
一、前言
ConcurrentHashMap相比于HashMap是线程安全的,大概可以理解为:插入元素一定会成功,删除元素也一定会成功,查找元素也不会出问题。
二、数据结构

如上图所示,有如下数据元素
1,segments数组
Segment对象数组,默认长度16,可以指定长度,最大长度限制为65536,指定长度后不能修改。
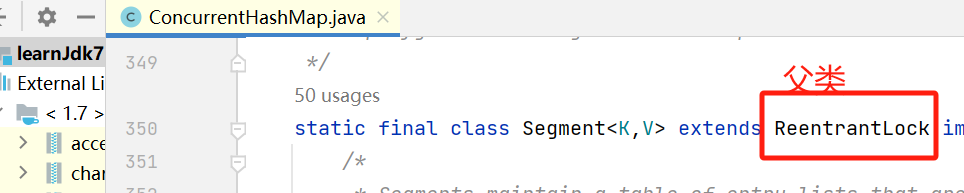
2,sync锁
来自于Segment对象继承的父类ReentrantLock对象中的元素,为非公平锁。
3,table数组
和HashMap中桶数组类似,每个桶位储存一条元素链表;table数组长度可以扩容。
三、使用原理
1,概述
ConcurrentHashMap对象中持有一个Segment对象的数组,每一个Segment对象中又持有一个节点(链表)对象的数组,节点对象为一个单向链表的头部元素,插入ConcurrentHashMap的元素就储存在这些链表中。向ConcurrentHashMap中put()元素时,先在segments数组中找对应Segment对象的位置,再在table数组中找到对应链表的位置,最后将元素和该链表进行链接。ConcurrentHashMap相比于HashMap,“类似于”将一个HashMap对象分裂为多个HashMap对象,每个对象又被Segment对象重新包装,分布储存于segments数组中。这样做的目的是为了线程安全,HashTable是在每个方法上加了synchronized,等于锁了整张表,ConcurrentHashMap只锁了Segment对象。比如一家早餐店,有5个顾客,HashTable等于只开了一个窗口,但是ConcurrentHashMap开了多个窗口,同样是线程安全,效率不一样。
2,put()方法流程
2.1,初始化锁
构造ConcurrentHashMap对象时,会初始化segments数组,并初始化数组的第一个元素segments[0];
