String类是引用数据类型,类全名:java.lang.String , 所以使用的时候不需要导包
String类被final修饰,无法继承,另外String类实现了Serializable接口,表示String类是支持序列化的。另外还实现了Comparable接口,表示String对象是可比较的。还实现了CharSequence接口
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
/**
* The value is used for character storage.
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*
* Additionally, it is marked with {@link Stable} to trust the contents
* of the array. No other facility in JDK provides this functionality (yet).
* {@link Stable} is safe here, because value is never null.
*/
@Stable
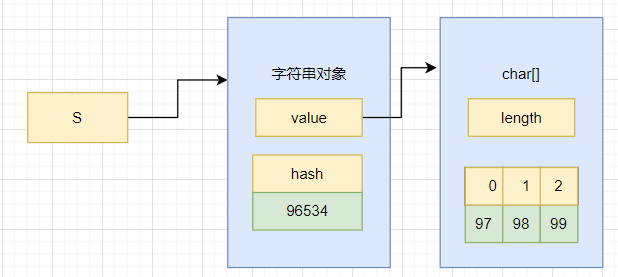
private final byte[] value;
说明字符串底层实际上是一个字节数组;数组的特点是一旦确定长度不可变,并且value被final修饰,说明value不能重新指向新的byte数组对象,说明字符串一旦创建长度不可变;被private修饰说明在外界无法获取value数组,进而无法修改数组的内容。所以字符串一旦创建长度和内容都无法改变
- 字符串不可变,它们的值在创建后不能被更改
- 虽然 String 的值是不可变的,但是它们可以被共享
- 字符串效果上相当于字符数组( char[] ),但是底层原理是字节数组( byte[] )
Java中字符串使用效率较高,如果每一次都去堆内存中寻址再开辟空间效率太低,所以在Java语言中通过双引号创建的字符串对象都会在字符串常量池中存储一份,以后如果使用该字符串对象,会直接从字符串常量池中取出,这时一种提高程序执行效率的缓存机制
public class StringConstructor {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";//s1和s2指向了字符串中的同一个对象,其值是相同的
}
}
程序执行到第三行的时候,检测到双引号括起来的hello字符串,此时会去字符串常量池中查找,如果没有找到就会创建hello对象,并将hello存储在字符串常量池中; 在程序执行到第六行的时候,检测到hello字符串,同样会去字符串常量池中查找。由于一个字符串可能会被多个引用指向,为了保证数据的安全性,字符串被设计为不可变的。
java8之前字符串常量池存储在方法区中(java8之后方法区也没有了,叫做metaspace元空间),Java8之后把字符串常量池挪到了堆内存当中
创建了几个对象
public class StringConstructor {
public static void main(String[] args) {
String s1 = new String("hello");
String s2 = new String("hello");
}
}
使用new运算符必然导致堆内存当中开辟新的存储空间,所以以上程序创建了三个对象,堆内存中两个String对象,字符串常量池中一个hello对象。(实际上三个对象都在堆内存中)

S2在堆内存中创建了一个字符串对象,在Stringtable中也创建了一个字符串对象,S1在创建的时候会直接复用Stringtable中的对象,所以只创建了两个字符串对象
但是堆内存中的字符串对象和Stringtable中的字符串对象使用了同一个byte数组
字符串拼接
+ 两边都是常量
分析:
public class StringAppend {
public static void main(String[] args) {
String s = "abc" + "def";
}
}
大家可能会认为此处创建三个字符串常量;但对以上class文件进行反编译:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
public class StringAppend {
public StringAppend() {
}
public static void main(String[] args) {
String s = "abcdef";
}
}
可以看到第11行直接就是 “abcdef”,没有”abc”,”def”;说明”abc” + “def”是在编译阶段进行了字符串拼接
拼接字符串时如果没有变量,触发字符串优化机制,编译阶段得到最终结果
+ 两边有变量
public class StringAppend {
public static void main(String[] args) {
String s1 = "abc";
String s2 = s1 + "def";
}
}
反编译结果是:
public class StringAppend {
public StringAppend() {
}
public static void main(String[] args) {
String s1 = "abc";
String s2 = s1 + "def";
}
}
可以看出,”abc”,”def”都是有的,只是没有”abcdef”;这是因为在拼接的时候new了一个StringBuilder对象,通过StringBuilder对象的append方法进行了字符串拼接,但是此时还只是一个StringBuilder对象,需要通过toString方法转换为字符串,其实执行了:
String s2 = new StringBuilder().append(s1).append("b").toString();
对于toString方法:

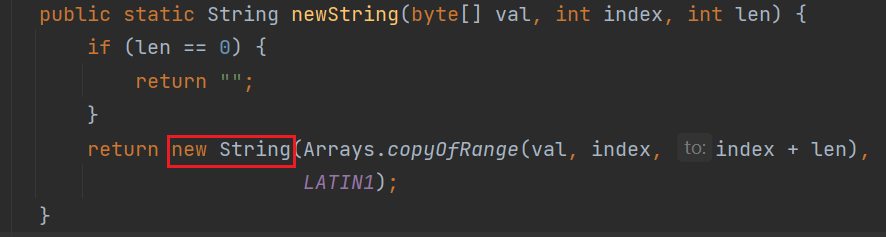
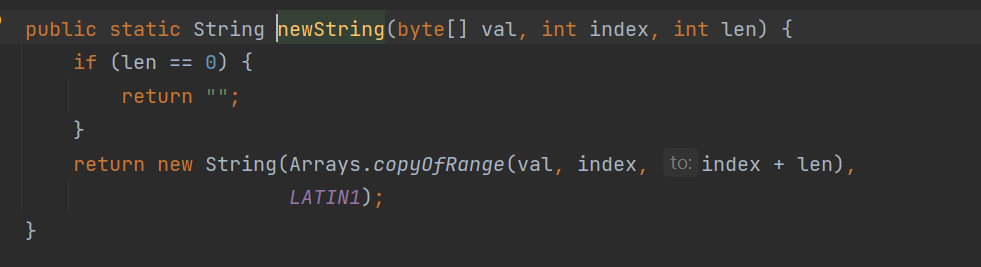
public static String newString(byte[] val, int index, int len) {
if (len == 0) {
return "";
}
return new String(Arrays.copyOfRange(val, index, index + len),
LATIN1);
}
也就是说,在变回字符串的时候是通过new创建了一个字符串。
结论:非final变量拼接字符串至少创建了两个对象:StringBuilder和String
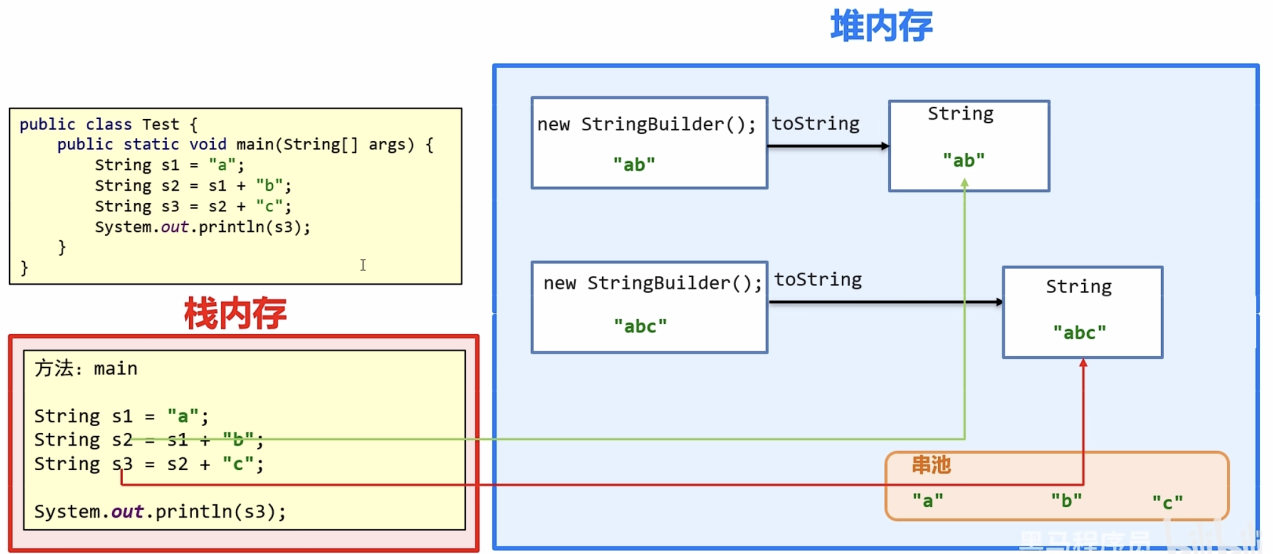
JDK8的优化

事先预估最终字符串的长度,创建一个长度为3的数组,将abc存入后转换为字符串(new String)

在JDK8之前,执行s1+s2时会先创建一个StringBuilder对象,append之后调用toString转换为String类型,再+s3,重复这步操作,至少会创建4个对象。
即使JDK8进行了优化,在多行拼接时一样也会浪费时间,所以建议使用以下方式进行拼接。
不要频繁使用 + 进行字符串拼接
- 如果两边都是字符串常量,可以使用加号进行拼接,因为这是编译阶段进行拼接
- 如果加号两边有任意一个变量,必然会导致底层new一个StringBuffer对象进行字符串拼接
如果循环拼接的话,每循环一次都要new一个StringBuilder对象,所以效率极低,例如以下代码:
public class StringAppend {
public static void main(String[] args) {
long begin = System.currentTimeMillis();
String s = "";
for (int i = 0; i < 10_000; i++) {
s = s + i;
}
long end = System.currentTimeMillis();
System.out.println(end - begin);
}
} //执行了47ms
在短时间内就会new出来一万个StringBuilder对象,效率较低;建议在外部手动创建一个StringBuilder/StringJoiner对象,然后在for循环中进行append拼接:
public class StringAppend {
public static void main(String[] args) {
long begin = System.currentTimeMillis();
StringBuilder s = new StringBuilder("");
for (int i = 0; i < 10_000; i++) {
s.append(i);
}
long end = System.currentTimeMillis();
System.out.println(end - begin);
}
} //执行了0ms
面试题
创建了几个对象
public static void main(String[] args){
String s1 = "abc";
String s2 = "ab";
String s3 = s2 + "c";
System.out.println(s1 == s3);
}
JDK8之前:在执行String s3 = s2 + "c"时,会创建一个StringBuilder对象,该对象执行完append方法之后会调用toString方法转换为字符串,转换时使用new关键字创建字符串对象,s3接收到的是堆内存中的地址,堆内存中的该对象指向了字符串常量池中的字符串。
JDK8:系统预估字符串拼接之后的总大小,把要拼接的内容都放在数组中,此时也是产生了一个新的字符串(也是new出来的)
public static void main(String[] args){
String s1 = "abc";
String s2 = "a" + "b" + "c";
System.out.println(s1 == s2); //true
}
编译阶段优化,在编译时就会将第三行代码拼接为abc,记录的都是字符串常量池的地址
字符串的不可变性
String的长度不可变:数组的长度是不可变的,如果要变化只能进行数组扩容,而String类的value属性是final修饰的,不能指向其他数组,所以字符串的长度不可变
String的内容不可变:value是private修饰的,在外界无法获取到value属性,进而无法修改其中的内容
public class StringBuilderTest {
public static void main(String[] args) {
String s = "abc";
s = "xyz";
}
}
这样的操作是可行的,因为s并没有使用final修饰,还是可以指向其他对象的。
StringBuilder的长度可变:内部的byte数组没有用final修饰,数组满了(即将满了)会使用Arrays.copyOf方法扩容。
String类的equals方法
== 比较的是引用保存的内存地址,String类的equals经过重写,比较的是对象的内容
使用的时候建议用字符串常量调用equals方法,可以避免空指针异常
Scanner类的next方法
核心:键盘录入的字符串是new出来的
- 如果键盘录入abc,与代码中定义的abc比较,结果如何?
