
预先准备
本笔记为参加DataWhale的线上学习——进行GLM、SD部署
在完成驱动云平台注册后,免费获得168算力金,使用免费算力金进行ai平台部署
在平台内进行部署
https://platform.virtaicloud.com/
项目服务器配置
创建项目后,选择添加镜像
在此选择PyTorch 2.0.1 Conda 3.9的镜像
通过选择官方已配置好的镜像可以直接省去不必要的环境安装问题
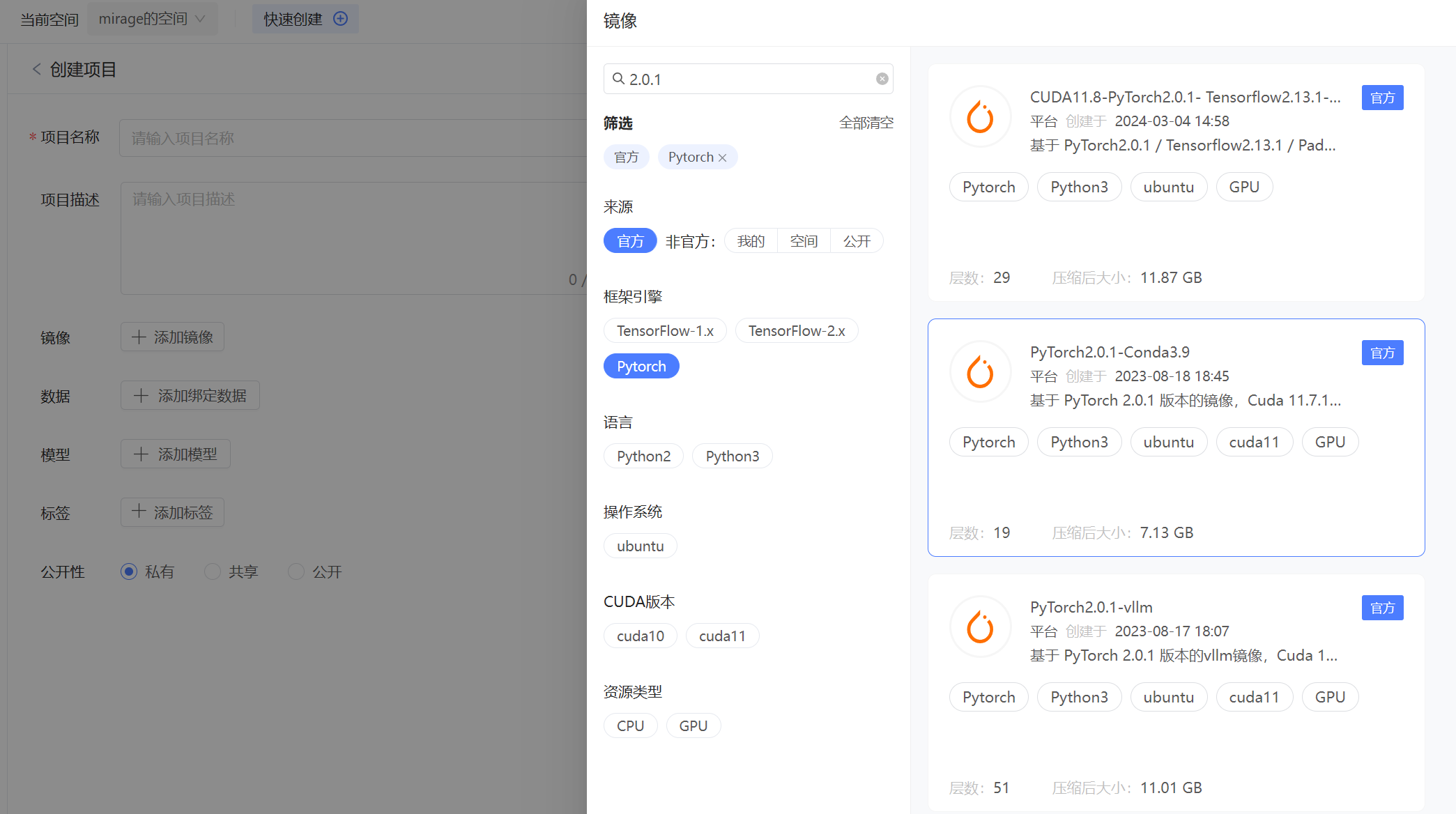
其次选择模型,选择了公开的ChatGLM3-6B模型,获得了预处理好的模型
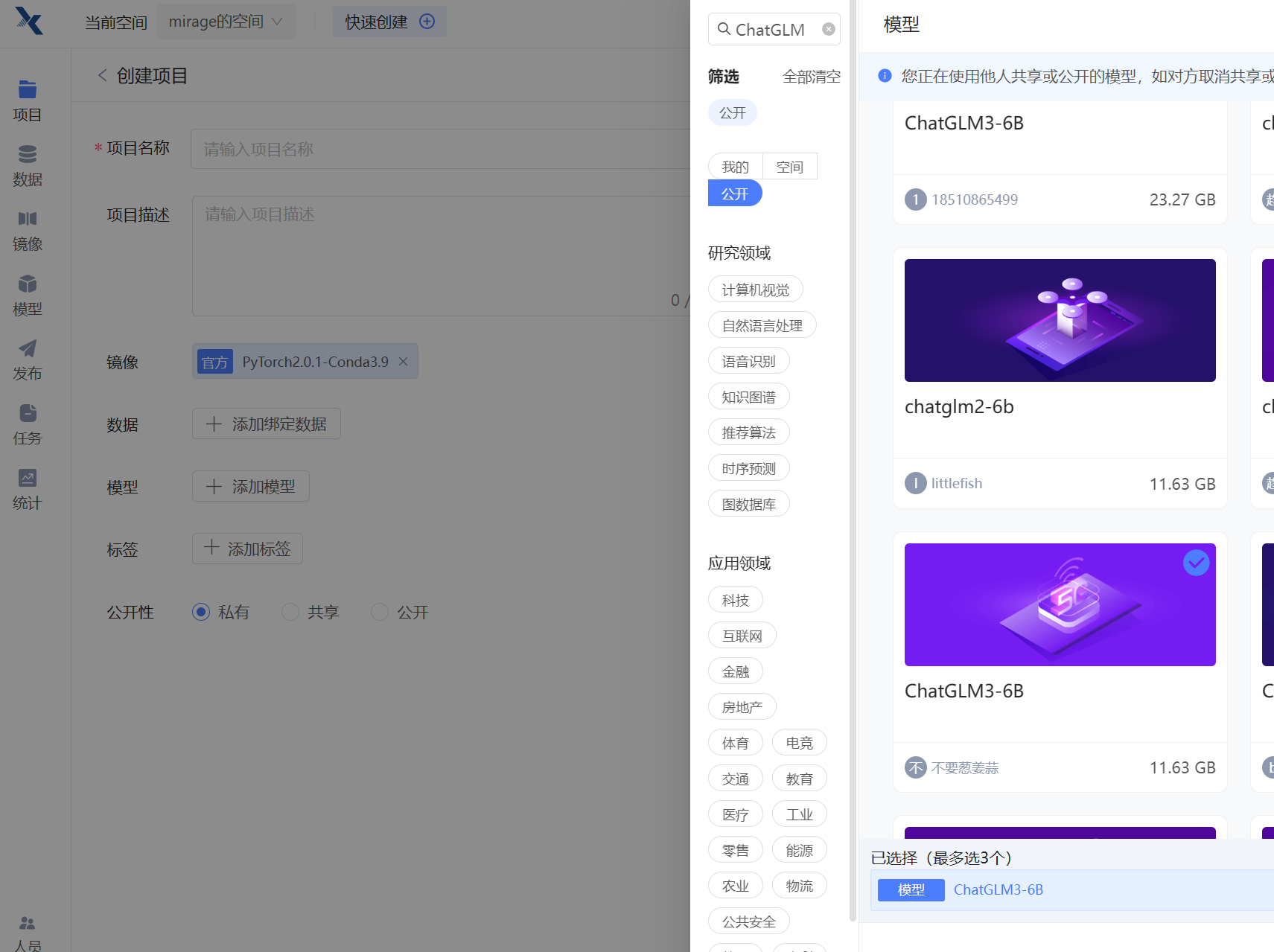
在此之后,选择运行代码,再选择自身的配置
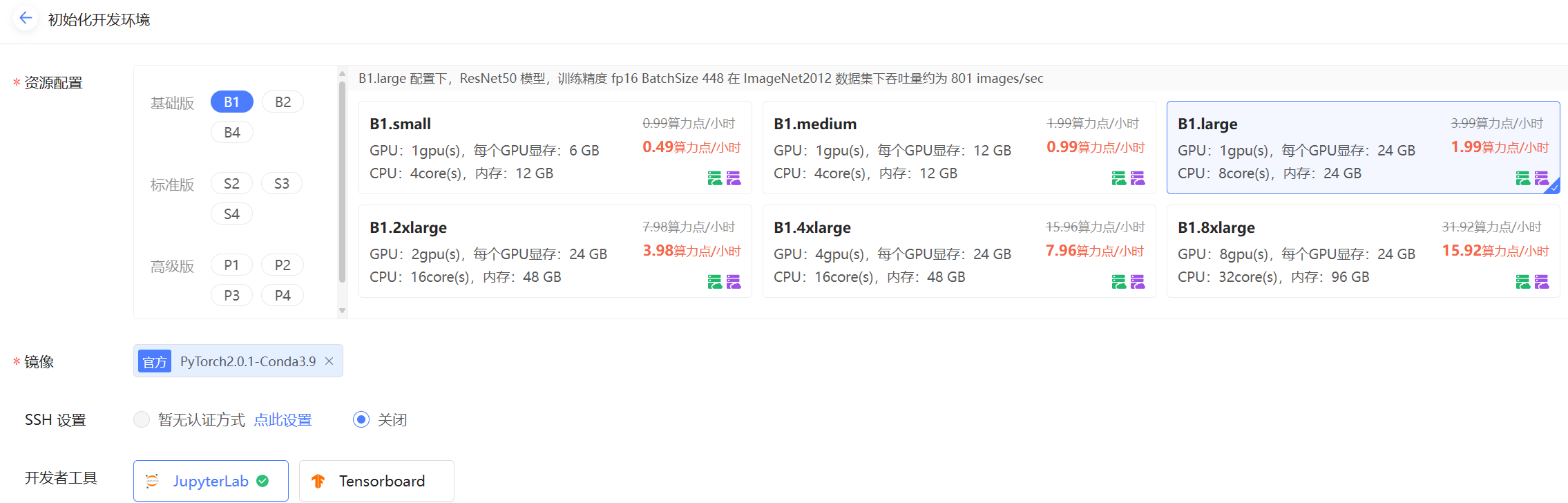
此前我也了解过python,电脑算力,CPU、GPU,但是这个价格对比和上述的比喻,确实非常直观的给了我针对算力的认识
而再创建好配置并运行后,就能开始进行内部环境的配置
内部环境配置
在项目内部,打开终端,进行环境配置
