Odoo第三方模块V16.0>V17.0记录
升级第三方模块
借助OCA的odoo-module-migrator工具来进行模块代码升级
# 进入容器
exec --user root -it odoo17 /bin/bash
apt update
apt install -y git
# 在容器内执行
cd /tmp
git clone https://github.com/OCA/odoo-module-migrator.git
cd odoo-module-migrator
pip3 install -r requirements.txt
# 查看命令行帮助
python3 -m odoo_module_migrate -h
# 升级模块
python3 -m odoo_module_migrate -d /mnt/extra-addons/ -m module_name -i 12.0 -t 17.0
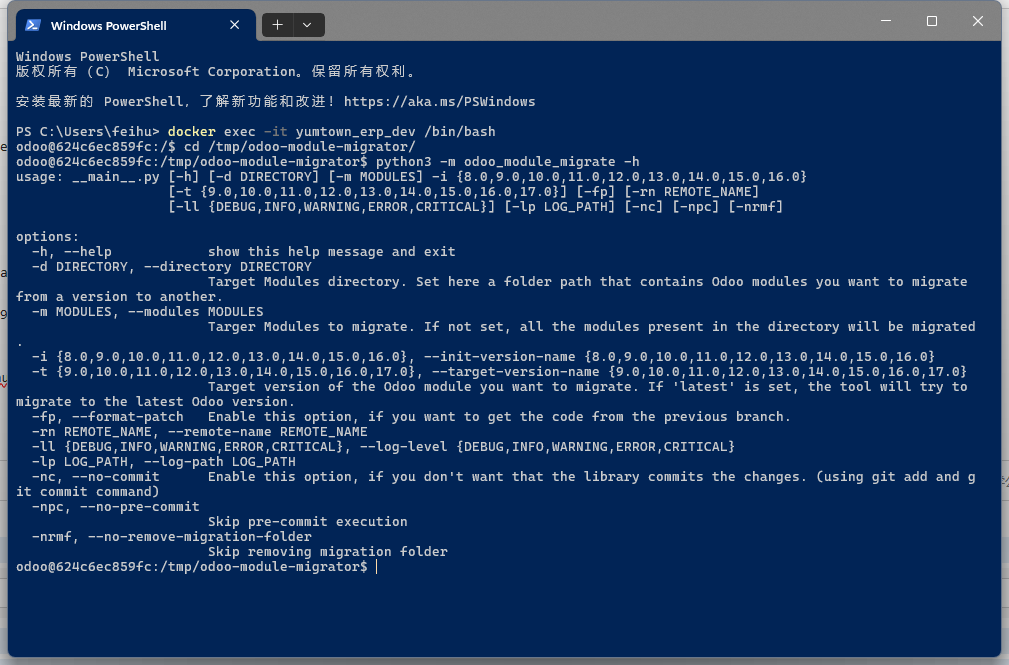
升级模块之后会自动commit变更
升级视图
Odoo17移除了视图上的attrs与states,改为使用readonly,invisible,required等属性,这样会导致一些视图无法正常显示,需要手动修改视图文件(PR:https://github.com/odoo/odoo/pull/104741)
PR正文末尾提到
Script to convert your files: https://github.com/Gorash/odoo-view-pocalypse-convert