Scanner sc = new Scanner(System.in);
String next = sc.next();
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1 == next);//false
System.out.println(str2 == next);//false
next()方法:
public String next() {
ensureOpen();
clearCaches();
modCount++;
while (true) {
String token = getCompleteTokenInBuffer(null);
if (token != null) {
matchValid = true;
skipped = false;
return token;
}
if (needInput)
readInput();
else
throwFor();
}
}
返回一个token:
查找group()方法:
查找group(0)方法:
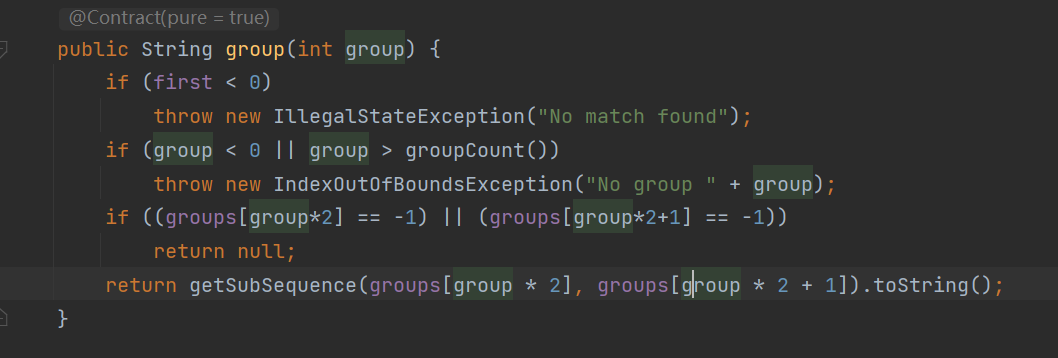

ctrl + alt + B : goto implementations String
所以next接收的字符串会经过new创建的。
String类构造方法
- String(original)
String s = "";
String s = new String();
- 将byte数组转换为字符串
String s = new String(byte数组);
String s = new String(byte数组,起始下标,长度);
byte[] bytes = {97,98,99};//97 a 98 b 99 c
String s1 = new String(bytes);
String s2 = new String(bytes,1,2);//byte数组,起始下标,长度
System.out.println(s1); //abc
System.out.println(s2); //bc
- 将char数组转换为字符串
String s = new String(char数组);
String s = new String(char数组,起始下标,长度);
char[] chars = {'a','b','c','d','e','f'};
String s3 = new String(chars);
String s4 = new String(chars,1,4);
System.out.println(s3);//abcdef
System.out.println(s4);//bcde
- new String(String str)
根据原有的字符串对象创建一个新的字符串对象,两个字符串对象引用了同一个数组
String类常用方法
注意:操作字符串的方法只有返回值是结果,因为字符串本身是不能发生变化的。
public char charAt(int index)
返回索引处的字符
String s = "abc";
System.out.println(s.charAt(2));//c
public int compareTo(String anoStr)
按照ASCII顺序比较两个字符串大小
结果:
- = 0 :字符串相等
- < 0 :字符串小于anoStr
-
0 :字符串大于anoStr
System.out.println("abc".compareTo("abc"));
System.out.println("def".compareTo("dev"));//-1
public String concat(String str)
拼接两个字符串
参数只能是String,并且不能为空,为空会报错
System.out.println("a".concat("b")); //ab
public boolean contains(CharSequence s)
判断是否含有子字符串
System.out.println("helloWorld.java".contains("World"));//true
contains底层是通过 this.indexOf(s.toString) > 0 来判断是否含有子字符串的
public boolean endsWith(String suffix)
判断是否以指定后缀结尾
System.out.println("abc".endsWith("c"));
底层通过this.startsWith(suffix, this.length() - suffix.length()) 判断的,以如上代码为例:
suffix = "c"
this.length() - suffix.length() = 3 - 1 = 2
从索引2开始判断是否以指定字符串开头
public boolean equalsIngoreCase(String anotherStr)
忽略大小写判断字符串
底层:
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true
: (anotherString != null)
&& (anotherString.length() == length())
&& regionMatches(true, 0, anotherString, 0, length());
}
System.out.println("helloWorld".equalsIgnoreCase("HELLOWORLD"));
public byte[] getBytes()
将字符串转换为字节数组
System.out.println(Arrays.toString("abcd".getBytes()));//[97, 98, 99, 100]
public int indexOf(String str)
从fromIndex下标开始,获取str子字符串在当前字符串中第一次出现的索引值
System.out.println("helloWorld".indexOf("lo",2));
public boolean isEmpty()
判断当前字符串是否为空
System.out.println("".isEmpty());
System.out.println(" ".isEmpty());//false
public int lastIndexOf(String str)
获取str子字符串在当前字符串中最后出现的索引
System.out.println("helloWorld".lastIndexOf("l"));
public int lastIndexOf(String str,int fromIndex)
从指定索引开始,反向搜索str字符串在当前字符串中首次出现的索引
System.out.println("hellWorllod".lastIndexOf("llo",3)); // -1
public int length()
获取字符串长度
System.out.println("java".length());
public String replace(CharSequence target,CharSequence replacement)
使用指定的字面值替换序列replacement 替换当前字符串中所有匹配字面值目标序列target的子字符串
System.out.println("c++ c++ c++".replace("c++","java"));
System.out.println("http://www.baidu.com".replace("http://","https://"));
public String[] split(String regex)
将当前字符串以某个特定符号拆分,返回String[] 数组
System.out.println(Arrays.toString("1980-1-1".split("-"))); //[1980, 1, 1]
public boolean startsWith(String prefix)
判断当前字符串对象是否以指定子字符串开头
System.out.println("helloWorld".startsWith("hello"));
public String subString(int fromIndex)
从fromIndex开始截取字符串,返回截取到的字符串
System.out.println("helloWorld".substring(5));
public String subString(int beginIndex,int endIndex)
截取 [beginIndex,endIndex) 的字符串
System.out.println("helloWorld".substring(5,"helloWorld".length()));
public char[] toCharArray()
将字符串转换为char[] 数组
System.out.println(Arrays.toString("helloWorld".toCharArray()));//[h, e, l, l, o, W, o, r, l, d]
public String toUpperCase()
转换大写
System.out.println("helloworld".toUpperCase());
public String toLowerCase()
转换小写
System.out.println("HELLOWORLD".toLowerCase());
public String trim()
去除前后的空白(中间不能去除)
System.out.println(" hello ".trim());
public static String valueOf(Object obj)
String类唯一的静态方法,作用是将非字符串的内容转换为字符串
System.out.println(String.valueOf(new Object()));//java.lang.Object@776ec8df
如果直接输出一个对象:
Object a1 = new Object();
System.out.println(a1);
println方法,会调用String类的valueOf方法:
public void println(Object x) {
String s = String.valueOf(x);//println调用valueOf
if (getClass() == PrintStream.class) {
// need to apply String.valueOf again since first invocation
// might return null
writeln(String.valueOf(s));
} else {
synchronized (this) {
print(s);
newLine();
}
}
}
String类的valueOf方法会自动调用toString方法:
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();//valueOf调用了toString方法
}
所以控制台输出的任何内容都自动调用了valueOf,valueOf调用了对象的toString
练习
用户登录