实话说环境配置一直是计算机的一大问题,为了一个项目的运行需要确定各式各样的环境,确认各种各样的依赖项,同时还要做出兼容性的适配工作,幸好在本项目重torch与conda已经获得,大大减少了环境安装的困难
但是仍然需要安装一定必要的内容
1. 安装并更新unzip,为后续解压进行准备
apt-get update && apt-get install unzip
2. 设置镜像源并更新pip,方便后续gitclone项目与下载依赖项
git config --global url."https://gitclone.com/".insteadOf https://
pip config set global.index-url https://pypi.virtaicloud.com/repository/pypi/simple
python3 -m pip install --upgrade pip
3. 克隆项目并进入
git clone https://github.com/THUDM/ChatGLM3.git
cd ChatGLM3
这一步不知道是我前面镜像源输入错误,还是网络在我配置的时候出现了问题,反复出现网络连接失败的问题,提示github连接不上,而我在纯终端上查看配置的指令不够熟练,最终也没去查证
但是最后重新建立一个项目后,问题得到解决了
4. 修改requirements
这是一步减少不必要操作的一项
在requirements中存放了所有python需要的依赖库
其实我头一次通过requirements进行库一键下载,先前我见到大项目时以为requirements是给人参考python环境,指导安装,第一次使用指令一键下载
pip install -r requirements.txt
pip install peft
其次还额外安装了一个peft包,好像是一个用于大模型参数微调fine-tuning的包
修改python代码并运行
1. 修改web_demo_gradio内的设定
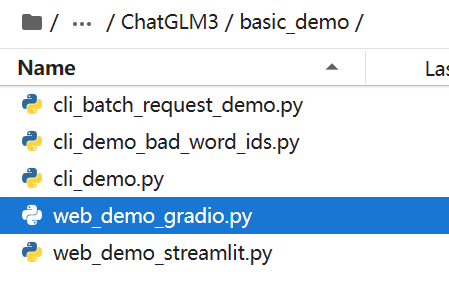
文件夹内的文件名与参考教程的不大统一,可能是由于ChatGLM在近期的github上进行了修改,无妨,找到对应需要修改的地方进行改正


修改了加载模型的路径,与最终模型运行的方式
主要是由于在本项目内模型存放的相对位置,与最终运行的端口发生了改变
2. 添加项目的外部端口