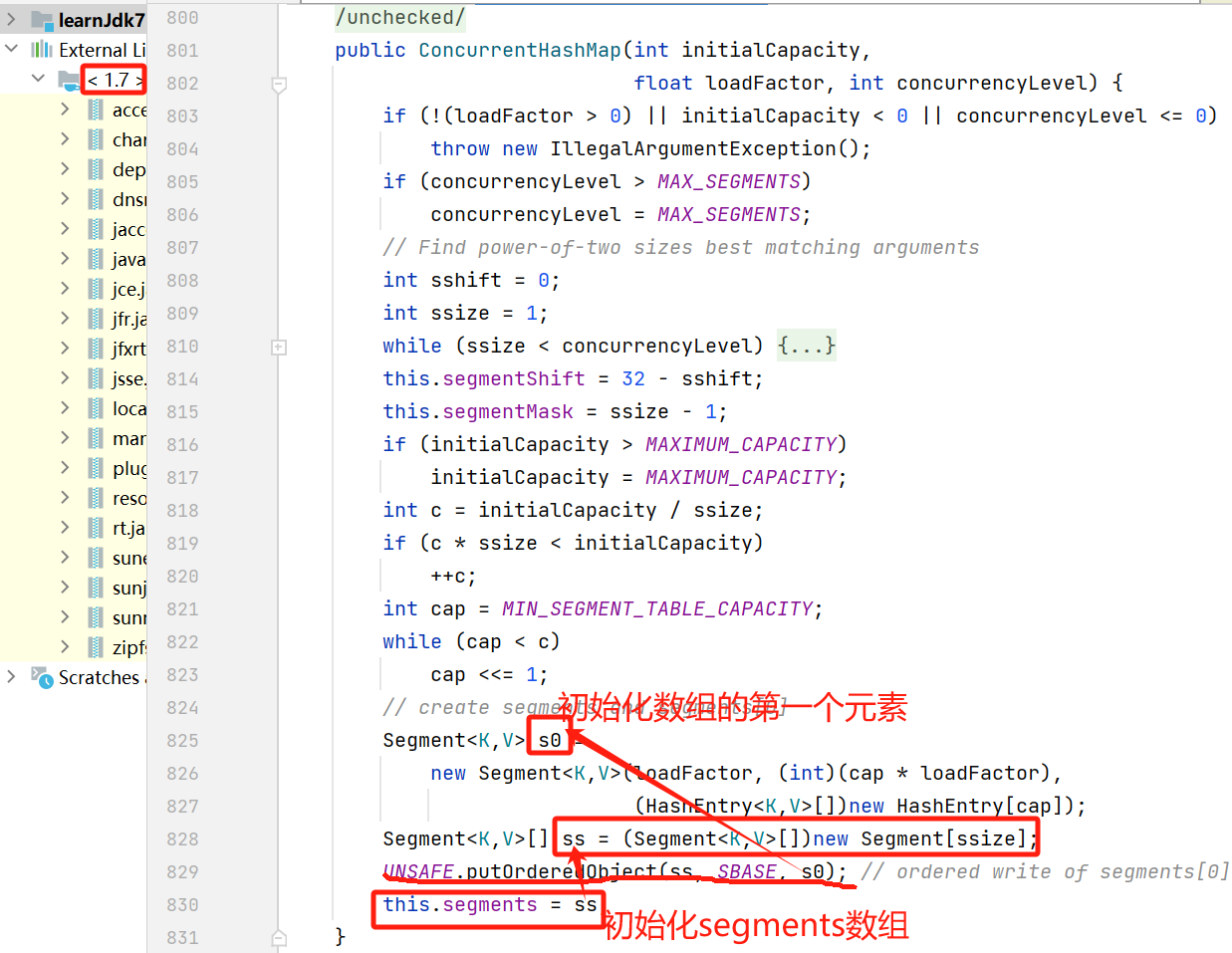
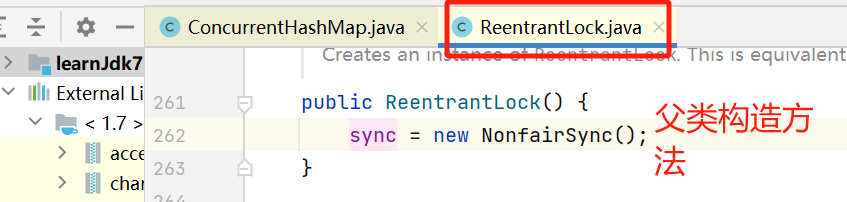
构建Segment对象时,会先执行父类的构造方法,初始化锁对象;
segments数组其他位置的初始化,是在需要向该位置插入元素时进行;
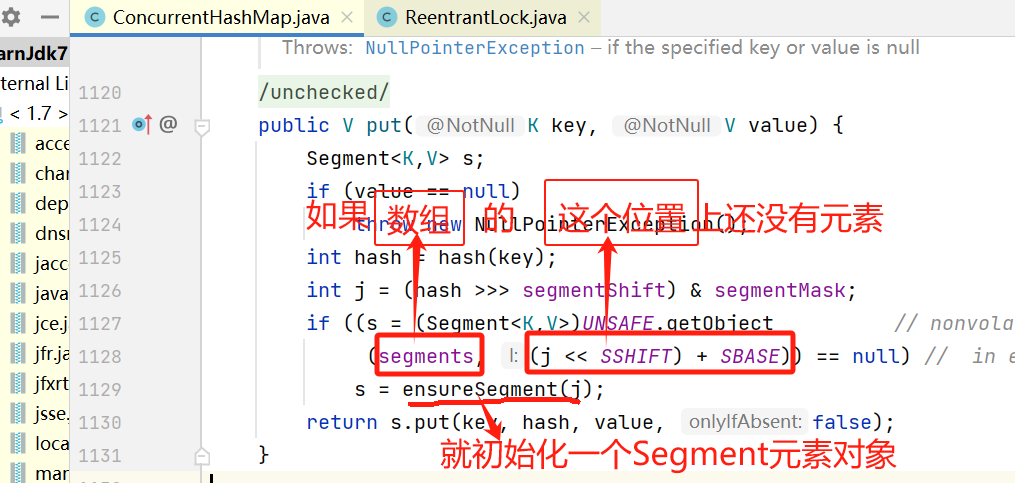

2.2,获取锁
2.2.1,整体流程
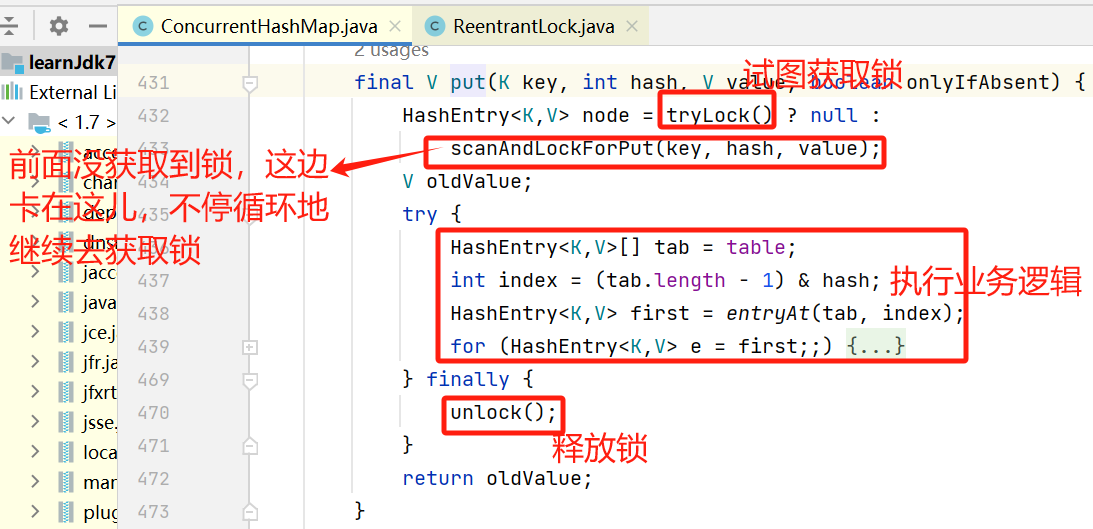
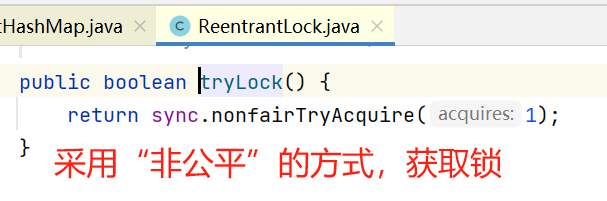
2.2.2,tryLock()
a,CAS简介
CAS:compare and swap;
CAS(0, 1),0是“期望值”,1是“替换值”;
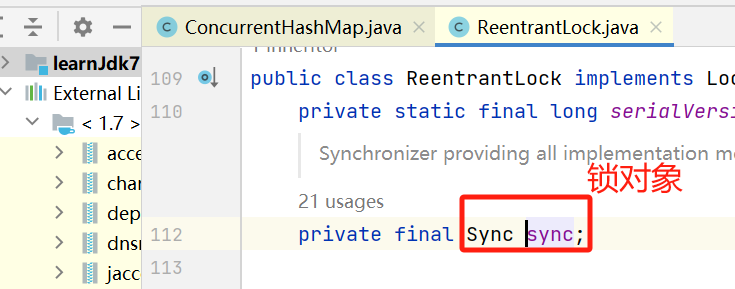
CAS的当前值:以此处为例,ConcurrentHashMap对象中有某一个Segment对象,Segment对象初始化(执行构造方法)时又先初始化了父类ReentrantLock对象,构造了一个NonfairSync对象,NonfairSync对象初始化时又初始化了父类AbstractQueuedSynchronizer对象,即最终每一个Segment对象都对应含有一个AbstractQueuedSynchronizer对象,AbstractQueuedSynchronizer对象则储存了“当前值”;
使用时,如果“当前值”和“期望值”一致,都是0,则修改“当前值”为“替换值”1,并返回true;否则什么也不干,返回false;
网上说CAS是一个原子操作,即读取“当前值”、比较“当前值”和“期望值”、替换“当前值”为“替换值”打包成了一个原子操作。参考:【多线程】cas_多核cpu cas-CSDN博客;里面有说CAS底层是一条cpu指令,即lock cmpxchg,单核的时候自然在一个时刻只能执行一个指令,多核也没问题,因为cpu对lock指令有特殊处理,会锁住总线。
