=time.time()
trainer.train()
end_time=time.time()
training_time=end_time-start_time
print(f"Training completed in {training_time} seconds.")
训练状态(2张T4 GPU进行训练,大概各占用10GB)
-------------------------------[100/100 20:52, Epoch 10/10]
Step Training Loss Validation Loss
50 1.409500 1.382088
100 1.281700 1.351633
Training completed in 1266.7061877250671 seconds.
注: 这里只是大致跑通流程,训练好的lora模型可以按需上传到wandb中
四、评估
清除变量,释放显存
import gc
del model,peft_model, tokenizer, trainer
gc.collect()
torch.cuda.empty_cache()
加载tokenizer
eval_tokenizer=AutoTokenizer.from_pretrained(
'aisuko/'+os.getenv('WANDB_NAME'),
add_bos_token=True,
trust_remote_code=True,
use_fast=False
)
eval_tokenizer.pad_token=eval_tokenizer.eos_token
print(eval_tokenizer)
加载训练好的Lora参数并合并到模型中
from peft import PeftModel
model=AutoModelForCausalLM.from_pretrained(
os.getenv('MODEL_NAME'),
device_map='auto',
trust_remote_code=True,
torch_dtype=torch.float16
)
eval_model=PeftModel.from_pretrained(
model, 'aisuko/'+os.getenv('WANDB_NAME'), device_map='auto'
)
使用model.generate的模型推理预测代码
ef inference(model, prompt, max_length=200):
tokens=eval_tokenizer(prompt, return_tensors='pt')
res=model.generate(
**tokens.to('cuda'),
max_new_tokens=max_length,
do_sample=True,
num_return_sequences=1,
temperature=0.1,
num_beams=1,
top_p=0.95
)
return eval_tokenizer.batch_decode(res, skip_special_tokens=False)
对话摘要推理代码
dialogue=dataset['test'][5]['dialogue']
summary=dataset['test'][5]['summary']
prompt=f'Instruct: Summarize the following conversation.\n{dialogue}\nOutput:\n'
peft_model_res=inference(eval_model, prompt, 100)
peft_model_output=peft_model_res[0].split('Output:\n')[1]
prefix, success, result=peft_model_output.partition('###')
dashline='-'.join('' for x in range(100))
print(prompt)
print(dashline)
例子1
Instruct: Summarize the following conversation.
#Person1#: You're finally here! What took so long?
#Person2#: I got stuck in traffic again. There was a terrible traffic jam near the Carrefour intersection.
#Person1#: It's always rather congested down there during rush hour. Maybe you should try to find a different route to get home.
#Person2#: I don't think it can be avoided, to be honest.
#Person1#: perhaps it would be better if you started taking public transport system to work.
#Person2#: I think it's something that I'll have to consider. The public transport system is pretty good.
#Person1#: It would be better for the environment, too.
#Person2#: I know. I feel bad about how much my car is adding to the pollution problem in this city.
#Person1#: Taking the subway would be a lot less stressful than driving as well.
#Person2#: The only problem is that I'm going to really miss having the freedom that you have with a car.
#Person1#: Well, when it's nicer outside, you can start biking to work. That will give you just as much freedom as your car usually provides.
#Person2#: That's true. I could certainly use the exercise!
#Person1#: So, are you going to quit driving to work then?
#Person2#: Yes, it's not good for me or for the environment.
Output:
---------------------------------------------------------------------------------------------------
查看原始标注结果
print(summary)
#Person2# complains to #Person1# about the traffic jam, #Person1# suggests quitting driving and taking public transportation instead.
查看微调模型的预测结果
#Person2# tells #Person1# that they got stuck in traffic again and that it's always congested near the Carrefour intersection during rush hour. #Person1# suggests that #Person2# should consider taking public transport system to work, and #Person2# agrees that it would be better for the environment. #Person1# also suggests that #Person2# could start biking to work when it's nicer outside. #Person2# decides to quit driving to work.
例子2
Instruct: Summarize the following conversation.
#Person1#: Ms. Dawson, I need you to take a dictation for me.
#Person2#: Yes, sir...
#Person1#: This should go out as an intra-office memorandum to all employees by this afternoon. Are you ready?
#Person2#: Yes, sir. Go ahead.
#Person1#: Attention all staff... Effective immediately, all office communications are restricted to email correspondence and official memos. The use of Instant Message programs by employees during working hours is strictly prohibited.
#Person2#: Sir, does this apply to intra-office communications only? Or will it also restrict external communications?
#Person1#: It should apply to all communications, not only in this office between employees, but also any outside communications.
#Person2#: But sir, many employees use Instant Messaging to communicate with their clients.
#Person1#: They will just have to change their communication methods. I don't want any - one using Instant Messaging in this office. It wastes too much time! Now, please continue with the memo. Where were we?
#Person2#: This applies to internal and external communications.
#Person1#: Yes. Any employee who persists in using Instant Messaging will first receive a warning and be placed on probation. At second offense, the employee will face termination. Any questions regarding this new policy may be directed to department heads.
#Person2#: Is that all?
#Person1#: Yes. Please get this memo typed up and distributed to all employees before 4 pm.
Output:
这种对话摘要的问题依然是各种幻觉,例如无中生有、篡改原文等,PEFT或直接使用prompt大概只能修改输出格式。
小参数的LLM微调的好处在于,显存需求少、部署难度低,而且相比T5-pegasus这种架构,直接用prompt就可以初步使用,当然最终要达到业务目标肯定还有很大的提升空间:
- 不仅要对输入进行清洗过滤,
- 还要更换更强的底座,加大样本,甚至全参数微调
- Lora调参【2】【3】或魔改(例如LoraMOE等)
相关资料
- 1、利用phi进行NL2SQL:https://medium.aiplanet.com/fine-tune-small-model-micphi-2-to-convert-natural-language-to-sql-32fc4f6ed40c
- 2、LORA调参总结:Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments:https://lightning.ai/pages/community/lora-insights/
- 3、配置不同的学习率,LoRA还能再涨一点?:https://spaces.ac.cn/archives/10001
