
在pandas使用的过程中我们会发现有两个函数的功能有很多相似之处。它们就是get_dummies()和factorize(),它们功能上都是对分类变量进行操作。那么get_dummies()和factorize()有什么区别呢?接下来的这篇文章告诉你。
1.get_dummies()
pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None,sparse=False, drop_first=False):Convert categorical variable into dummy/indicator variables
>>> import pandas as pd
>>> s = pd.Series(list('abca'))
>>> pd.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 02.pd.factorize()
pandas.factorize(values, sort=False, order=None, na_sentinel=-1,size_hint=None):Encode input values as an enumerated type or categorical variable
Series.factorize(sort=False, na_sentinel=-1):Encode the object as an enumerated type or categorical variable
Pandas有一个方法叫做factorize(),它可以创建一些数字,来表示类别变量,对每一个类别映射一个ID,这种映射最后只生成一个特征,不像dummy那样生成多个特征。
| Parameters: |
sort : boolean, default False
na_sentinel: int, default -1
|
|---|---|
| Returns: |
labels : the indexer to the original array uniques : the unique Index |
labels:对应的编码array
uniques:需要编码的类型
补充:pandas.get_dummies 的使用及含义
get_dummies 是利用pandas实现one hot encode的方式
get_dummies参数如下:
pandas.get_dummies(data,prefix = None,prefix_sep =’_’,dummy_na = False,columns = None,sparse = False,drop_first = False,dtype = None )
data : array-like,Series或DataFrame
prefix :string,字符串列表或字符串dict,默认为None,
用于追加DataFrame列名的字符串。在DataFrame上调用get_dummies时,传递一个长度等于列数的列表。或者,前缀 可以是将列名称映射到前缀的字典。
prefix_sep : string,默认为’_’
如果附加前缀,分隔符/分隔符要使用。或者传递与前缀一样的列表或字典。
dummy_na : bool,默认为False
如果忽略False NaN,则添加一列以指示NaN。
columns : 类似列表,默认为无
要编码的DataFrame中的列名称。如果列是None,那么所有与列 对象或类别 D型细胞将被转换。
sparse : bool,默认为False
伪编码列是否应由SparseArray(True)或常规NumPy数组(False)支持。
drop_first : bool,默认为False
是否通过删除第一级别从k分类级别获得k-1个假人。
版本0.18.0中的新功能。
dtype: D型,默认np.uint8
新列的数据类型。只允许一个dtype。
版本0.23.0中的新功能。
实例
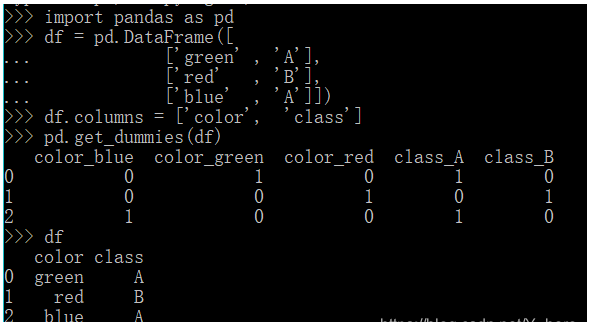
prefix自定义前缀

以上就是get_dummies()和factorize()有什么区别的全部内容,希望能给大家一个参考,也希望大家多多支持W3Cschool。