b,tryLock()方法简介
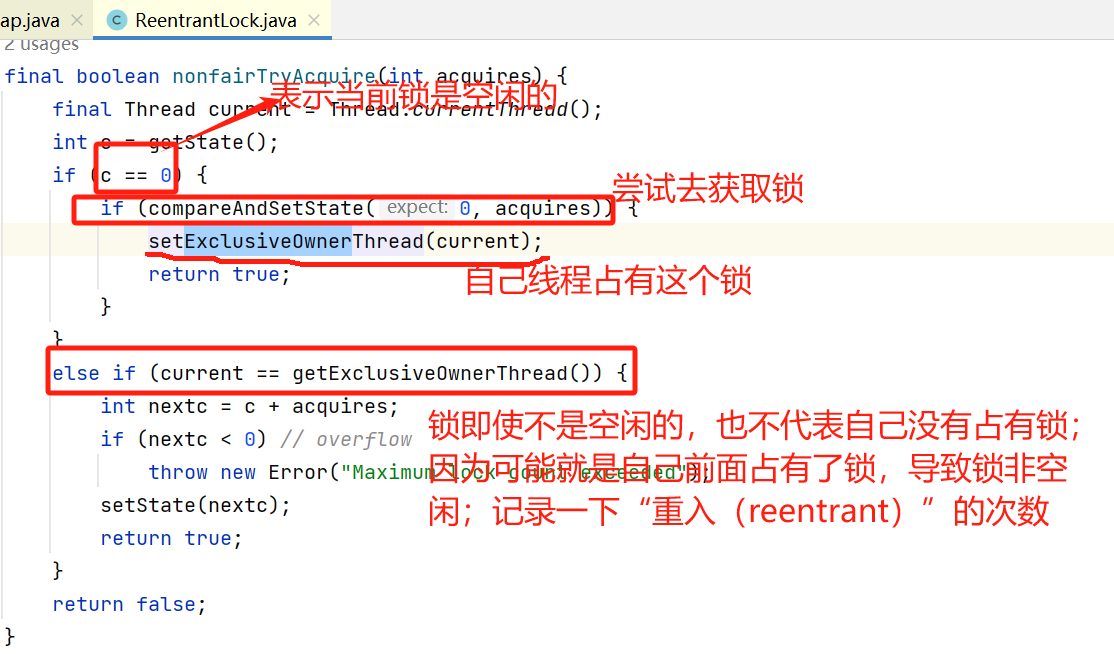
采用了非公平的方式获取锁,如上图
1,获取锁的状态state,state=0表示空闲,state=其他表示占用;
2,如果state=0,则自己CAS;CAS成功了,则占有锁,返回true;CAS失败了,返回false;
3,如果state != 0,则判断是否是自己之前占用了锁,即判断重入的情况;是重入的话,设置重入次数,也返回true;不是重入的话,返回false。
c,公平锁和非公平锁
公平锁:获取不到锁就排队,阻塞等待;
非公平锁:获取不到锁就拉倒;可通过不停的去获取,以达到目的;
公平锁的吞吐量不行,说是因为多个线程排队,加重了操作系统对线程的调度压力;非公平锁没这个问题,不需要排队,就线程自个儿管好自个儿就行了。
2.2.3,scanAndLockForPut()
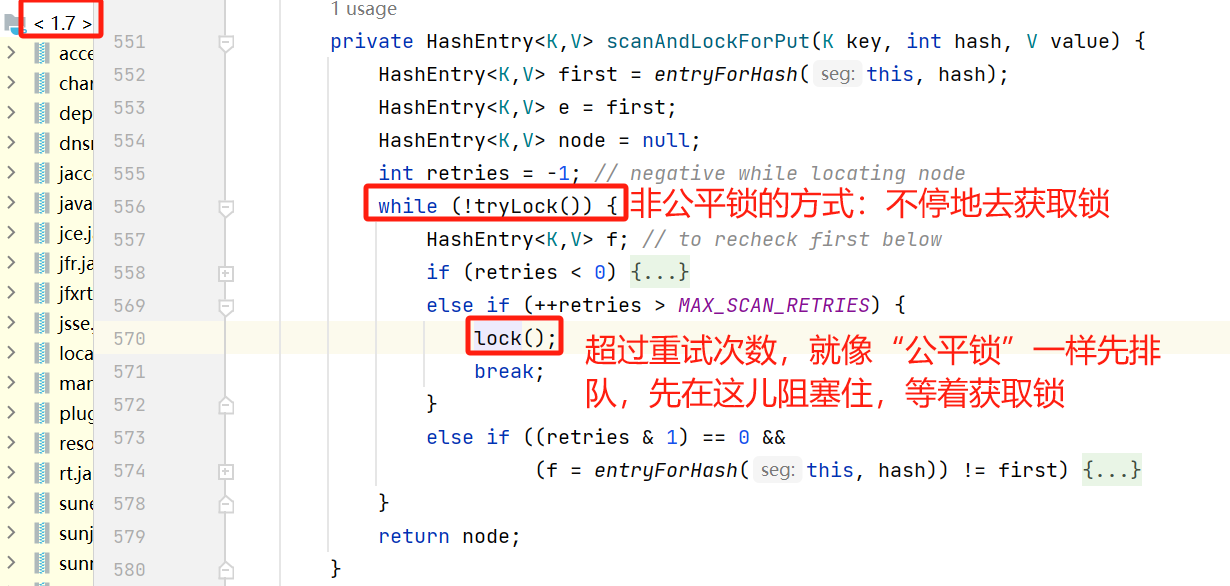
先使用“非公平锁”的方式,通过while循环,不停地重试去tryLock()获取锁;超过重试次数后,使用“公平锁”的方式,先排队,阻塞在这儿等着,直到获取锁,在往下执行。
2.3,执行业务代码
经过上面的步骤,获取到锁后,表示现在只有自己能操作这个Segment对象,保证了线程安全。
2.4,释放锁

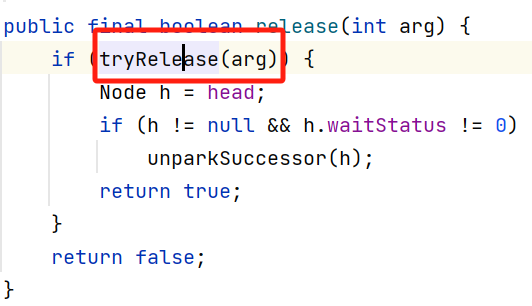
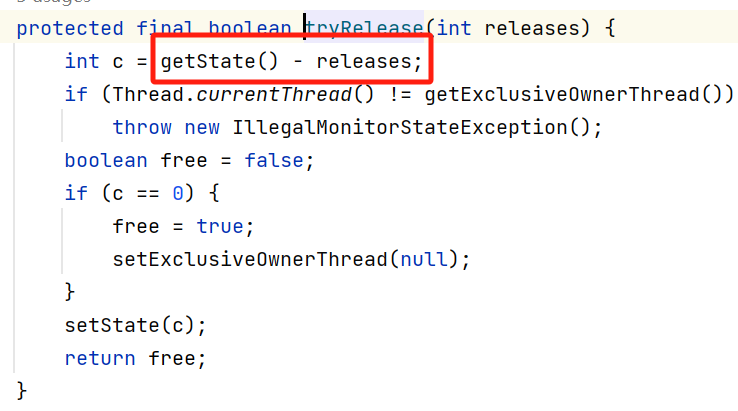
如上图所示,释放锁时,Segment对象的CAS的“当前值”减1。
对于重入的情况,每次重入都加1,但是每次退出的时候也都会减1。
最终释放锁后,Segment对象的CAS的“当前值”变成0。
3,remove()方法流程

如上图,删除元素时使用了和插入元素时一样的锁,所以remove()和put()的所有操作不分你我,都是有序进行的。
4,get()方法流程
4.1,概述
先查到Segment对象,再查到链表对象,最后在链表中找到元素。