为了能从本地进行模型的访问,还要在项目进行端口设置
按道理来讲,我们其实是先需要设置端口,在对上面运行方式进行修改,填上我们申请端口的port与name
3. 运行gradio界面
cd basic_demo
python web_demo_gradio.py
将位置切换到basic_demo目录并运行py代码
最后运行gradio项目,从外部进行访问,这次部署任务就圆满完成了
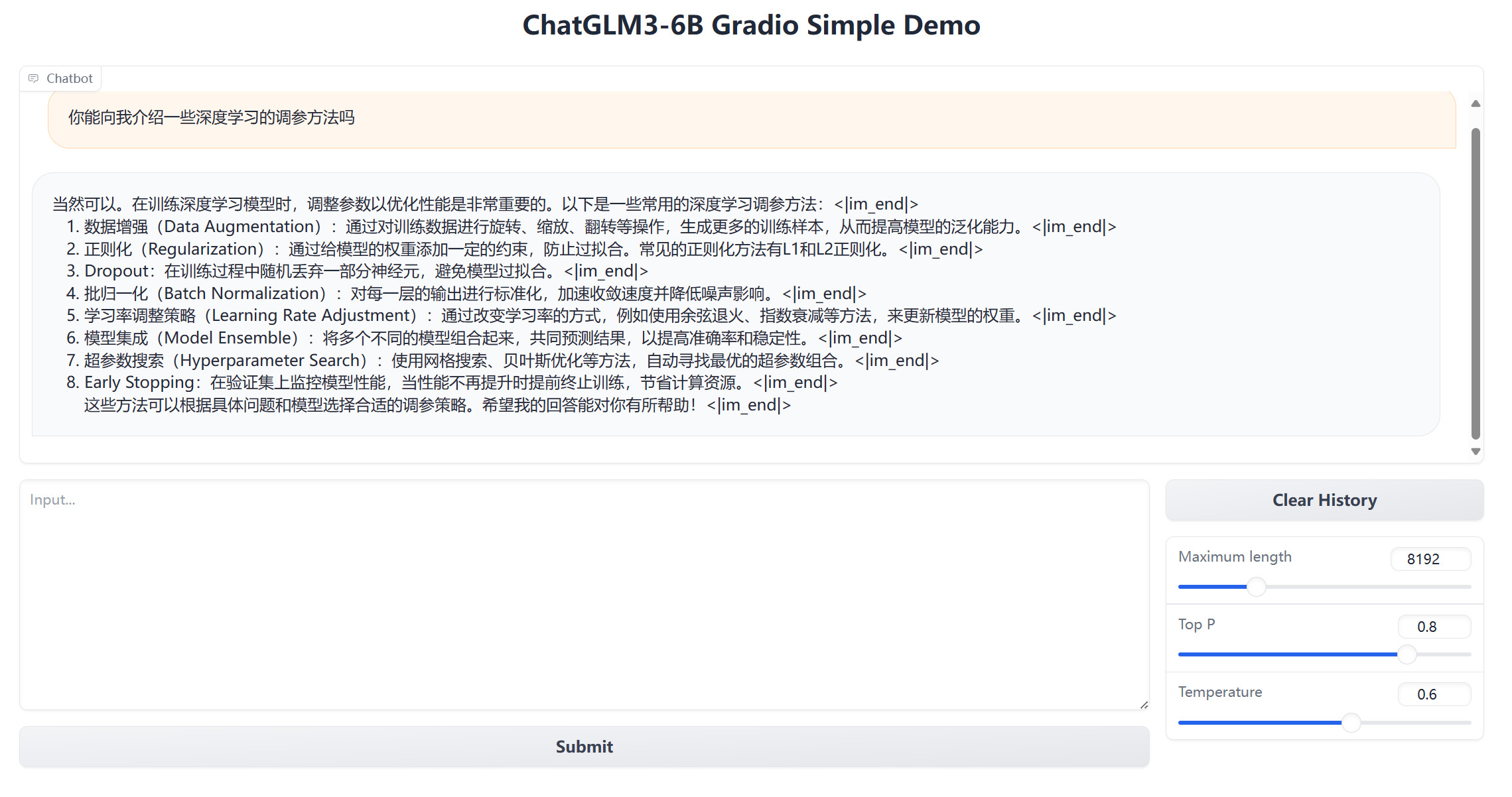
在其中还可以进行一些内容的微调,想必之前引入peft包就是为此吧
streamlit
其次还有流平台方式的ChatGLM,修改与运行区别不大,只是要指定端口
这个端口好像没在py文件内定义
streamlit run web_demo_streamlit.py --server.port 7000
这里就不再赘述其他内容了
总结
这一次学习还是毕竟轻松愉快的,内容简单,我熟悉python,熟悉命令行指令,也熟悉一些模型相关的知识,修改内容也不难
有一种轻松涨知识的感觉,浅尝了一下部署模型的内容,后续还会更新部署SD,和自己选的ai部署,再学几天