通过应用这个patch得到一个打好补丁的convert.py,然后把它复制到容器内替换odoo/tools/convert.py
# 进入容器
exec --user root -it odoo17 /bin/bash
# 容器内
cd /usr/lib/python3/dist-packages/odoo/tools/
mv convert.py convert.py_bak
# 退出容器,把打好补丁的convert.py复制进去
docker cp E:\convert.py odoo17:/usr/lib/python3/dist-packages/odoo/tools/
之后在升级模块的时候它会转换xml文件中的attrs与states
convert.py
感谢jeffery大大帮忙patch
# -*- coding: utf-8 -*-
# Part of Odoo. See LICENSE file for full copyright and licensing details.
__all__ = [
'convert_file', 'convert_sql_import',
'convert_csv_import', 'convert_xml_import'
]
import ast
import base64
import io
import logging
import os.path
import pprint
import re
import subprocess
import warnings
from datetime import datetime, timedelta
from dateutil.relativedelta import relativedelta
import pytz
from lxml import etree, builder
try:
import jingtrang
except ImportError:
jingtrang = None
import odoo
from. import mute_logger
from . import pycompat
from .config import config
from .misc import file_open, unquote, ustr, SKIPPED_ELEMENT_TYPES
from .translate import _
from .template_inheritance import locate_node
from odoo import SUPERUSER_ID, api
from odoo.exceptions import ValidationError
_logger = logging.getLogger(__name__)
from .view_validation import get_expression_field_names
from .safe_eval import safe_eval as s_eval, pytz, time
safe_eval = lambda expr, ctx={}: s_eval(expr, ctx, nocopy=True)
class ParseError(Exception):
...
class RecordDictWrapper(dict):
"""
Used to pass a record as locals in eval:
records do not strictly behave like dict, so we force them to.
"""
def __init__(self, record):
self.record = record
def __getitem__(self, key):
if key in self.record:
return self.record[key]
return dict.__getitem__(self, key)
def _get_idref(self, env, model_str, idref):
idref2 = dict(idref,
Command=odoo.fields.Command,
time=time,
DateTime=datetime,
datetime=datetime,
timedelta=timedelta,
relativedelta=relativedelta,
version=odoo.release.major_version,
ref=self.id_get,
pytz=pytz)
if model_str:
idref2['obj'] = env[model_str].browse
return idref2
def _fix_multiple_roots(node):
"""
Surround the children of the ``node`` element of an XML field with a
single root "data" element, to prevent having a document with multiple
roots once parsed separately.
XML nodes should have one root only, but we'd like to support
direct multiple roots in our partial documents (like inherited view architectures).
As a convention we'll surround multiple root with a container "data" element, to be
ignored later when parsing.
"""
real_nodes = [x for x in node if not isinstance(x, SKIPPED_ELEMENT_TYPES)]
if len(real_nodes) > 1:
data_node = etree.Element("data")
for child in node:
data_node.append(child)
node.append(data_node)
def _eval_xml(self, node, env):
if node.tag in ('field','value'):
t = node.get('type','char')
f_model = node.get('model')
if node.get('search'):
f_search = node.get("search")
f_use = node.get("use",'id')
f_name = node.get("name")
idref2 = {}
if f_search:
idref2 = _get_idref(self, env, f_model, self.idref)
q = safe_eval(f_search, idref2)
ids = env[f_model].search(q).ids
if f_use != 'id':
ids = [x[f_use] for x in env[f_model].browse(ids).read([f_use])]
_fields = env[f_model]._fields
if (f_name in _fields) and _fields[f_name].type == 'many2many':
return ids
f_val = False
if len(ids):
f_val = ids[0]
if isinstance(f_val, tuple):
f_val = f_val[0]
return f_val
a_eval = node.get('eval')
if a_eval:
idref2 = _get_idref(self, env, f_model, self.idref)
try:
return safe_eval(a_eval, idref2)
except Exception:
logging.getLogger('odoo.tools.convert.init').error(
'Could not eval(%s) for %s in %s', a_eval, node.get('name'), env.context)
raise
def _process(s):
matches = re.finditer(br'[^%]%\((.*?)\)[ds]'.decode('utf-8'), s)
done = set()
for m in matches:
found = m.group()[1:]
if found in done:
continue
done.add(found)
id = m.groups()[0]
if not id in self.idref:
self.idref[id] = self.id_get(id)
# So funny story: in Python 3, bytes(n: int) returns a
# bytestring of n nuls. In Python 2 it obviously returns the
# stringified number, which is what we're expecting here
s = s.replace(found, str(self.idref[id]))
s = s.replace('%%', '%') # Quite weird but it's for (somewhat) backward compatibility sake
return s
if t == 'xml':
_fix_multiple_roots(node)
return '<?xml version="1.0"?>\n'\
+_process("".join(etree.tostring(n, encoding='unicode') for n in node))
if t == 'html':