已知正确的用户名和密码,请用程序实现模拟用户登录,总共三次机会;登录之后给出相应的提示
String rightPassword = "123";
String rightUserName = "admin";
Scanner sc = new Scanner(System.in);
for (int i = 0; i < 3; i++) {
String username = sc.next();
String password = sc.next();
if (rightPassword.equals(password) && rightUserName.equals(username)){
System.out.println("成功");
break;
}
System.out.println(i != 2 ?"输入错误,还有" + (2 - i) + "次机会" : "账户已被锁定");
}
遍历字符串
String str = "helloWorld";
for (int i = 0; i < str.length(); i++) {
System.out.println(str.charAt(i));
}
统计字符个数
统计每个字符出现的次数:
String str = "helloWorld";
int[] arr = new int[Character.MAX_VALUE];
for (int i = 0; i < str.length(); i++) {
arr[str.charAt(i)]++;
}
for (int i = 0; i < arr.length; i++) {
if (arr[i] != 0){
System.out.println(((char) i) + "出现了:" + arr[i] + "次");
}
}
String str = "helloWorld";
int[] arr = new int[Character.MAX_VALUE];
for (byte b : str.getBytes()){
arr[b]++;
}
for (int i = 0; i < arr.length; i++) {
if (arr[i] != 0){
System.out.println(((char) i) + "出现了:" + arr[i] + "次");
}
}
String str = "helloWorld";
HashMap<Character,Integer> map = new HashMap<>();
for (int i = 0; i < str.length(); i++) {
if (map.get(str.charAt(i)) == null){
map.put(str.charAt(i),1);
}else {
map.put(str.charAt(i),map.get(str.charAt(i)) + 1);
}
}
System.out.println(map);
map.merge(str.charAt(i),1,Integer::sum);
统计大小写、数字的出现次数:
String str = "helloWorld";
int upperCaseCount = 0;
int lowerCaseCount = 0;
int otherCount = 0;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) >= 'a' && str.charAt(i) <= 'z'){
lowerCaseCount++;
} else if (str.charAt(i) >= 'A' && str.charAt(i) <= 'Z') {
upperCaseCount++;
} else {
otherCount++;
}
}
System.out.println("upper = " + upperCaseCount + " lower = " + lowerCaseCount);
数组转换为字符串
int[] arr = {97,97,97,97,97};
String str = "";
for (int i = 0; i < arr.length; i++) {
str += (char)arr[i];
}
System.out.println(str);
反转字符串
String str = "java is best";
byte[] bytes = str.getBytes();
for (int i = 0; i < bytes.length / 2; i++) {
bytes[i] = (byte)(bytes[i] ^ bytes[bytes.length - 1 - i]);
bytes[bytes.length - 1 - i] = (byte)(bytes[i] ^ bytes[bytes.length - 1 - i]);
bytes[i] = (byte)(bytes[i] ^ bytes[bytes.length - 1 - i]);
}
System.out.println(new String(bytes));
//倒序遍历字符串实现
String str = "java is best";
String newStr = "";
for (int i = str.length() - 1; i >= 0; i--) {
newStr = newStr + str.charAt(i);
}
System.out.println(newStr);
//正序遍历字符串实现
String str = "java is best";
String newStr = "";
for (int i = 0; i < str.length(); i++) {
newStr = str.charAt(i) + newStr;
}
System.out.println(newStr);
金额转换
2135 -> 零佰零拾零万贰仟壹佰叁拾伍元
手机号屏蔽
String phoneNumber = "13112349468";
String result = phoneNumber.substring(0,3) + "****" + phoneNumber.substring(7);
System.out.println(result);
也可以使用replace(有nug):
System.out.println(phoneNumber.replace(phoneNumber.substring(3, 7), "****"));
身份证信息
定义一个方法, 接收一个字符串代表身份证号码。方法中实现判断身份证是否正确:
a.身份证长度为18。
b.第一位是不为0的数字。
c.2-17位都是数字。
d.最后一位可以是数字,可以是大写字母’X’
敏感词替换
String[] rude = {"TMD"};
String talk = "TMD123";
for (int i = 0; i < rude.length; i++) {
if (talk.contains(rude[i])){
talk = talk.replace(rude[i],"***"); //字符串的实例方法返回的是改变后的字符串
}
}
System.out.println(talk);
模拟trim方法
验证码
public static String generateCode(int n){
StringBuilder builder = new StringBuilder();
Random random = new Random();
for (int i = 0; i < n; i++) {
builder.append(switch (random.nextInt(3)){
case 0 -> (char) ('a' + random.nextInt(26));
case 1 -> (char) ('A' + random.nextInt(26));
case 2 -> (char) ('0' + random.nextInt(10));
default -> throw new IllegalStateException("Unexpected value: " + random.nextInt(3));
});
}
return builder.toString();
}
思路二:
String data = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
思路三:
char[] cs = new char[52 + 10];
for(int i = 0; i < cs.length; i++){
if(i < 26){
cs[i] = (char)('a' + i);
}else if(i < 52){
cs[i] = (char)('A' + (i - 26));
}else{
cs[i] = (char)('0' + (i - 52));
}
}
StringBuilder
Java中的字符串是不可变的,JDK1.7时,+ 拼接字符串每次都会创建一个StringBuilder对象,会占用大量的方法区(JDK1.7的字符串常量池在方法区中,JDK1.8改为metaspace并转移到堆内存中)内存,造成内存空间的浪费
创建一个初始化容量为16的字符串缓冲区:
StringBuffer buffer = new StringBuffer();
StringBuilder源代码:
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuilder>, CharSequence
{
/** use serialVersionUID for interoperability */
@Serial
static final long serialVersionUID = 4383685877147921099L;
/**
* Constructs a string builder with no characters in it and an
* initial capacity of 16 characters.
*/
@IntrinsicCandidate
public StringBuilder() {
super(16);//调用父类AbstractStringBuilder的构造方法,参数是16
}
向上查找父类 AbstractStringBuilder:
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
byte[] value;//16传到这个参数的构造方法中的capacity
/**
* The id of the encoding used to encode the bytes in {@code value}.
*/
byte coder;
说明StringBuilder的默认初始化容量是16
可变长字符串:StringBuilder底层是一个byte数组,如果在追加字符串的时候需要进行扩容,本质上是通过Arrays.copyOf创建出一个新的数组,存放原数组的内容和新追加的内容;原来的数组就被GC回收了,再让value指向新的数组。而String的value被final修饰了,不能指向其他的数组对象,所以String的长度不可变,而String的value是private修饰的,在外界无法获取,所以String的内容也不可变。