4.2,再说put()方法
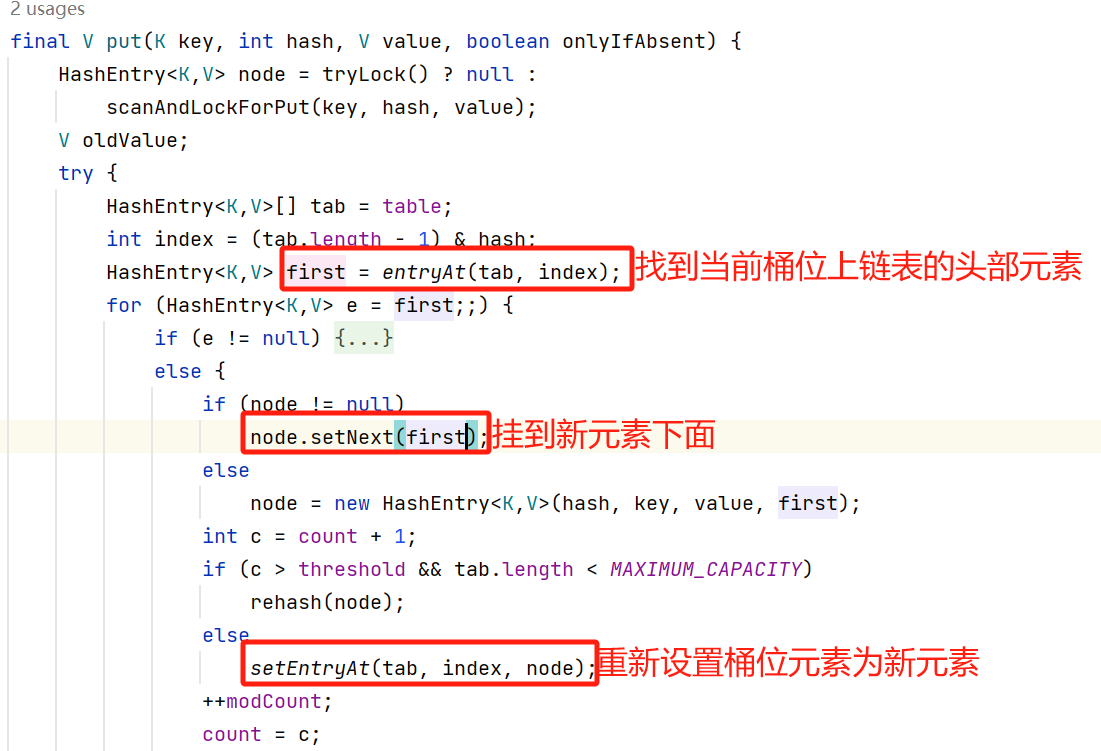
如上图所示
a,先找到桶位元素,也就是链表的头部元素;
b,将头部元素挂到新元素的下面,也就是把整条链表挂到新元素下面;
c,修改桶位元素(头部元素)为新元素;
即”头插法“,那么get()的时候,不管遍历寻找到链表上的哪个元素了,都不影响,因为查找是向下找的,新元素都在最上面。
4.3,再说remove()方法
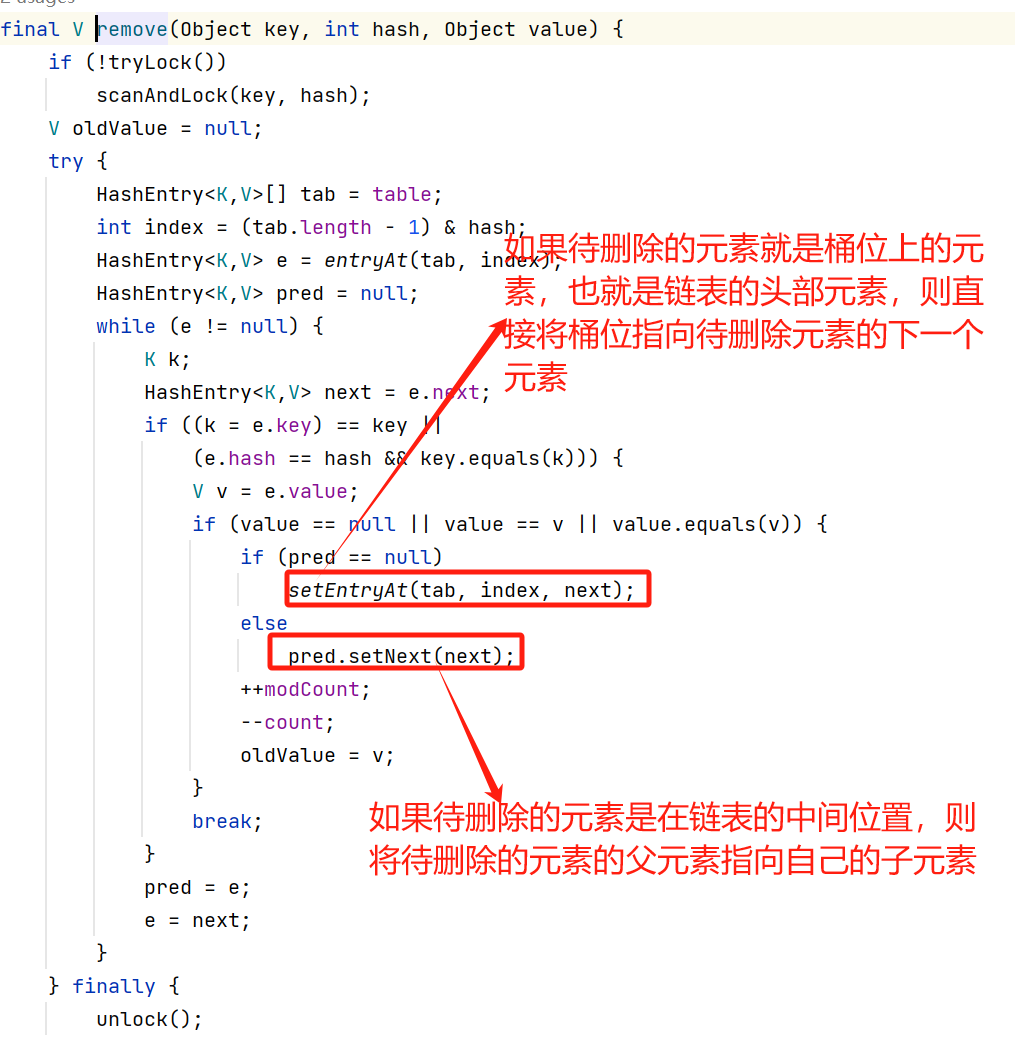
如上图所示,删除分为两种情况
删除前:
4.3.1,待删除的元素是头部元素
比如:待删除的元素:“春”。
删除后: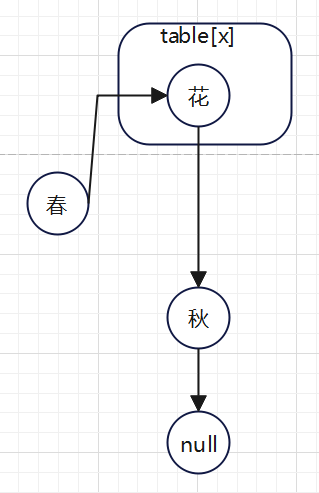
可见,链表的结构并没有改变;比如get()方法走到“春”了,它还能向下找到“花”、找到“秋”;
get()方法走到“春”了,因为get()方法的变量指向“春”,“春”不会被jvm垃圾回收;走到“花”了,就和“春”没有关系了,“春”被jvm垃圾回收也没关系了。
4.3.2,待删除的元素是中间元素
比如:待删除的元素:“花”。
删除后: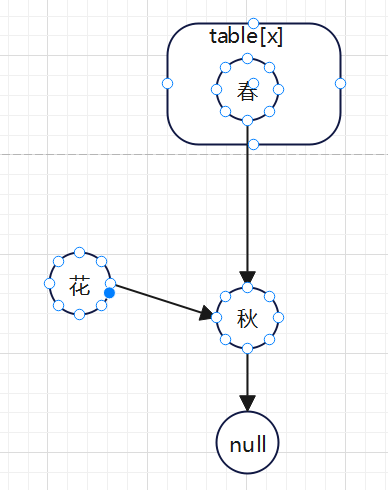
比如get()方法走到“春”了,如果get()要查找的是“花”,那么返回null,没查到;也能理解,毕竟你查的时候,待查的元素能被另一个线程删除,也是ConcurrentHashMap的优秀功能之一;
get()方法走到“花”了,如果get()要查找的是“花”,那么返回“花”;也能理解,虽然“花”已经不在ConcurrentHashMap中了,但是你查的时候“花”是在的,就好像我打电话给小王,问她在哪儿,她说在家,我就去她家找她,结果我到了她却不在了,我不能怪她,因为我没让她等我;
4.4,再说table数组的扩容方法
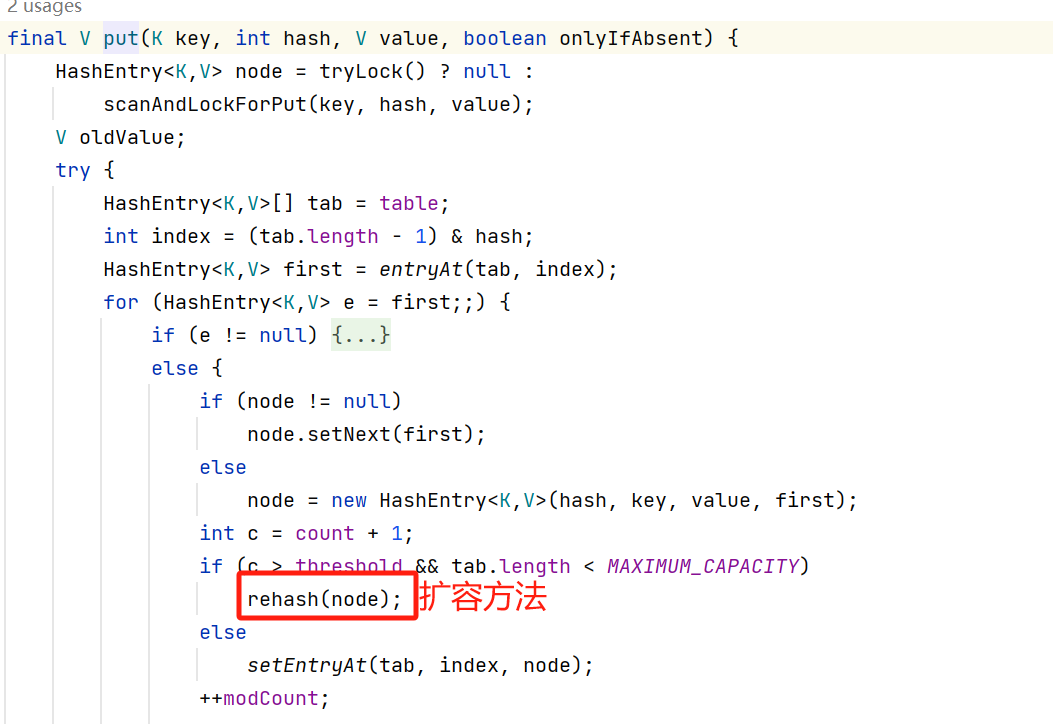