return _process("".join(etree.tostring(n, method='html', encoding='unicode') for n in node))
data = node.text
if node.get('file'):
with file_open(node.get('file'), 'rb', env=env) as f:
data = f.read()
if t == 'base64':
return base64.b64encode(data)
# after that, only text content makes sense
data = pycompat.to_text(data)
if t == 'file':
from ..modules import module
path = data.strip()
if not module.get_module_resource(self.module, path):
raise IOError("No such file or directory: '%s' in %s" % (
path, self.module))
return '%s,%s' % (self.module, path)
if t == 'char':
return data
if t == 'int':
d = data.strip()
if d == 'None':
return None
return int(d)
if t == 'float':
return float(data.strip())
if t in ('list','tuple'):
res=[]
for n in node.iterchildren(tag='value'):
res.append(_eval_xml(self, n, env))
if t=='tuple':
return tuple(res)
return res
elif node.tag == "function":
model_str = node.get('model')
model = env[model_str]
method_name = node.get('name')
# determine arguments
args = []
kwargs = {}
a_eval = node.get('eval')
if a_eval:
idref2 = _get_idref(self, env, model_str, self.idref)
args = list(safe_eval(a_eval, idref2))
for child in node:
if child.tag == 'value' and child.get('name'):
kwargs[child.get('name')] = _eval_xml(self, child, env)
else:
args.append(_eval_xml(self, child, env))
# merge current context with context in kwargs
kwargs['context'] = {**env.context, **kwargs.get('context', {})}
# invoke method
return odoo.api.call_kw(model, method_name, args, kwargs)
elif node.tag == "test":
return node.text
def nodeattr2bool(node, attr, default=False):
if not node.get(attr):
return default
val = node.get(attr).strip()
if not val:
return default
return val.lower() not in ('0', 'false', 'off')
class xml_import(object):
def get_env(self, node, eval_context=None):
uid = node.get('uid')
context = node.get('context')
if uid or context:
return self.env(
user=uid and self.id_get(uid),
context=context and {
**self.env.context,
**safe_eval(context, {
'ref': self.id_get,
**(eval_context or {})
})
}
)
return self.env
def make_xml_id(self, xml_id):
if not xml_id or '.' in xml_id:
return xml_id
return "%s.%s" % (self.module, xml_id)
def _test_xml_id(self, xml_id):
if '.' in xml_id:
module, id = xml_id.split('.', 1)
assert '.' not in id, """The ID reference "%s" must contain
maximum one dot. They are used to refer to other modules ID, in the
form: module.record_id""" % (xml_id,)
if module != self.module:
modcnt = self.env['ir.module.module'].search_count([('name', '=', module), ('state', '=', 'installed')])
assert modcnt == 1, """The ID "%s" refers to an uninstalled module""" % (xml_id,)
def _tag_delete(self, rec):
d_model = rec.get("model")
records = self.env[d_model]
d_search = rec.get("search")
if d_search:
idref = _get_idref(self, self.env, d_model, {})
try:
records = records.search(safe_eval(d_search, idref))
except ValueError:
_logger.warning('Skipping deletion for failed search `%r`', d_search, exc_info=True)
d_id = rec.get("id")
if d_id:
try:
records += records.browse(self.id_get(d_id))
except ValueError:
# d_id cannot be found. doesn't matter in this case
_logger.warning('Skipping deletion for missing XML ID `%r`', d_id, exc_info=True)
if records:
records.unlink()
def _tag_function(self, rec):
if self.noupdate and self.mode != 'init':
return
env = self.get_env(rec)
_eval_xml(self, rec, env)
def _tag_menuitem(self, rec, parent=None):
rec_id = rec.attrib["id"]
self._test_xml_id(rec_id)
# The parent attribute was specified, if non-empty determine its ID, otherwise
# explicitly make a top-level menu
values = {
'parent_id': False,
'active': nodeattr2bool(rec, 'active', default=True),
}
if rec.get('sequence'):
values['sequence'] = int(rec.get('sequence'))
if parent is not None:
values['parent_id'] = parent
elif rec.get('parent'):
values['parent_id'] = self.id_get(rec.attrib['parent'])
elif rec.get('web_icon'):
values['web_icon'] = rec.attrib['web_icon']
if rec.get('name'):
values['name'] = rec.attrib['name']
if rec.get('action'):
a_action = rec.attrib['action']
if '.' not in a_action:
a_action = '%s.%s' % (self.module, a_action)
act = self.env.ref(a_action).sudo()
values['action'] = "%s,%d" % (act.type, act.id)
if not values.get('name') and act.type.endswith(('act_window', 'wizard', 'url', 'client', 'server')) and act.name:
values['name'] = act.name
if not values.get('name'):
values['name'] = rec_id or '?'