需要频繁拼接字符串使用:StringBuffer(要求线程安全的环境),StringJoiner(对开始结束符号和中间的连接符号有要求),StringBuilder(单个线程中,不必考虑线程安全)
构造方法
StringBuilder() |
构造一个字符串构建器,其中不包含任何字符,初始容量为16个字符。 |
|---|---|
StringBuilder(int capacity) |
构造一个字符串构建器,其中没有字符,并且具有 capacity参数指定的初始容量。 |
StringBuilder(String str) |
构造一个初始化为指定字符串内容的字符串构建器。 |
常用方法
| 方法名 | 说明 |
|---|---|
| public StringBuilder append(任意类型) | 添加数据并返回对象本身 |
| public StringBuilder reverse() | 反转内容 |
| public int length() | 获取长度 |
| public String toString() | 可以将StringBuilder转换为String |
| public int capacity() | 获取容量 |
StringBuilder类的toString方法被重写了,返回的是对应的String对象(通过new创建)
StringBuilder只是操作字符串的容器,最终还是要转换为字符串的
StringBuilder builder = new StringBuilder("abc");
System.out.println(builder.append("abc").append("abc").reverse().toString());//可以链式调用
String str = builder.toString();
append()
以如下代码为例:
StringBuilder builder = new StringBuilder();
builder.append("abc");
append():

父类append():
public AbstractStringBuilder append(String str) {
if (str == null) {
return appendNull();//如果传入的参数为空
}
int len = str.length();//获取添加字符串的长度
ensureCapacityInternal(count + len);//第二步 count就是length()方法返回值
putStringAt(count, str);//第三步
count += len;//第四步
return this;
}
如果传入的参数为空,return appendNull(),这个方法:
private AbstractStringBuilder appendNull() {
ensureCapacityInternal(count + 4);
int count = this.count;
byte[] val = this.value;
if (isLatin1()) {
val[count++] = 'n';
val[count++] = 'u';
val[count++] = 'l';
val[count++] = 'l';
} else {
count = StringUTF16.putCharsAt(val, count, 'n', 'u', 'l', 'l');
}
this.count = count;
return this;
}
为StringBuilder扩容4个字节,存入”null”
说明如果append(null)的话会在原有的字符串缓冲区后面添加”null”
当str不为null时:
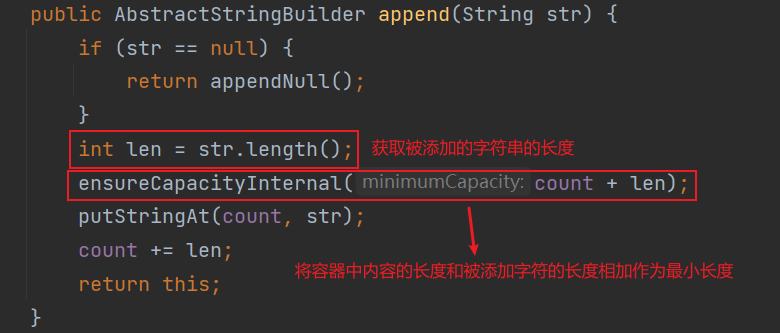
调用ensureCapacityInternal方法,参数 最小容量 = 原有字符串长度 + 新添加字符串的长度
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
int oldCapacity = value.length >> coder;
if (minimumCapacity - oldCapacity > 0) {//最小容量 - 原有容量(默认16)
value = Arrays.copyOf(value,
newCapacity(minimumCapacity) << coder);
}
coder 是 中文标志 ,如果没有中文coder就是0
本例添加”abc”,最小容量3(原有长度0 + 新添加3) – 原有容量16 < 0,不会走if分支,直接进入putStringAt方法。
如果在本例中进行扩容:

此时的状态:老容量16,长度3,被添加的字符串长度35,最小长度38
38 – 16 > 0 ,进入扩容操作:
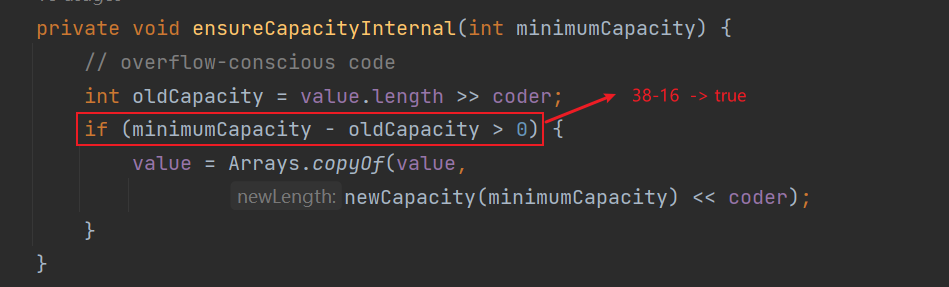
copyOf的方法需要两个参数,第一个是原数组value,第二个是拷贝出新数组的长度,通过newCapacity方法计算
传入参数最小容量
private int newCapacity(int minCapacity) {
int oldLength = value.length; //老容量 16,value是数组
int newLength = minCapacity << coder; //考虑中文 最小容量 38
int growth = newLength - oldLength; // 需要增加容量:22
int length = ArraysSupport.newLength(oldLength, growth, oldLength + (2 << coder)); //老容量 + 2
if (length == Integer.MAX_VALUE) {
throw new OutOfMemoryError("Required length exceeds implementation limit");
}
return length >> coder;
}
通过ArraysSupport.newLength()方法计算出扩容后数组的长度,该方法需要三个参数:
原有数组容量、需要新增容量、偏好新增容量:原有数组容量 + 2
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
//老容量 需要增加容量 老容量 + 2
// preconditions not checked because of inlining
// assert oldLength >= 0
// assert minGrowth > 0
//老容量 + max(需要增加的容量,老容量 + 2)
int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // might overflow
if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {
return prefLength;
} else {
// put code cold in a separate method
return hugeLength(oldLength, minGrowth);
}
}
该方法计算出新数组长度prefLength = 老容量 + Math.max(最小新增容量,偏好新增容量)
说明了StringBuilder的扩容机制:
- 如果需要新增的容量 > 原有数组容量 + 2,扩容到 需要的容量
- 否则扩容到 原有数组容量 * 2 + 2
执行完毕返回newCapacity方法
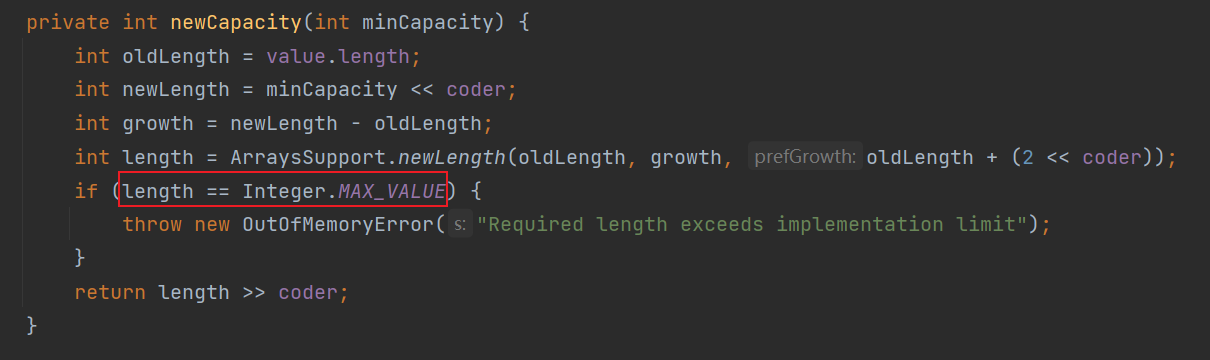
在newCapacity方法中最后对扩容后的容量进行判断,如果达到Integer类型最大值,就抛出异常。
newCapacity方法执行完毕返回ensureCapacityInternal方法
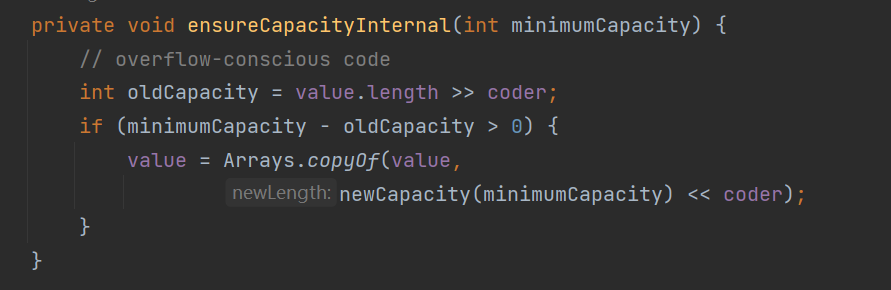
得到了拷贝后的数组,该数组是通过Arrays.copyOf方法获取的
public static byte[] copyOf(byte[] original, int newLength) {
byte[] copy = new byte[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
底层实际上还是System.arrayCopy
原数组会被GC管理回收掉,最后返回该数组的引用给value变量,也就是:
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
byte[] value;//16传到这个参数的构造方法中的capacity
然后执行putStringAt方法:
private void putStringAt(int index, String str) {
putStringAt(index, str, 0, str.length());
}
将str字符串中的字符拷贝到value数组之后进行追加(count就是空位的所有),追加后增加count中记录的数组长度
最后返回当前对象this,实现链式调用。
所以说,StringBuilder底层扩容实际上就是对数组进行扩容,数组的扩容实际上就是数组拷贝,而数组拷贝效率较低;为了提高效率,建议在初始化对象的时候对字符串缓冲区的长度进行预估,给定合适的初始化容量,这样可以减少数组的扩容,提高程序执行效率。
通过capacity()方法可以查看容量
StringBuilder sb = new StringBuilder();
System.out.println("容量:" + sb.capacity());//16
System.out.println("长度:" + sb.length());//00
sb.append("abc");
System.out.println("容量:" + sb.capacity());//16
System.out.println("长度:" + sb.length());//3
sb.append("12345678901234");
System.out.println("容量:" + sb.capacity());//34
System.out.println("长度:" + sb.length());//17
sb.append("012345678901234567");
System.out.println("容量:" + sb.capacity());//70
System.out.println("长度:" + sb.length());//35
append() 方法的返回值是this,也就是容器本身,可以实现链式调用:
返回值是StringBuilder容器本身,这样就可以实现链式编程:
public class StringBuilderDemo4 {
public static void main(String[] args) {
//1.创建对象
StringBuilder sb = new StringBuilder();
//2.添加字符串
sb.append("aaa").append("bbb").append("ccc").append("ddd");
System.out.println(sb);//aaabbbcccddd