如上图,扩容的逻辑和HashMap(jdk1.7)是一样的,可参考HashMap线程不安全实例(jdk1.7) – seeAll – 博客园 (cnblogs.com)。
扩容的时候先创建一个新数组,转移元素时,也是根据旧的元素new出来一个新元素对象,然后将新对象放进新数组中。
简单示意一下:
扩容前: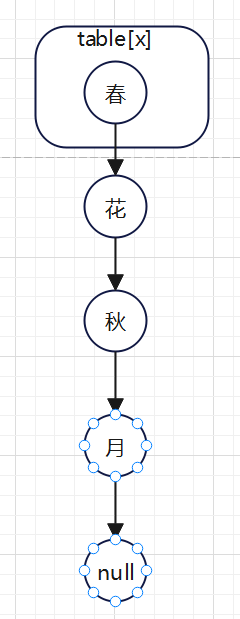
假如“春”和“秋”需要转移,那么效果如下
第一次for循环: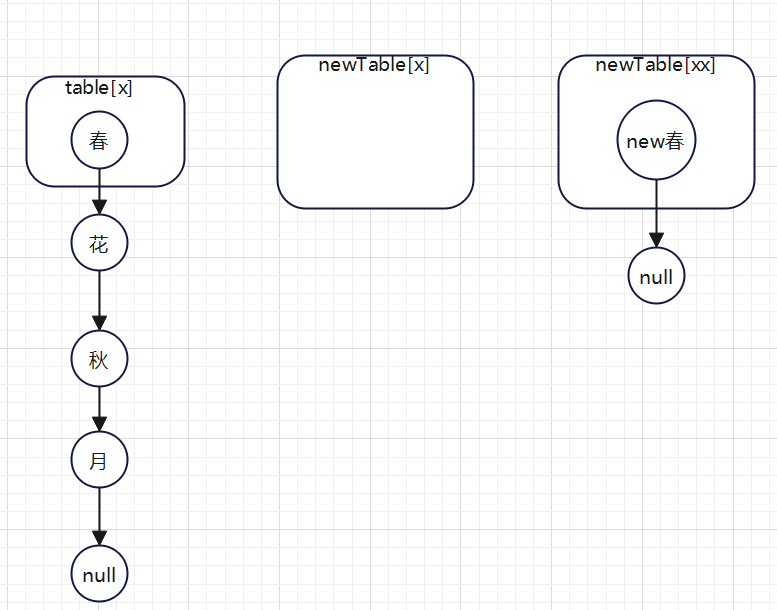 ,
,
第二次for循环: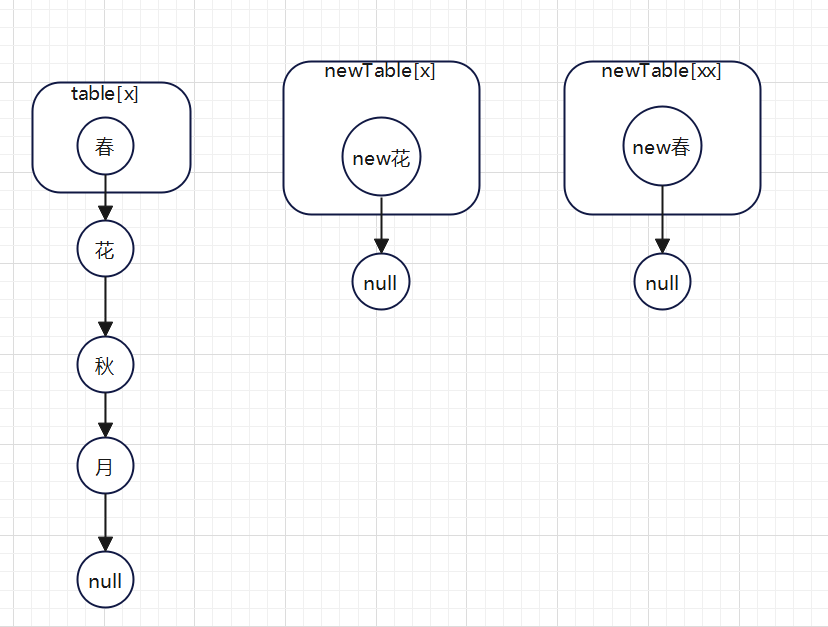
第三次for循环: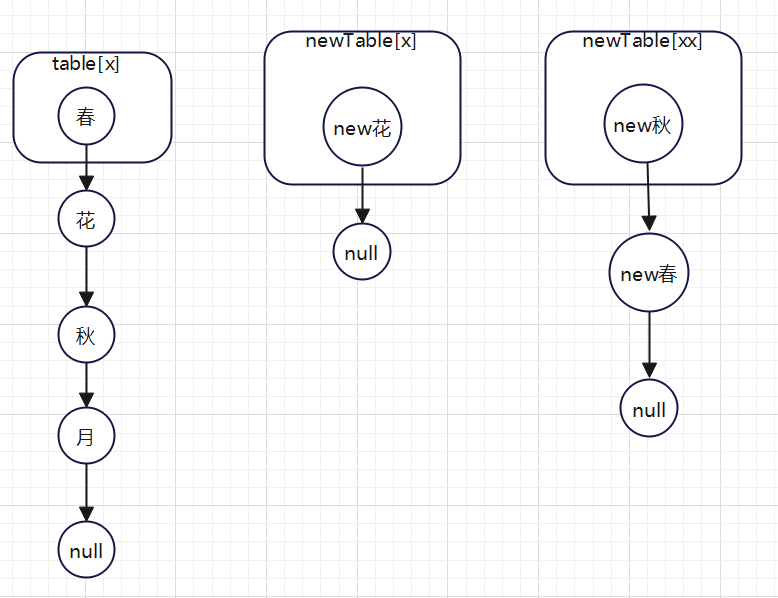
第四次for循环: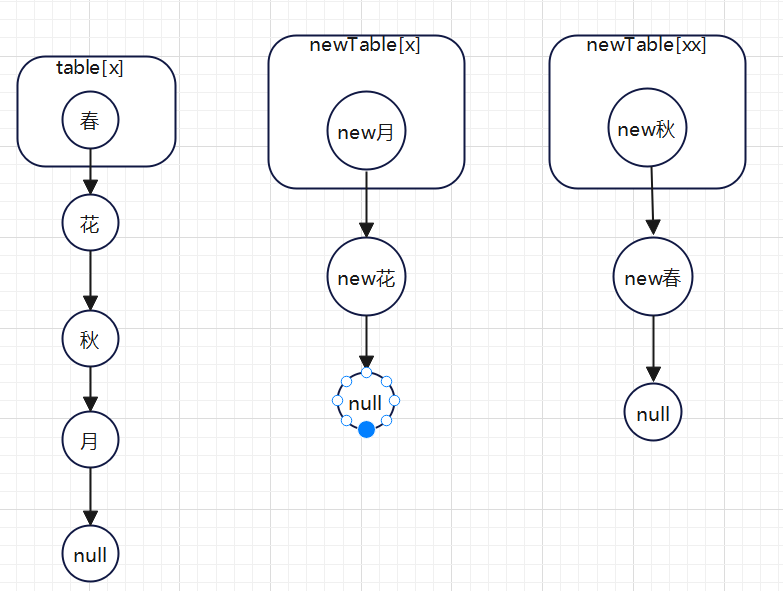
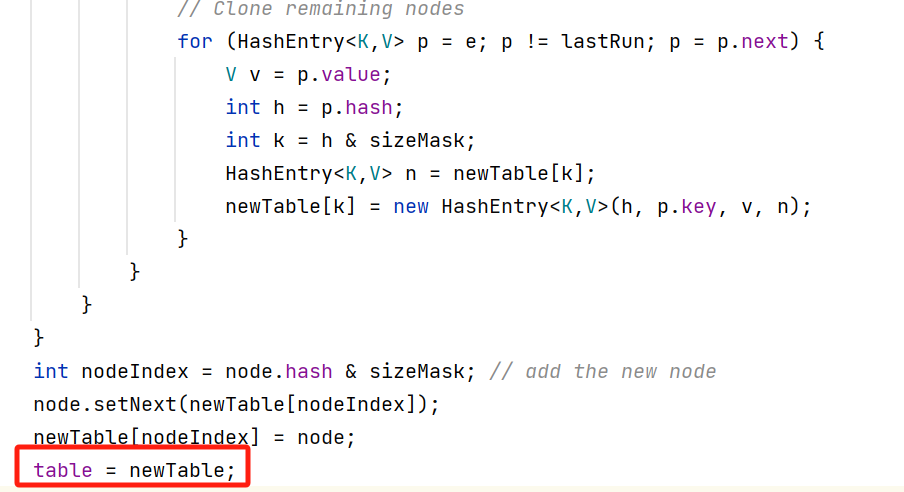
for循环结束,执行table=newTable:
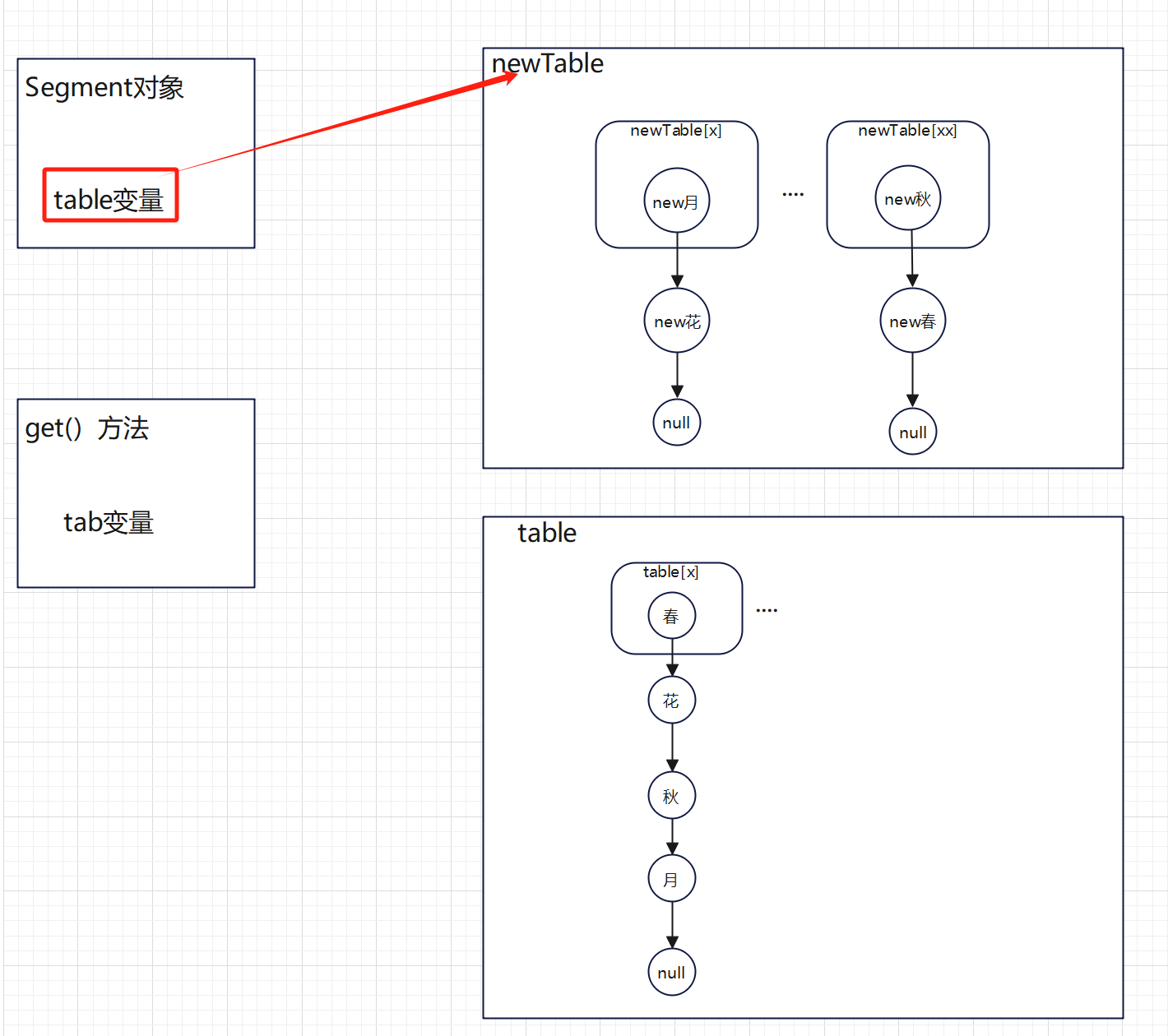
分析:
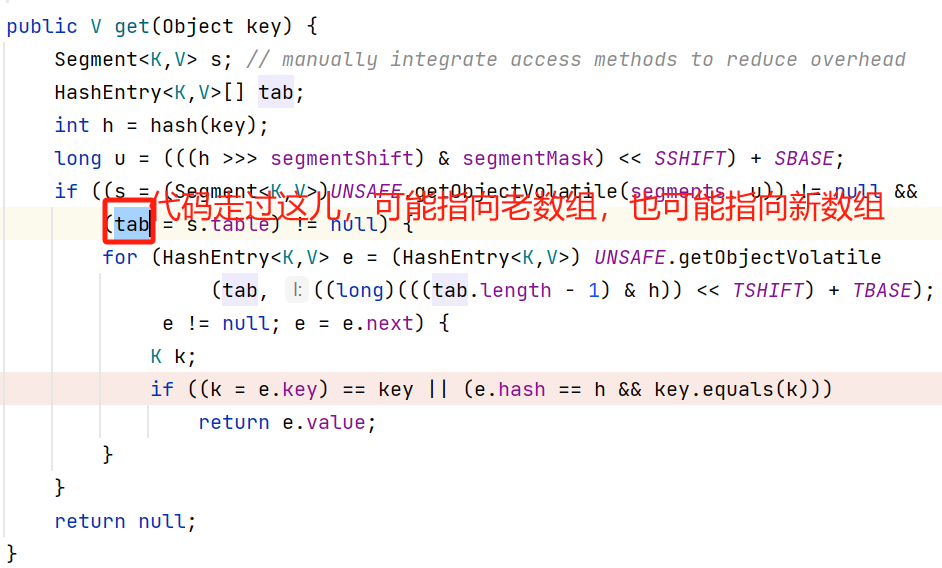
get()方法对方法的局部变量tab赋值后,tab可能指向老数组,也可能指向新数组,但是赋值后,这个get()方法对应的栈里的tab变量指向的堆里的对象就不会变了,要么是老数组对象,要么是新数组对象,且扩容的时候,没有动一点老数组对象,且新数组对象也是在完全构造完成后才赋值给Segment对象的table变量的,不存在指向半成品的情况;
情况1:
指向老数组,老数组对象一点没变,且因为有这个tab变量指向着,没有被jvm垃圾回收,查找不受影响;
情况2:
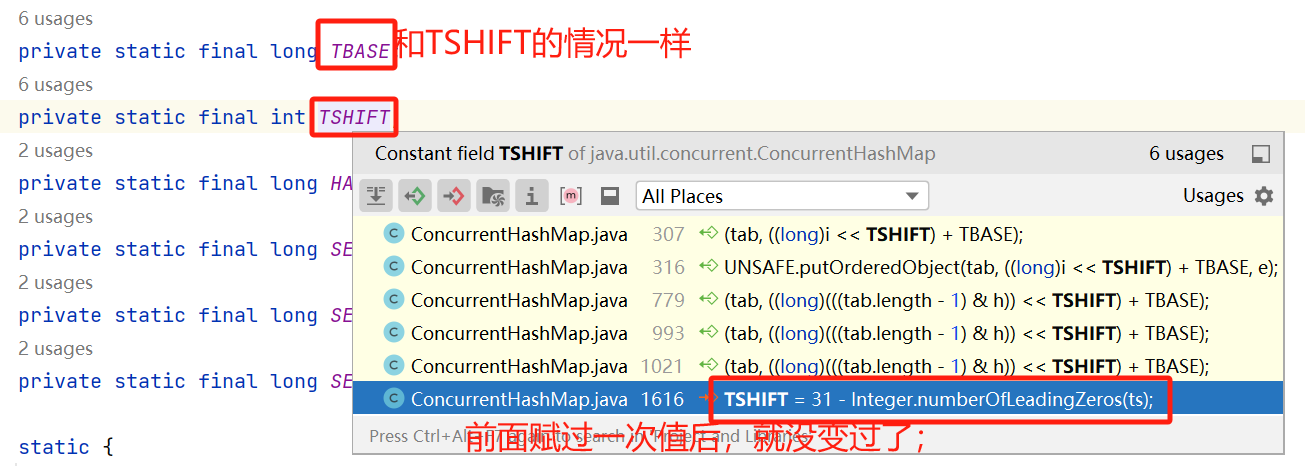
指向新数组,tab.length也跟着一起变了,其他两个变量TSHIFT、TBASE至始至终都没有变化过,所以也能根据待查找元素key的hash值找到其新位置,则查询也不受影响。
