
在处理大量数据时,有必要将具有特征的空间压缩为向量。一个例子是文本嵌入,它是几乎所有 NLP 模型创建过程中不可或缺的一部分。不幸的是,使用神经网络处理这种类型的数据远非总是可能的——例如,原因可能是拟合或推理率低。
下面是我提出一种有趣的方法来使用,这个方法就是很少有人知道的梯度提升。
数据资料
在最近一项有关于卡格尔的比赛结束了,在那里展示了一个包含文本数据的小数据集。我决定将这些数据用于实验,因为比赛表明数据集标记得很好,而且我没有遇到任何令人不快的意外。
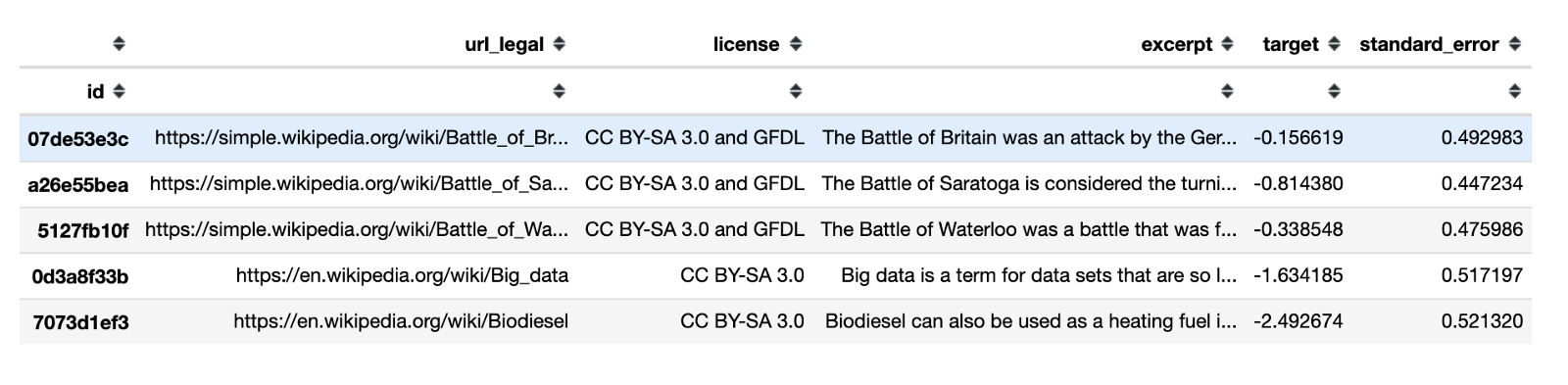
列:
- id – 摘录的唯一 ID
- url_legal – 来源网址
- license – 源材料许可
- excerpt – 预测阅读难易度的文本
- target – 更容易理解
- standard_error -测量每个摘录的多个评分员之间的分数分布
作为数据集中的目标,它是一个数值变量,提出解决回归问题。但是,我决定用分类问题代替它。主要原因是我将使用的库不支持在回归问题中处理文本和嵌入。我希望开发者在未来能够消除这个不足。但无论如何,回归和分类的问题是密切相关的,对于分析来说,解决哪个问题没有区别。
让我们通过 Sturge 规则计算 bin 的数量:
num_bins = int(np.floor(1 + np.log2(len(train))))train['target_q'], bin_edges = pd.qcut(train['target'],
q=num_bins, labels=False, retbins=True, precision=0)
但是,首先,我清理数据。
train['license'] = train['license'].fillna('nan')
train['license'] = train['license'].astype('category').cat.codes在一个小的自写函数的帮助下,我对文本进行了清理和词形还原。函数可能很复杂,但这对于我的实验来说已经足够了。
def clean_text(text):
table = text.maketrans(
dict.fromkeys(string.punctuation))
words = word_tokenize(
text.lower().strip().translate(table))
words = [word for word in words if word not in
stopwords.words ('english')] lemmed = [WordNetLemmatizer().lemmatize(word) for word in words]
return " ".join(lemmed)我将清理后的文本另存为新功能。
train['clean_excerpt'] = train['excerpt'].apply(clean_text)除了文本之外,我还可以选择 URL 中的单个单词并将这些数据转换为新的文本功能。
def getWordsFromURL(url):
return re.compile(r'[\:/?=\-&.]+',re.UNICODE).split(url)train['url_legal'] = train['url_legal'].fillna("nan").apply(getWordsFromURL).apply(
lambda x: " ".join(x))我从文本中创建了几个新特征——这些是各种统计信息。同样,有很大的创造力空间,但这些数据对我们来说已经足够了。这些功能的主要目的是对基线模型有用。
def get_sentence_lengths(text):
tokened = sent_tokenize(text) lengths
= []
for idx,i in enumerate(tokened):
splited = list(i.split(" "))
lengths.append(len(splited))
return (max (长度),
min(lengths),
round(mean(lengths), 3))def create_features(df):
df_f = pd.DataFrame(index=df.index)
df_f['text_len'] = df['excerpt'].apply(len)
df_f['text_clean_len']= df['clean_excerpt']。 apply(len)
df_f['text_len_div'] = df_f['text_clean_len'] / df_f['text_len']
df_f['text_word_count'] = df['clean_excerpt'].apply(
lambda x : len(x.split(') ')))
df_f[['max_len_sent','min_len_sent','avg_len_sent']] = \
df_f.apply(
lambda x: get_sentence_lengths(x['excerpt']),
axis=1, result_type='expand')
return df_ftrain = pd.concat(
[train, create_features(train)], axis=1, copy=False, sort=False)basic_f_columns = [