//3.再把StringBuilder变回字符串
String str = sb.toString();
System.out.println(str);//aaabbbcccddd
}
}
StringBuilder、StringBuffer的区别
StringBuffer的源码:
@Override
public synchronized int length() {
return count;
}
@Override
public synchronized int capacity() {
return super.capacity();
}
synchronized关键字表示StringBuffer是线程安全的,而StringBuilder是非线程安全的;虽然前者线程安全,但是效率略低;所以一般采用StringBuilder进行字符串拼接,线程安全会选择其他的策略来实现。
StringJoiner
- 构造方法
| 方法名 | 说明 |
|---|---|
| public StringJoiner(间隔符号) | 创建一个StringJoiner对象,指定拼接时的间隔符号 |
| public StringJoiner(间隔符号,开始符号,结束符号) | 创建一个StringJoiner对象,指定拼接时的间隔符号、开始符号、结束符号 |
StringJoiner joiner = new StringJoiner("---");
joiner.add("1").add("2").add("3");
System.out.println(joiner);//1---2---3
数组转换为字符串:
public static String arrToStr(int[] arr){
StringJoiner joiner = new StringJoiner(", ","[","]");
for (int i = 0; i < arr.length; i++) {
joiner.add(String.valueOf(arr[i]));
}
return joiner.toString();
}
- 实例方法
| 方法名 | 说明 |
|---|---|
| public StringJoiner add(String) | 添加数据并返回对象本身 |
| public int length() | 返回长度(带有符号) |
| public String toString() | 可以将StringJoiner转换为String |
练习
判断对称字符串
键盘接受一个字符串,程序判断出该字符串是否是对称字符串,并在控制台打印是或不是
罗马数字的两种写法

旋转字符串

- 第一种解法,暴力求解
- 第二种解法,三次逆序
- 第三种解法,字符串加倍双指针移动
打乱输入的字符串
验证码
四个字母,一个数字,数字的位置随机
字符串相乘
“1000” * “20”
最后一个单词的长度
“hello world”
实现toString
public static String toString(int[] arr){
if (arr == null)
return "NULL";
int iMax = arr.length - 1;
if (iMax == -1)
return "[]";
StringBuilder builder = new StringBuilder("[");
for (int i = 0; ; i++) {
builder.append(arr[i]);
if (i == iMax)
return builder.append("]").toString();
builder.append(",");
}
}
字符串的前世今生
字符串的创建方式:
- char[]
- byte[]
- int[]
- new String(str)
- 字面量(不使用new)
-
- 运算符
从表面上看,后两种没有使用new关键字
char[] 创建字符串
String s = new String(new char[]{'a','b','c'});
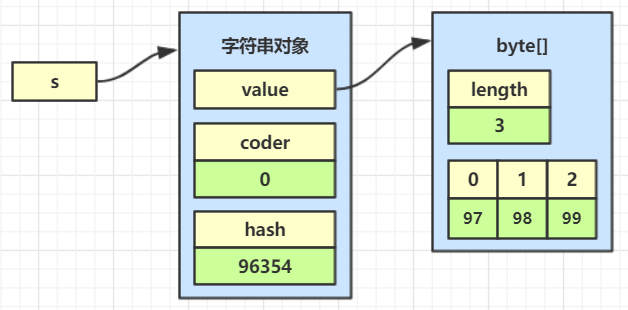
JDK1.8版本的内部结构:
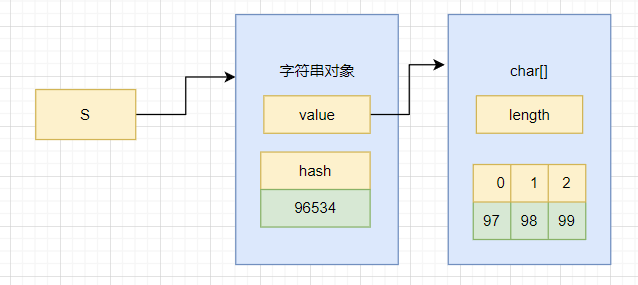
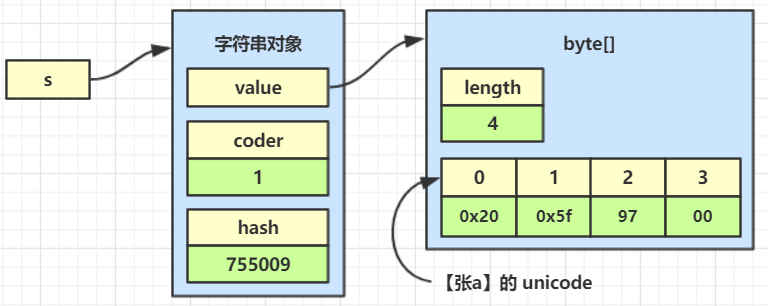
根据unicode编码表将字符转换为数字存储,97就是’a’,98就是’b’,99就是’c’
byte[] 创建字符串
从网络传输的数据,或者IO读取的字符串,最初都是byte形式
String s = new String(new byte[]{97,98,99});
其中的byte数组可以是:
- 网络请求的字节数据,tomcat会转换为字符串
- IO读取的数据
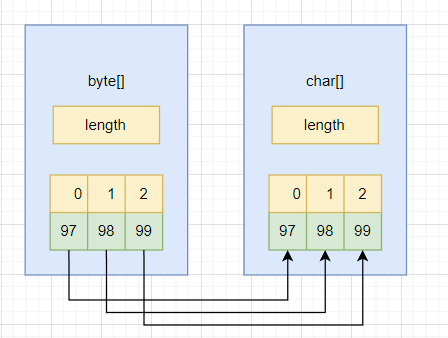
这时byte数组会在构造时被转换为char数组
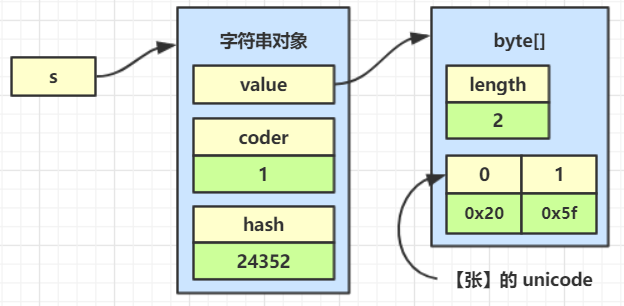
char和byte的大小是不同的,并且char数组中97,98,99代表的是a,b,c,都属于拉丁字符集,如果要转换的是其他的字符集结果就不同了
new String(
new byte[]{(byte) 0xd5,(byte) 0xc5},
Charset.forName("gbk")
);
这时,byte数组转换为char数组:
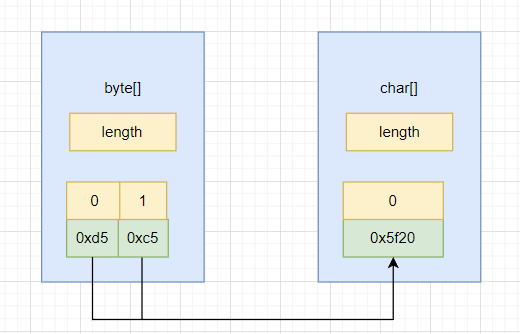
gbk字符集将两个字节看作一个汉字,两个byte就会被转换为一个char 张
如果使用utf-8编码,就是三个字节对应一个汉字:
String str = new String(
new byte[]{(byte) 0xe5, (byte) 0xbc, (byte) 0xa0},
Charset.forName("utf-8")
);
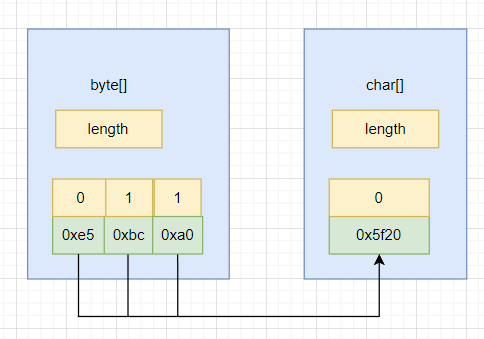
java中的char字符都是unicode编码的,从外界不同的编码(gbk、utf-8)传过来的byte数组最终到java的char都统一了
int[] 创建字符串
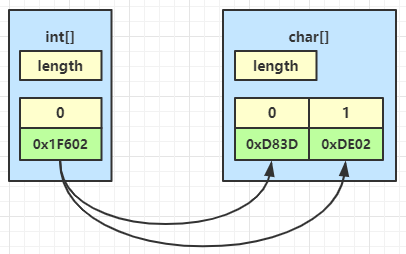
有时候我们还需要用两个 char 表示一个字符,比如 这个笑哭的字符,它用 unicode 编码表示为 0x1F602,存储范围已经超过了 char 能表示的最大值 0xFFFF,因此需要使用 int[] 来构造这样的字符串,如下
String s = new String(new int[]{0x1F602}, 0, 1); // 从第0个元素开始读取,转换为字符串中1个字符
参考
两个char合在一起表示了这个字符
从已有字符串创建
直接看源码
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
这种最为简单,但要注意是两个字符串对象引用同一个 char[] 对象
String s1 = new String(new char[]{'a', 'b', 'c'});
String s2 = new String(s1);
内存结构如下
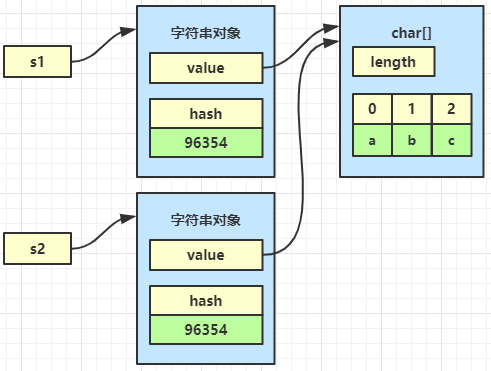
可以节约一些内存
字面量创建
最熟悉的是这种字面量的方式:
public static void main(String[] args) {
String s = "abc";
}
"abc" 被叫做字符串字面量(英文 Literal),但恰恰是这种方式其实奥妙最多:
- 非对象
- 懒加载
- 不重复
非对象
严格地说,字面量在代码运行到它所在语句之前,它还不是字符串对象
上面的代码在还没执行到String s = “abc” 之前,”abc” 仅仅是一个符号,并不是一个对象;只有运行到这一行代码才变成了对象
要理解从字面量变成字符串对象的过程,需要从字节码的角度来分析
在上面的 java 代码被编译为 class 文件后,"abc" 存储于【类文件常量池】中
Constant pool: // 常量池
#1 = Methodref #19.#41 // java/lang/Object."<init>":()V
#2 = String #42 // abc
...
需要调用一个方法时,需要确定方法的入口地址,就要从常量池中寻找;需要使用的字面量也会在常量池中,常量池包含了程序需要的数据
当 class 完成类加载之后:
- 常量池被加载到运行时常量池,
"abc"这个字面量被存储于【运行时常量池】(归属于方法区)中,其中 #1 #2 都会被翻译为运行时真正的内存地址 - 字节码指令被加载到方法区
执行main方法,会在启动主线程,在栈内存分配栈帧,程序计数器记录执行方法区中的哪条字节码指令
再看一下 class 中 main 方法的字节码
public static void main(java.lang.String[]); // 字节码指令
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: ldc #2 // String abc
2: astore_1
3: return
...
将来 main 方法被调用时,就会执行里面的字节码指令
0: ldc #2 // String abc
2: astore_1
3: return
ldc #2 就是到运行时常量池中找到 #2 的内存地址,找到 "abc" 这个字面量,再根据它创建一个char []数组 ,创建一个String 对象。也就是说执行完ldc才会创建出字符串对象。
astore_1 :将刚刚创建的字符串对象地址赋值给局部变量s
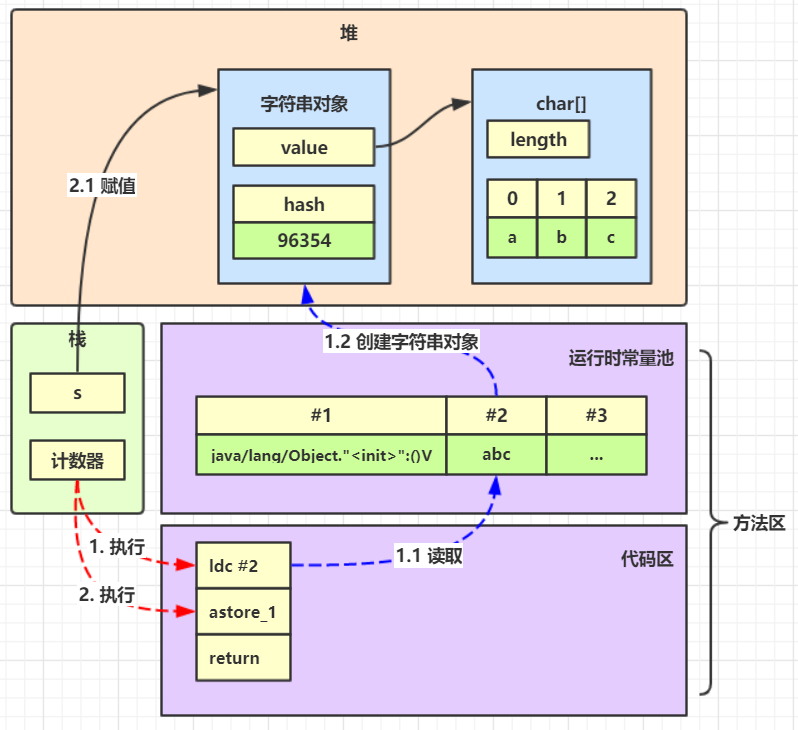
懒加载
当第一次用到 "abc" 字面量时(也就是执行到 ldc #2 时) ,才会创建对应的字符串对象
如何验证呢?
例如有如下代码
System.out.println();
System.out.println("1"); // 断点1 2411
System.out.println("2"); // 断点2 2412
System.out.println("3"); // 断点3
可以给每行语句加上断点,然后用 idea 的 debug 界面中的 memory 工具来查看字符串对象的数量
刚开始在断点1 处,其它类中创建的字符串对象有 2411 个
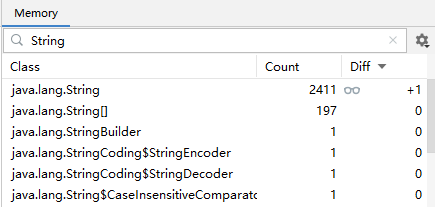
执行到断点2 处,这时新创建了 "1" 对应的字符串对象,个数为 2412
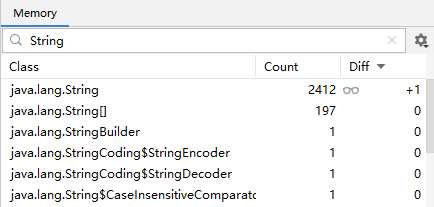
执行到断点3 处,这时新创建了 "2" 对应的字符串对象,个数为 2413
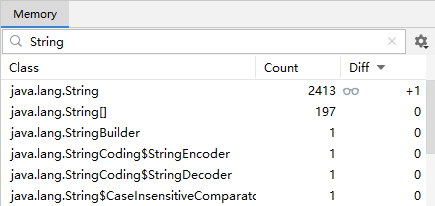
不重复
同一个类中的值相同字面量,其实只有一份
public class TestString1 {
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
}
}
常量池为
Constant pool:
#1 = Methodref #25.#48 // java/lang/Object."<init>":()V
#2 = String #49 // abc
...