四、总结
1,概述
put()和remove()都使用了同样的锁,所有的操作(包括put()和remove())混合在一起都能有序进行,互不影响;
get()方法上面也分析了,不会对ConcurrentHashMap本身结构产生影响,在get()的同时,进行put()、remove()、扩容都没关系;只是可能会产生“明明里面有,为什么没查到”、“明明删除了,为什么还能查到”的误解,上面也都解释了;比如“明明里面有,为什么没查到”,你查的时候,元素被其他人删除了,自然查不到,除非没被别人删除也查不到才有问题;比如“明明删除了,为什么还能查到”,你查的时候确实是有的,只是后来被其他人删除了,除非是你删除的你再查还能查到才有问题。
2,ConcurrentHashMap的应用场景
多线程操作Map结构的数据时,都可以使用ConcurrentHashMap。
3,ConcurrentHashMap的注意点
ConcurrentHashMap本身没什么问题,重要的是在业务中使用的时候,思考ConcurrentHashMap能否满足业务需要,会不会产生偏差。
4,CAS的ABA问题?
网上大部分的解释是,比如当前值是10,然后有两个线程操作如下:
对象1;
对象2;
对象3;
线程1{
CAS(对象1, 对象2);
CAS(对象2, 对象1);
}
线程2{
CAS(对象1, 对象3);
}
线程1先执行,对象1->对象2->对象1;线程2后执行,对象1->对象3;两个线程都能执行成功,然后说线程2有问题,他以为的当前值对象1已经不是一开始的对象1了,是对象1->对象2->对象1。
有点百思不得其解,这有什么问题,是线程1是程序员A写的,线程2是程序员B写的,两个人有矛盾?
并且jdk中有专门处理这个问题的类AtomicStampedReference,连jdk都加了版本号来方便程序员识别ABA问题,如下代码所示
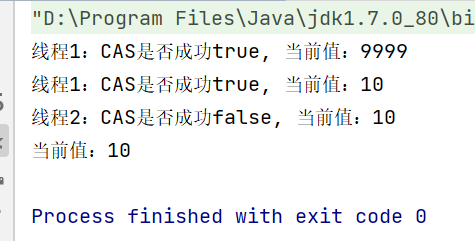