'text_len'、'text_clean_len'、'text_len_div'、'text_word_count'、
'max_len_sent'、'min_len_sent'、'avg_len_sent']当数据稀缺时,很难检验假设,结果通常也不稳定。因此,为了对结果更有信心,我更喜欢在这种情况下使用 OOF(Out-of-Fold)预测。
基线
我选择Catboost作为模型的免费库。Catboost 是一个高性能的开源库,用于决策树上的梯度提升。从 0.19.1 版开始,它支持开箱即用的 GPU 分类文本功能。主要优点是 CatBoost 可以在您的数据中包含分类函数和文本函数,而无需额外的预处理。
在非常规情绪分析:BERT 与 Catboost 中,我扩展了 Catboost 如何处理文本并将其与 BERT 进行了比较。
这个库有一个杀手锏:它知道如何使用嵌入。不幸的是,目前,文档中对此一无所知,很少有人知道 Catboost 的这个优势。
!pip install catboost使用 Catboost 时,我建议使用 Pool。它是一个方便的包装器,结合了特征、标签和进一步的元数据,如分类和文本特征。
为了比较实验,我创建了一个仅使用数值和分类特征的基线模型。
我写了一个函数来初始化和训练模型。顺便说一下,我没有选择最佳参数。
def fit_model_classifier(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
task_type='GPU',
iterations=5000,
eval_metric='AUC',
od_type='Iter',
od_wait=500,
l2_leaf_reg=10,
bootstrap_type='Bernoulli ',
subsample=0.7,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=100,
plot=False,
use_best_model=True)对于OOF的实现,我写了一个小而简单的函数。
def get_oof_classifier(
n_folds, x_train, y, embedding_features,
cat_features, text_features, tpo, seeds,
num_bins, emb=None, tolist=True):
ntrain = x_train.shape[0]
oof_train = np.zeros((len(seeds), ntrain, num_bins))
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (tr_i, t_i) in enumerate(kf.split(x_train, y)):
if emb and len(emb) > 0:
x_tr = pd.concat(
[x_train.iloc[tr_i, :],
get_embeddings(
x_train.iloc[tr_i, :], emb, tolist)],
axis=1, copy=False, sort=False)
x_te = pd.concat(
[x_train.iloc[t_i, :],
get_embeddings(
x_train.iloc[t_i, :], emb, tolist)],
axis=1, copy=False, sort=False)
columns = [
x for x in x_tr if (x not in ['excerpt'])]
if not embedding_features:
for c in emb:
columns.remove(c)
else:
x_tr = x_train.iloc[tr_i, :]
x_te = x_train.iloc[t_i, :]
columns = [
x for x in x_tr if (x not in ['excerpt'])]
x_tr = x_tr[columns]
x_te = x_te[columns]
y_tr = y[tr_i]
y_te = y[t_i]
train_pool = Pool(
data=x_tr,
label=y_tr,
cat_features=cat_features,
embedding_features=embedding_features,
text_features=text_features)
valid_pool = Pool(
data=x_te,
label=y_te,
cat_features=cat_features,
embedding_features=embedding_features,
text_features=text_features)
model = fit_model_classifier(
train_pool, valid_pool,
random_seed=seed,
text_processing=tpo
)
oof_train[iseed, t_i, :] = \
model.predict_proba(valid_pool)
models[(seed, i)] = model
oof_train = oof_train.mean(axis=0)
return oof_train, models我将在下面写关于get_embeddings函数,但它现在不用于获取模型的基线。
我使用以下参数训练了基线模型:
columns = ['license', 'url_legal'] + basic_f_columns
oof_train_cb, models_cb = get_oof_classifier( n_folds=5, x_train=train[columns], y=train['target_q'].values, embedding_features=None, cat_features=['license'], text_features=['url_legal'], tpo=tpo, seeds=[0, 42, 888], num_bins=num_bins )
训练模型的质量:
roc_auc_score(train['target_q'], oof_train_cb, multi_class="ovo")AUC:0.684407现在我有了模型质量的基准。从数字来看,这个模型很弱,我不会在生产中实现它。
嵌入
您可以将多维向量转换为嵌入,这是一个相对低维的空间。因此,嵌入简化了大型输入的机器学习,例如表示单词的稀疏向量。理想情况下,嵌入通过在嵌入空间中将语义相似的输入彼此靠近放置来捕获一些输入语义。
有很多方法可以获得这样的向量,我在本文中不考虑它们,因为这不是研究的目的。但是,以任何方式获得嵌入对我来说就足够了;最重要的是他们保存了必要的信息。在大多数情况下,我使用目前流行的方法——预训练的 Transformer。
from sentence_transformers import SentenceTransformerSTRANSFORMERS = {
'sentence-transformers/paraphrase-mpnet-base-v2': ('mpnet', 768),
'sentence-transformers/bert-base-wikipedia-sections-mean-tokens': ('wikipedia', 768)
}def get_encode(df, encoder, name):
device = torch.device(
"cuda:0" if torch.cuda.is_available() else "cpu")
model = SentenceTransformer(
encoder,
cache_folder=f'./hf_{name} /'
)
model.to(device)
model.eval()
return np.array(model.encode(df['excerpt']))def get_embeddings(df, emb=None, tolist=True): ret = pd.DataFrame(index=df.index) for e, s in STRANSFORMERS.items(): if emb and s[0] not in emb: continue ret[s[0]] = list(get_encode(df, e, s[0])) if tolist: ret = pd.concat( [ret, pd.DataFrame( ret[s[0]].tolist(), columns=[f'{s[0]}_{x}' for x in range(s[1])], index=ret.index)], axis=1, copy=False, sort=False) return ret
现在我有了开始测试不同版本模型的一切。
楷模
我有几种拟合模型的选项:
- 文字特征;
- 嵌入特征;
- 嵌入特征,如分离的数字特征列表。
我一直在训练这些选项的各种组合,这使我能够得出嵌入可能有多有用的结论,或者,这可能只是一种过度设计。
例如,我给出了一个使用所有三个选项的代码:
columns = ['license', 'url_legal', 'clean_excerpt', 'excerpt'] oof_train_cb, models_cb = get_oof_classifier(
n_folds=FOLDS,
x_train=train[columns],
y=train['target_q'].values,
embedding_features=['mpnet', 'wikipedia'],
cat_features=['license'],
text_features= ['clean_excerpt','url_legal'],
tpo=tpo, seed
=[0, 42, 888],
num_bins=num_bins,
emb=['mpnet', 'wikipedia'],
tolist=True
)有关更多信息,我在 GPU 和 CPU 上训练了模型;并将结果汇总在一张表中。
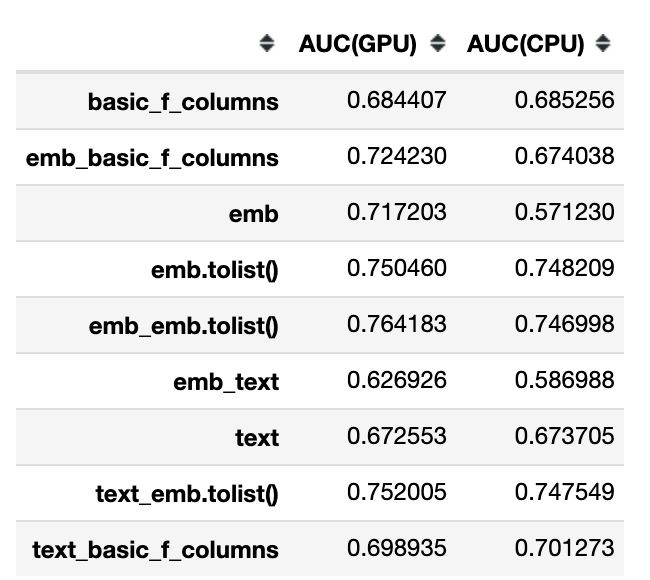
令我震惊的第一件事是文本特征和嵌入的极差交互。不幸的是,我对这个事实还没有任何合乎逻辑的解释——在这里,需要在其他数据集上对这个问题进行更详细的研究。同时,请注意,将文本和嵌入用于同一文本的组合使用会降低模型的质量。
对我来说另一个启示是在 CPU 上训练模式时嵌入不起作用。
现在是一件好事——如果你有一个 GPU 并且可以获得嵌入,那么最好的质量是当你同时使用嵌入作为一个特征和一个单独的数字特征列表时。
总结
在这篇文章中,我:
- 选择了一个小的免费数据集进行测试;
- 为文本数据创建了几个统计特征,以使用它们来创建基线模型;
- 测试了嵌入、文本和简单特征的各种组合;
- 得到了一些不明显的见解。