相同的字面量”abc”在类常量池中只有一份
对应的字节码为
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: ldc #2 // String abc
2: astore_1
3: ldc #2 // String abc
5: astore_2
6: return
...
可以看到 "abc" 这个字面量虽然出现了 2 次,但实际上都是对应着常量池中 #2 这个地址
ldc #2 这条字节码指令并不会重复执行,两个局部变量引用到了同一个String对象
如果是不同类中的 "abc" 呢?【类文件常量池】包括【运行时常量池】都是以类为单位的
例如,另一个类中
public class TestString2 {
public static void main(String[] args) {
String s1 = "a";
String s2 = "abc";
}
}
对应的常量池
Constant pool:
#1 = Methodref #5.#22 // java/lang/Object."<init>":()V
#2 = String #23 // a
#3 = String #24 // abc
可以看到在这个类中,"abc" 对应的常量池的编号是 # 3,与 TestString1 中的已经不同
这时候【字面量】是两份,而【字符串对象】会有几个呢?
我们来做个实验,把刚才的代码做个改写
public class TestString1 {
public static void main(String[] args) {
String s1 = "abc"; // 字符串对象 "abc"
String s2 = "abc"; // 字符串对象 "abc"
TestString2.main(new String[]{s1, s2});
}
}
public class TestString2 {
public static void main(String[] args) { // args[0] "abc", args[1] "abc"
String s1 = "a";
String s2 = "abc";
System.out.println(args[0] == s2);
System.out.println(args[1] == s2); //s2 和 args[0] 和 args[1] 都指向了同一个对象
}
}
运行结果
true
true
拼接创建
例1
String s = "a" + "b";
例2
final String x = "b";
String s = "a" + x;
例3
String x = "b";
String s = "a" + x;
例4
String s = "a" + 1;
例1和例2 的原理是相同的,例3和例4不同
例1
String s = "a" + "b";
常量池
Constant pool:
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
#2 = String #21 // ab
...
主方法
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: ldc #2 // String ab
2: astore_1
3: return
...
可以看到,其实并没有真正的【拼接】操作发生,从源码编译为字节码时,javac 就已经把 “a” 和 “b” 串在一起了,这是一种编译期的优化处理
例2
final String x = "b";
String s = "a" + x;
常量池
Constant pool:
#1 = Methodref #5.#22 // java/lang/Object."<init>":()V
#2 = String #23 // b
#3 = String #24 // ab
...
主方法
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: ldc #2 // String b final b
2: astore_1
3: ldc #3 // String ab
5: astore_2
6: return
...
可以看到,还是没有真正的【拼接】操作发生,final 意味着 x 的值不可改变,因此其它引用 x 的地方都可以安全地被替换为 “b”,而不用担心 x 被改变,从源码编译为字节码时,javac 就也进行了优化,把所有出现 x 的地方都替换成为了 “b”
那么,什么是真正的【拼接】操作呢?看一下例3 反编译后的结果
String x = "b";
String s = "a" + x; //变量的值会改变,并不能安全的直接优化为ab
常量池
Constant pool:
#1 = Methodref #9.#26 // java/lang/Object."<init>":()V
#2 = String #27 // b
#3 = Class #28 // java/lang/StringBuilder
#4 = Methodref #3.#26 // java/lang/StringBuilder."<init>":()V
#5 = String #29 // a
...
可以看到常量池中并没有 ab 字面量
主方法
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: ldc #2 // String b
2: astore_1
3: new #3 // class java/lang/StringBuilder
6: dup
7: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
10: ldc #5 // String a
12: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
15: aload_1
16: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
22: astore_2
23: return
翻译成人能读懂的就是
String x = "b";
String s = "a" + x;
String x = "b";
String s = new StringBuilder().append("a").append(x).toString();
StringBuilder 的 toString() 方法又是怎么实现的呢?
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {
// 从 AbstractStringBuilder 继承的属性,方便阅读加在此处
char[] value;
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
}
可以看到,本质上就是根据 StringBuilder 维护的 char[] 创建了新的 String 对象
所以JDK1.8时, + 两边如果有非final的变量字符串拼接的效率比较低,每次都会新建一个StringBuilder对象来拼接字符串,并且String x = “b” ,String s = “a” + x,”a” 和 “b” 会新建两个个字符串对象;再加上StringBuilder对象,最后才得到String对象;并且这个String对象也是new创建出的
JDK9之后的改变
从 JDK 9 开始,String 的内部存储方式、以及拼接方式又发生了较大的改变
- 不再用 char[] 存储字符,改为了 byte[],目的是更节约内存
- 使用 invokedynamic 指令扩展了字符串的拼接的实现方式
内存结构改变
例如,字符串中仅有拉丁字符
String s = new String(new byte[]{97, 98, 99});
可以节省3个字节
例如,字符串中有中文字符
String s = new String(
new byte[]{(byte) 0xd5, (byte) 0xc5},
Charset.forName("gbk")
);
汉字的unicode编码方式占用两个字节,这样和JDK1.7采用char数组存储大小相同
coder属性是用来区分拉丁字符或unicode字符
例如,既有中文字符也有拉丁字符
String s = new String(
new byte[]{(byte) 0xd5, (byte) 0xc5, 97},
Charset.forName("gbk")
);
注意此时的coder也会是1,整个数组都采用unicode字符存储,a也占满了两个字节
总结:只有在所有字符都是拉丁字符才会节省内存
拼接方式改变
例如
public static void main(String[] args) {
String x = "b";
String s = "a" + x;
}
JDK8以下采用StringBuilder进行拼接
常量池
Constant pool:
#1 = Methodref #5.#22 // java/lang/Object."<init>":()V
#2 = String #23 // b
...
主方法
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=3, args_size=1
0: ldc #2 // String b
2: astore_1
3: aload_1
4: invokedynamic #3, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;)Ljava/lang/String;
9: astore_2
10: return
...
通过invokedynamic方法动态的反射调用拼接字符串的方法
直接跟 invokedynamic 对应的字节码比较难,简化一下:
public static void main(String[] args) throws Throwable {
String x = "b";
// String s = "a" + x;
// 会生成如下等价的字节码
// 编译器会提供 lookup,用来查找 MethodHandle,MethodHandle 反射调用字符串拼接方法
MethodHandles.Lookup lookup = MethodHandles.lookup();
//生成MethodHandler
CallSite callSite = StringConcatFactory.makeConcatWithConstants(
lookup,
// 方法名,不重要,编译器会自动生成
"arbitrary",
// 方法的签名,第一个 String 为返回值类型,之后是入参类型
//字面量和变量的拼接,"a"是常量,只需要一个入参x
MethodType.methodType(String.class, String.class),
// 具体处方格式,其中 \1 意思是变量的占位符,将来被 x 代替
"a\1"
);
// callSite.getTarget() 返回的是 MethodHandle 对象,用来反射执行拼接方法
String s = (String) callSite.getTarget().invoke(x);
}
主要是为了对字符串的拼接做各种扩展优化,多了扩展途径。其中最为重要的是 MethodHandle ,它使用了策略模式生成,JDK 提供的所有的策略可以在 StringConcatFactory.Strategy 中找到:
| 策略名 | 内部调用 | 解释 |
|---|---|---|
| BC_SB | 字节码拼接生成 StringBuilder 代码(扩容效率低) | 等价于 new StringBuilder() |
| BC_SB_SIZED | 字节码拼接生成 StringBuilder 代码(减少扩容) | 等价于 new StringBuilder(n) n为预估大小 |
| BC_SB_SIZED_EXACT | 字节码拼接生成 StringBuilder 代码 | 等价于 new StringBuilder(n) n为准确大小 |
| MH_SB_SIZED | MethodHandle 生成 StringBuilder 代码 | 等价于 new StringBuilder(n) n为预估大小 |
| MH_SB_SIZED_EXACT | MethodHandle 生成 StringBuilder 代码 | 等价于 new StringBuilder(n) n为准确大小 |
| MH_INLINE_SIZED_EXACT | MethodHandle 内部使用字节数组直接构造出 String | 默认策略 |
前五种方法采用字节码生成匿名内部类,内部通过StringBuilder完成字符串拼接
如果想改变策略,可以在运行时添加 JVM 参数,例如将策略改为 BC_SB
-Djava.lang.invoke.stringConcat=BC_SB
-Djava.lang.invoke.stringConcat.debug=true
-Djava.lang.invoke.stringConcat.dumpClasses=匿名类导出路径
还有一种选择,是在 javac 编译时仍使用 1.5 的办法 StringBuilder 拼接字符串,而不是采用 invokedynamic,就是在 javac 时加上参数
-XDstringConcat=inline
默认拼接策略
默认策略为 MH_INLINE_SIZED_EXACT,使用字节数组直接构造出 String
例如有下面的字符串拼接代码
String x = "b";
String s = "a" + x + "c" + "d";
使用了 MH_INLINE_SIZED_EXACT 策略后,内部会执行如下等价调用(SIZED后缀会预先估计大小)
String x = "b";
// 预先分配字符串需要的字节数组
byte[] buf = new byte[4];
// 创建新字符串,这时内部字节数组值为 [0,0,0,0]
String s = StringConcatHelper.newString(buf, 0);
//prepend 在下标之前加入
// 执行【拼接】,字符串内部字节数组值为 [97,0,0,0]
StringConcatHelper.prepend(1, buf, "a");
// 执行【拼接】,字符串内部字节数组值为 [97,98,0,0]
StringConcatHelper.prepend(2, buf, x);
// 执行【拼接】,字符串内部字节数组值为 [97,98,99,100]
StringConcatHelper.prepend(4, buf, "cd"); //连续的字面量进行优化
// 到此【拼接完毕】
注意
- StringConcatHelper 对外是不可见的,因此无法直接测试,只能反射测试
- prepend 可以通过getBytes方法直接修改字符串中的 bytes 属性值,他们都是 java.lang 包下的
模仿 BC_SB 策略
模拟其中一种策略的实现过程:以字节码指令生成拼接方法为例
JDK实现是创建一个匿名类,在匿名类内部提供字符串拼接的方法,通过MethodHandle反射调用方法完成拼接
目的:
String x = "hello,";
String y = "world";
String s = x + y;
其中 + 可以被 invokedynamic 优化为多种实现策略,希望 x+y 能够被翻译为对下面方法的调用,JDK也只是将 + 翻译为以下方法的调用
public static String concat(String x, String y) {
return new StringBuilder().append(x).append(y).toString();
}
1. 方法手动生成
提供一个拼接方法
public static String concat(String x, String y) {
return new StringBuilder().append(x).append(y).toString();
}
用 MethodHandle 反射调用
String x = "hello,";
String y = "world";
//查找静态方法
MethodHandle mh = MethodHandles.lookup().findStatic(
TestString4.class, //哪个类
"concat", //方法名
MethodType.methodType(String.class, String.class, String.class) //方法签名
);
String s = (String) mh.invoke(x,y);
System.out.println(s);
输出
hello,world