public static void main(String[] args) throws InterruptedException { // 初始值 final String originalStr = "10"; // 初始版本号 final int originalStamp = 3; final AtomicStampedReference<String> atomicStampedReference = new AtomicStampedReference<>(originalStr, originalStamp); final CountDownLatch countDownLatch = new CountDownLatch(2); final CountDownLatch waitThread1 = new CountDownLatch(1); Thread thread1 = new Thread(new Runnable() { @Override public void run() { String str2 = "9999"; boolean aaa; // CAS操作,值由(originalStr = "10")变成"9999",版本号由(originalStamp = 3)变成4 aaa = atomicStampedReference.compareAndSet(originalStr, str2, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1); System.out.println("线程1:CAS是否成功" + aaa + ", 当前值:" + atomicStampedReference.getReference()); // CAS操作,值由"9999"变成(originalStr = "10"),版本号由4变成5 aaa = atomicStampedReference.compareAndSet(str2, originalStr, atomicStampedReference.getStamp(), atomicStampedReference.getStamp() + 1); System.out.println("线程1:CAS是否成功" + aaa + ", 当前值:" + atomicStampedReference.getReference()); countDownLatch.countDown(); waitThread1.countDown(); } }); Thread thread2 = new Thread(new Runnable() { @Override public void run() { try { waitThread1.await(); } catch (InterruptedException e) { throw new RuntimeException(e); } boolean aaa; aaa = atomicStampedReference.compareAndSet(originalStr, "33", originalStamp, atomicStampedReference.getStamp() + 1); System.out.println("线程2:CAS是否成功" + aaa + ", 当前值:" + atomicStampedReference.getReference()); countDownLatch.countDown(); } }); thread1.start(); thread2.start(); countDownLatch.await(); System.out.println("当前值:" + atomicStampedReference.getReference()); }
执行以上代码后,线程2的CAS操作失败,没有更新值,因为实际版本号和自己期望的版本号不一致,如下图所示
将代码中线程2的CAS的期望版本号改成5后,线程2的CAS操作成功,如下图所示