groups = []
for group in rec.get('groups', '').split(','):
if group.startswith('-'):
group_id = self.id_get(group[1:])
groups.append(odoo.Command.unlink(group_id))
elif group:
group_id = self.id_get(group)
groups.append(odoo.Command.link(group_id))
if groups:
values['groups_id'] = groups
data = {
'xml_id': self.make_xml_id(rec_id),
'values': values,
'noupdate': self.noupdate,
}
menu = self.env['ir.ui.menu']._load_records([data], self.mode == 'update')
for child in rec.iterchildren('menuitem'):
self._tag_menuitem(child, parent=menu.id)
def _tag_record(self, rec, extra_vals=None):
rec_model = rec.get("model")
env = self.get_env(rec)
rec_id = rec.get("id", '')
model = env[rec_model]
if self.xml_filename and rec_id:
model = model.with_context(
install_module=self.module,
install_filename=self.xml_filename,
install_xmlid=rec_id,
)
self._test_xml_id(rec_id)
xid = self.make_xml_id(rec_id)
# in update mode, the record won't be updated if the data node explicitly
# opt-out using @noupdate="1". A second check will be performed in
# model._load_records() using the record's ir.model.data `noupdate` field.
if self.noupdate and self.mode != 'init':
# check if the xml record has no id, skip
if not rec_id:
return None
record = env['ir.model.data']._load_xmlid(xid)
if record:
# if the resource already exists, don't update it but store
# its database id (can be useful)
self.idref[rec_id] = record.id
return None
elif not nodeattr2bool(rec, 'forcecreate', True):
# if it doesn't exist and we shouldn't create it, skip it
return None
# else create it normally
if xid and xid.partition('.')[0] != self.module:
# updating a record created by another module
record = self.env['ir.model.data']._load_xmlid(xid)
if not record:
if self.noupdate and not nodeattr2bool(rec, 'forcecreate', True):
# if it doesn't exist and we shouldn't create it, skip it
return None
raise Exception("Cannot update missing record %r" % xid)
if rec_model == 'ir.ui.view':
_convert_ir_ui_view_modifiers(self, rec, extra_vals=extra_vals)
res = {}
sub_records = []
for field in rec.findall('./field'):
#TODO: most of this code is duplicated above (in _eval_xml)...
f_name = field.get("name")
f_ref = field.get("ref")
f_search = field.get("search")
f_model = field.get("model")
if not f_model and f_name in model._fields:
f_model = model._fields[f_name].comodel_name
f_use = field.get("use",'') or 'id'
f_val = False
if f_search:
idref2 = _get_idref(self, env, f_model, self.idref)
q = safe_eval(f_search, idref2)
assert f_model, 'Define an attribute model="..." in your .XML file!'