但这样需要自己提供 concat 方法,而且其参数个数都固定死了,能否动态生成这么一个方法呢,答案是肯定的,为了简化生成逻辑,这里仍然以固定参数为例
JDK为了扩展性会根据变量个数动态生成方法
2. 字节码生成方法
Unsafe 对象访问类
public class UnsafeAccessor {
static Unsafe UNSAFE;
static {
try {
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
UNSAFE = (Unsafe) theUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
可以使用 asm 生成匿名类字节码
public static byte[] dump() {
ClassWriter cw = new ClassWriter(0);
FieldVisitor fv;
MethodVisitor mv;
AnnotationVisitor av0;
cw.visit(52, ACC_PUBLIC + ACC_SUPER, "cn/itcast/string/TestString4", null, "java/lang/Object", null);
cw.visitSource("TestString4.java", null);
{
mv = cw.visitMethod(ACC_PUBLIC, "<init>", "()V", null, null);
mv.visitCode();
Label l0 = new Label();
mv.visitLabel(l0);
mv.visitLineNumber(3, l0);
mv.visitVarInsn(ALOAD, 0);
mv.visitMethodInsn(INVOKESPECIAL, "java/lang/Object", "<init>", "()V", false);
mv.visitInsn(RETURN);
Label l1 = new Label();
mv.visitLabel(l1);
mv.visitLocalVariable("this", "Lcn/itcast/string/TestString4;", null, l0, l1, 0);
mv.visitMaxs(1, 1);
mv.visitEnd();
}
{
mv = cw.visitMethod(ACC_PUBLIC + ACC_STATIC, "concat", "(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;", null, null);
mv.visitCode();
Label l0 = new Label();
mv.visitLabel(l0);
mv.visitLineNumber(9, l0);
mv.visitTypeInsn(NEW, "java/lang/StringBuilder");
mv.visitInsn(DUP);
mv.visitMethodInsn(INVOKESPECIAL, "java/lang/StringBuilder", "<init>", "()V", false);
mv.visitVarInsn(ALOAD, 0);
mv.visitMethodInsn(INVOKEVIRTUAL, "java/lang/StringBuilder", "append", "(Ljava/lang/String;)Ljava/lang/StringBuilder;", false);
mv.visitVarInsn(ALOAD, 1);
mv.visitMethodInsn(INVOKEVIRTUAL, "java/lang/StringBuilder", "append", "(Ljava/lang/String;)Ljava/lang/StringBuilder;", false);
mv.visitMethodInsn(INVOKEVIRTUAL, "java/lang/StringBuilder", "toString", "()Ljava/lang/String;", false);
mv.visitInsn(ARETURN);
Label l1 = new Label();
mv.visitLabel(l1);
mv.visitLocalVariable("x", "Ljava/lang/String;", null, l0, l1, 0);
mv.visitLocalVariable("y", "Ljava/lang/String;", null, l0, l1, 1);
mv.visitMaxs(2, 2);
mv.visitEnd();
}
cw.visitEnd();
return cw.toByteArray();
}
这么多字节码主要目的仅仅是生成一个匿名类的字节码(不是对象),其中包括了拼接方法
public static String concat(String x, String y) {
return new StringBuilder().append(x).append(y).toString();
}
接下来就可以生成匿名类,供 MethodHandler 反射调用
// 生成匿名类所需字节码
byte[] bytes = dump();
// 根据字节码生成匿名类.class,类加载
Class<?> innerClass = UnsafeAccessor.UNSAFE
.defineAnonymousClass(TestString4.class, bytes, null);//匿名类的外部类,组成类的byte数组
// 确保匿名类初始化
UnsafeAccessor.UNSAFE.ensureClassInitialized(innerClass);
// 找到匿名类中 String concat(String x, String y),不在外部类中查找
MethodHandle mh = MethodHandles.lookup().findStatic(
innerClass,
"concat", //dump确定的
MethodType.methodType(String.class, String.class, String.class)
);
最终就可以使用该 MethodHandle 反射完成字符串拼接了
String x = "hello,";
String y = "world";
String s = (String) mh.invoke(x, y);
输出
hello,world
JDK 9 当然做的更为专业,可以适配生成不同的参数个数、类型的 MethodHandle,但原理就是这样。
StringTable
家养与野生
-
字面量方式创建的字符串,会放入 StringTable 中,StringTable 管理的字符串,才具有不重复的特性,这种就像是家养的
-
而 char[],byte[],int[],String,以及 + 方式本质上都是使用 new 来创建,它们都是在堆中创建新的字符串对象,不会考虑字符串重不重复,这种就像是野生的,野生字符串的缺点就是如果存在大量值相同的字符串,对内存占用非常严重
如何保证家养的字符串对象不重复呢?JDK 使用了 StringTable 来解决,StringTable 是采用 c++ 代码编写的,数据结构上就是一个 hash 表,字符串对象就充当 hash 表中的 key,key 的不重复性,是 hash 表的基本特性
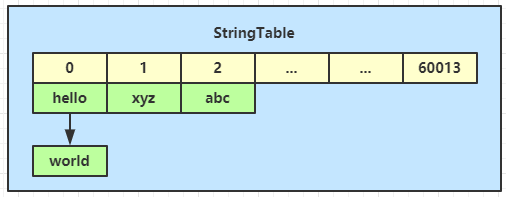
当代码运行到一个字面量 “abc” 时,会首先检查 StringTable 中有没有相同的 key,如果没有,创建新字符串对象加入;否则直接返回已有的字符串对象
收留野生字符串
野生的字符串也有机会得到教育
字符串提供了 intern 方法来实现去重,让字符串对象有机会受到 StringTable 的管理
public native String intern();
它会尝试将调用者放入 StringTable
如果 StringTable 中已有
String x = ...;
String s = x.intern();
总会返回家养的 String 对象
sequenceDiagram participant x as x participant s as s participant st as StringTable x ->> st : intern() st ->> st : 如果已有 st –>> s : 返回 StringTable 对象
例子
String x = new String(new char[]{'a', 'b', 'c'}); // 野生的
String y = "abc"; // 将 "abc" 加入 StringTable
String z = x.intern(); // 已有,返回 StringTable 中 "abc",即 y
System.out.println(z == y);
System.out.println(z == x);
输出
true
false
如果 StringTable 中没有(1.7 以上 JDK 的做法)
String x = ...;
String s = x.intern();
sequenceDiagram participant x as x participant s as s participant st as StringTable x ->> st : intern() st ->> st : 如果没有 st ->> st : 将x引用的对象加入 st –>> s : 返回 StringTable 对象
例子
String x = new String(new char[]{'a', 'b', 'c'}); // 野生的
String z = x.intern(); // 野生的 x 加入 StringTable,StringTable 中有了 "abc"
String y = "abc"; // 已有,不会产生新的对象,用的是 StringTable 中 "abc"
System.out.println(z == x);
System.out.println(z == y);
输出
true
true
注意:JDK1.7以上是将x.intern() 调用者直接加入StringTable,然后再将本身返回
如果 StringTable 中没有(1.6 JDK 的做法)
String x = ...;
String s = x.intern();
sequenceDiagram participant x as x participant s as s participant st as StringTable x ->> st : intern() st ->> st : 如果没有 st ->> st : 将x引用的对象复制 st ->> st : 将复制后的对象加入 st –>> s : 返回 StringTable 对象
例子,代码同上面 1.7 相同
String x = new String(new char[]{'a', 'b', 'c'}); // 野生的
String z = x.intern(); // 野生的 x 被复制后加入 StringTable,StringTable 中有了 "abc"
String y = "abc"; // 已有,不会产生新的对象,用的是 StringTable 中 "abc"
System.out.println(z == x);
System.out.println(z == y);
输出
false
true
去重的好处
/**
* 演示 intern 减少内存占用
*/
public class Demo1 {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
address.add(line.intern());
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
}
}
linux.words中共有48w个不重复的的单词,读取10次,程序中有48w * 9 个重复的字符串对象,intern可以去重
StringTable 的位置(1.6)
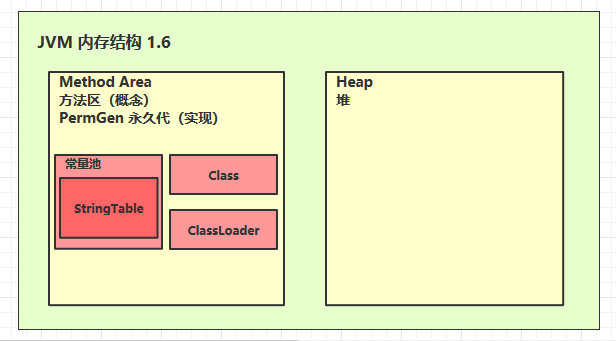
永久代内存回收触发较晚,一般fullGC才会触发永久代垃圾回收
StringTable 的位置(1.8)
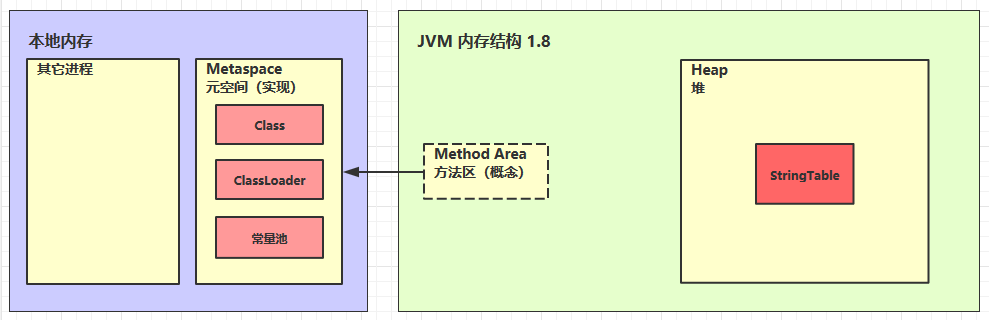
堆内存垃圾回收时机比方法区早,速度也比fullGC快很多
如何证明
- 1.6 不断将字符串用 intern 加入 StringTable,最后撑爆的是永久代内存,为了让错误快速出现,将永久代内存设置的小一些:
-XX:MaxPermSize=10m,最终会出现java.lang.OutOfMemoryError: PermGen space - 1.8 不断将字符串用 intern 加入 StringTable,最后撑爆的是堆内存,为了让错误快速出现,将堆内存设置的小一些:
-Xmx10m -XX:-UseGCOverheadLimit后一个虚拟机参数是避免 GC 频繁引起其他错误而不是我们期望的java.lang.OutOfMemoryError: Java heap space
代码
/**
* 演示 StringTable 位置
* 在jdk8下设置 -Xmx10m -XX:-UseGCOverheadLimit
* 在jdk6下设置 -XX:MaxPermSize=10m
*/
public class Demo2 {
public static void main(String[] args) throws InterruptedException {
List<String> list = new ArrayList<String>();
int i = 0;
try {
for (int j = 0; j < 260000; j++) {
list.add(String.valueOf(j).intern());
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
查阅一下 jdk 的源码
// string_or_null 字符串对象
// name 字符串原始指针
// len 字符串长度
oop StringTable::intern(Handle string_or_null, jchar* name,
int len, TRAPS) {
// 获取字符串的 hash 值
unsigned int hashValue = hash_string(name, len);
// 算出 hash table 桶下标
int index = the_table()->hash_to_index(hashValue);
// 看字符串在 hash table 中有没有
oop found_string = the_table()->lookup(index, name, len, hashValue);
// 如果有,直接返回(避免重复加入)
if (found_string != NULL) {
// 确保该字符串对象没有被垃圾回收
ensure_string_alive(found_string);
return found_string;
}
debug_only(StableMemoryChecker smc(name, len * sizeof(name[0])));
assert(!Universe::heap()->is_in_reserved(name),
"proposed name of symbol must be stable");
Handle string;
// try to reuse the string if possible
if (!string_or_null.is_null()) {
string = string_or_null;
} else {
// 根据 unicode 创建【字符串对象 string】
string = java_lang_String::create_from_unicode(name, len, CHECK_NULL);
}
#if INCLUDE_ALL_GCS
if (G1StringDedup::is_enabled()) {
// Deduplicate the string before it is interned. Note that we should never
// deduplicate a string after it has been interned. Doing so will counteract
// compiler optimizations done on e.g. interned string literals.