# browse the objects searched
s = env[f_model].search(q)
# column definitions of the "local" object
_fields = env[rec_model]._fields
# if the current field is many2many
if (f_name in _fields) and _fields[f_name].type == 'many2many':
f_val = [odoo.Command.set([x[f_use] for x in s])]
elif len(s):
# otherwise (we are probably in a many2one field),
# take the first element of the search
f_val = s[0][f_use]
elif f_ref:
if f_name in model._fields and model._fields[f_name].type == 'reference':
val = self.model_id_get(f_ref)
f_val = val[0] + ',' + str(val[1])
else:
f_val = self.id_get(f_ref, raise_if_not_found=nodeattr2bool(rec, 'forcecreate', True))
if not f_val:
_logger.warning("Skipping creation of %r because %s=%r could not be resolved", xid, f_name, f_ref)
return None
else:
f_val = _eval_xml(self, field, env)
if f_name in model._fields:
field_type = model._fields[f_name].type
if field_type == 'many2one':
f_val = int(f_val) if f_val else False
elif field_type == 'integer':
f_val = int(f_val)
elif field_type in ('float', 'monetary'):
f_val = float(f_val)
elif field_type == 'boolean' and isinstance(f_val, str):
f_val = f_val.lower() not in ('0', 'false', 'off')
elif field_type == 'one2many':
for child in field.findall('./record'):
sub_records.append((child, model._fields[f_name].inverse_name))
if isinstance(f_val, str):
# We do not want to write on the field since we will write
# on the childrens' parents later
continue
elif field_type == 'html':
if field.get('type') == 'xml':
_logger.warning('HTML field %r is declared as `type="xml"`', f_name)
res[f_name] = f_val
if extra_vals:
res.update(extra_vals)
data = dict(xml_id=xid, values=res, noupdate=self.noupdate)
try:
record = model._load_records([data], self.mode == 'update')
except Exception as e:
_logger.error(f'Fail to create: {rec_id!r} from {self.xml_filename}\n{e}')
return None
raise
if rec_id:
self.idref[rec_id] = record.id
if config.get('import_partial'):
env.cr.commit()
for child_rec, inverse_name in sub_records:
self._tag_record(child_rec, extra_vals={inverse_name: record.id})
return rec_model, record.id
def _tag_template(self, el):
# This helper transforms a <template> element into a <record> and forwards it
tpl_id = el.get('id', el.get('t-name'))
full_tpl_id = tpl_id
if '.' not in full_tpl_id:
full_tpl_id = '%s.%s' % (self.module, tpl_id)
# set the full template name for qweb <module>.<id>
if not el.get('inherit_id'):
el.set('t-name', full_tpl_id)
el.tag = 't'
else:
el.tag = 'data'
el.attrib.pop('id', None)
if self.module.startswith('theme_'):
model = 'theme.ir.ui.view'
else:
model = 'ir.ui.view'
record_attrs = {
'id': tpl_id,
'model': model,
}
for att in ['forcecreate', 'context']:
if att in el.attrib:
record_attrs[att] = el.attrib.pop(att)
Field = builder.E.field
name = el.get('name', tpl_id)
record = etree.Element('record', attrib=record_attrs)
record.append(Field(name, name='name'))
record.append(Field(full_tpl_id, name='key'))
record.append(Field("qweb", name='type'))
if 'track' in el.attrib:
record.append(Field(el.get('track'), name='track'))
if 'priority' in el.attrib:
record.append(Field(el.get('priority'), name='priority'))
if 'inherit_id' in el.attrib:
record.append(Field(name='inherit_id', ref=el.get('inherit_id')))
if 'website_id' in el.attrib:
record.append(Field(name='website_id', ref=el.get('website_id')))
if 'key' in el.attrib:
record.append(Field(el.get('key'), name='key'))
if el.get('active') in ("True", "False"):
view_id = self.id_get(tpl_id, raise_if_not_found=False)