G1StringDedup::deduplicate(string());
}
#endif
// Grab the StringTable_lock before getting the_table() because it could
// change at safepoint.
oop added_or_found;
{
MutexLocker ml(StringTable_lock, THREAD);
// 将【字符串对象 string】加入 hash table
added_or_found = the_table()->basic_add(index, string, name, len,
hashValue, CHECK_NULL);
}
ensure_string_alive(added_or_found);
return added_or_found;
}
其中 lookup 的定义为
// index 桶下标
// name 字符串原始指针
// len 字符串长度
// hash 哈希码
oop StringTable::lookup(int index, jchar* name,
int len, unsigned int hash) {
int count = 0;
//遍历链表
for (HashtableEntry<oop, mtSymbol>* l = bucket(index); l != NULL; l = l->next()) {
count++;
if (l->hash() == hash) { //hash相同
if (java_lang_String::equals(l->literal(), name, len)) { //比较字符串对象
return l->literal(); //相等就返回
}
}
}
// 如果链表过长,需要 rehash
if (count >= rehash_count && !needs_rehashing()) {
_needs_rehashing = check_rehash_table(count);
}
return NULL;
}
这样找到的字符串对象就是found_string;
rehash并不会对hash表扩容,而是对hash表中的字符串重新计算哈希值,来让字符串在hash表中分布的比较均匀
其中 basic_add 的定义为
// index_arg 桶下标
// string 字符串对象
// name 字符串原始指针
// len 字符串长度
oop StringTable::basic_add(int index_arg, Handle string, jchar* name,
int len, unsigned int hashValue_arg, TRAPS) {
assert(java_lang_String::equals(string(), name, len),
"string must be properly initialized");
// Cannot hit a safepoint in this function because the "this" pointer can move.
No_Safepoint_Verifier nsv;
// Check if the symbol table has been rehashed, if so, need to recalculate
// the hash value and index before second lookup.
unsigned int hashValue;
int index;
if (use_alternate_hashcode()) {
hashValue = hash_string(name, len);
index = hash_to_index(hashValue);
} else {
hashValue = hashValue_arg;
index = index_arg;
}
// Since look-up was done lock-free, we need to check if another
// thread beat us in the race to insert the symbol.
oop test = lookup(index, name, len, hashValue); // calls lookup(u1*, int)
if (test != NULL) {
// Entry already added
//
return test;
}
// 要添加的字符串在hash表中确实没有
// 构造新的 HashtableEntry 节点
HashtableEntry<oop, mtSymbol>* entry = new_entry(hashValue, string());
// 加入链表
add_entry(index, entry);
// 返回字符串对象
return string();
}
还是会调用lookup查找一次,如果查找不到再构造一个HashtableEntry节点加入
G1 去重
intern方法需要手动调用,比较繁琐
果你使用的 JDK 8u20,那么可以使用下面的 JVM 参数开启 G1 垃圾回收器,并开启字符串去重功能
-XX:+UseG1GC -XX:+UseStringDeduplication
开启G1垃圾回收器,开启字符串去重功能;G1在回收垃圾时顺便完成字符串去重
原理是让多个字符串对象引用同一个 char[] 来达到节省内存的目的
特点
- 由 G1 垃圾回收器在 minor gc 阶段自动分析优化,不需要程序员自己干预
- 只有针对那些多次回收还不死的字符串对象,才会进行去重优化,可以通过
-XX:StringDeduplicationAgeThreshold=n来调整几次回收,默认n = 3 - 可以通过
-XX:+PrintStringDeduplicationStatistics查看 G1 去重的统计信息 - 与调用 intern 去重相比,G1 去重好处在于自动,但缺点是即使 char[] 不重复,但字符串对象本身还要占用一定内存(对象头、value引用、hash),intern 去重是字符串对象只存一份,更省内存
家的大小
StringTable 足够大,才能发挥性能优势,大意味着 String 在 hash 表中冲突减少,链表短,性能高。
可以通过 -XX:+PrintStringTableStatistics 来查看 StringTable 的大小,JDK 8 中它的默认大小为 60013
要注意 StringTable 底层的 hash 表在 JVM 启动后大小就固定不变了
这个 hash 表可以在链表长度太长时进行 rehash,但不是利用扩容实现的 rehash,而是通过重新计算字符串的 hash 值来让它们分布均匀
如果想在启动前调整 StringTable 的大小,可以通过 -XX:StringTableSize=n 来指定
代码
/**
* 演示串池大小对性能的影响
* -XX:+PrintStringTableStatistics -XX:StringTableSize=1009
*/
public class Demo3 {
public static void main(String[] args) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
}
字符串之死
字符串也是一个对象,只要是对象,终究逃不过死亡的命运。字符串对象与其它 Java 对象一样,只要失去了利用价值,就会被垃圾回收,无论是野生字符串,还是家养字符串
怎么证明家养的字符串也能被垃圾回收呢,可以用以下 JVM 参数来查看
-XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
代码
/**
* 演示 StringTable 垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
*/
public class Demo4 {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 100000; j++) { // j=100, j=10000
String.valueOf(j).intern();
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
面试题讲解
1. 判断输出
String str1 = "string"; // 家
String str2 = new String("string"); // 野生
String str3 = str2.intern(); // 返回str1,并将str2加入stringtable,
System.out.println(str1==str2);// false
System.out.println(str1==str3);// true
//如果是jdk1.6,intern会将str2复制一份加入stringtable,并不会将str2加入
2. 判断输出
String baseStr = "baseStr"; //home
final String baseFinalStr = "baseStr"; //home
String str1 = "baseStr01"; // home
String str2 = "baseStr"+"01"; // home
String str3 = baseStr + "01"; // 野生
String str4 = baseFinalStr+"01";// home
String str5 = new String("baseStr01").intern(); // home
System.out.println(str1 == str2);//#3 true
System.out.println(str1 == str3);//#4 false new创建
System.out.println(str1 == str4);//#5 true
System.out.println(str1 == str5);//#6 true
3. 判断输出(注意版本)
String str2 = new String("str") + new String("01"); //野生
str2.intern(); //jdk1.6 str2还是野生。jdk1.7家养
String str1 = "str01"; //家养
System.out.println(str2==str1);//#7 jdk1.6 false jdk1.7 true
4. 判断输出
String str1 = "str01"; //家养
String str2 = new String("str") + new String("01"); //野生
str2.intern(); //尝试加入,但是已有
System.out.println(str2 == str1);//#8
5. String s = new String(“xyz”),创建了几个String Object?
从字面量 “xyz” 在stringtable中创建一个字符串对象,从已有的字符串对象再创建一个字符串对象,引用了同一个byte数组
6. 判断输出
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2); //
7. 判断输出
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println(s1 == s2); //
8. 判断输出
String s1 = "abc";
String s2 = "a";
String s3 = "bc";
String s4 = s2 + s3;
System.out.println(s1 == s4); //false
9. 判断输出
String s1 = "abc";
final String s2 = "a";
final String s3 = "bc";
String s4 = s2 + s3;
System.out.println(s1 == s4);//true
10. 判断输出
String s = new String("abc"); // 野生
String s1 = "abc"; // home
String s2 = new String("abc"); // 野生
System.out.println(s == s1.intern()); // false
System.out.println(s == s2.intern()); // false
System.out.println(s1 == s2.intern()); // true