if self.mode != "update" or not view_id:
record.append(Field(name='active', eval=el.get('active')))
if el.get('customize_show') in ("True", "False"):
record.append(Field(name='customize_show', eval=el.get('customize_show')))
groups = el.attrib.pop('groups', None)
if groups:
grp_lst = [("ref('%s')" % x) for x in groups.split(',')]
record.append(Field(name="groups_id", eval="[Command.set(["+', '.join(grp_lst)+"])]"))
if el.get('primary') == 'True':
# Pseudo clone mode, we'll set the t-name to the full canonical xmlid
el.append(
builder.E.xpath(
builder.E.attribute(full_tpl_id, name='t-name'),
expr=".",
position="attributes",
)
)
record.append(Field('primary', name='mode'))
# inject complete <template> element (after changing node name) into
# the ``arch`` field
record.append(Field(el, name="arch", type="xml"))
return self._tag_record(record)
def id_get(self, id_str, raise_if_not_found=True):
if id_str in self.idref:
return self.idref[id_str]
res = self.model_id_get(id_str, raise_if_not_found)
return res and res[1]
def model_id_get(self, id_str, raise_if_not_found=True):
if '.' not in id_str:
id_str = '%s.%s' % (self.module, id_str)
return self.env['ir.model.data']._xmlid_to_res_model_res_id(id_str, raise_if_not_found=raise_if_not_found)
def _tag_root(self, el):
for rec in el:
f = self._tags.get(rec.tag)
if f is None:
continue
self.envs.append(self.get_env(el))
self._noupdate.append(nodeattr2bool(el, 'noupdate', self.noupdate))
try:
f(rec)
except ParseError:
raise
except ValidationError as err:
msg = "while parsing {file}:{viewline}\n{err}\n\nView error context:\n{context}\n".format(
file=rec.getroottree().docinfo.URL,
viewline=rec.sourceline,
context=pprint.pformat(getattr(err, 'context', None) or '-no context-'),
err=err.args[0],
)
_logger.debug(msg, exc_info=True)
raise err
raise ParseError(msg) from None # Restart with "--log-handler odoo.tools.convert:DEBUG" for complete traceback
except Exception as e:
raise ParseError('while parsing %s:%s, somewhere inside\n%s' % (
rec.getroottree().docinfo.URL,
rec.sourceline,
etree.tostring(rec, encoding='unicode').rstrip()
)) from e
finally:
self._noupdate.pop()
self.envs.pop()
@property
def env(self):
return self.envs[-1]
@property
def noupdate(self):
return self._noupdate[-1]
def __init__(self, env, module, idref, mode, noupdate=False, xml_filename=None):
self.mode = mode
self.module = module
self.envs = [env(context=dict(env.context, lang=None))]
self.idref = {} if idref is None else idref
self._noupdate = [noupdate]
self.xml_filename = xml_filename
self._tags = {
'record': self._tag_record,
'delete': self._tag_delete,
'function': self._tag_function,
'menuitem': self._tag_menuitem,
'template': self._tag_template,
**dict.fromkeys(self.DATA_ROOTS, self._tag_root)
}
def parse(self, de):
assert de.tag in self.DATA_ROOTS, "Root xml tag must be <openerp>, <odoo> or <data>."
self._tag_root(de)
DATA_ROOTS = ['odoo', 'data', 'openerp']
def convert_file(env, module, filename, idref, mode='update', noupdate=False, kind=None, pathname=None):
if pathname is None:
pathname = os.path.join(module, filename)
ext = os.path.splitext(filename)[1].lower()
with file_open(pathname, 'rb') as fp:
if ext == '.csv':
convert_csv_import(env, module, pathname, fp.read(), idref, mode, noupdate)
elif ext == '.sql':
convert_sql_import(env, fp)
elif ext == '.xml':
convert_xml_import(env, module, fp, idref, mode, noupdate)
elif ext == '.js':
pass # .js files are valid but ignored here.
else:
raise ValueError("Can't load unknown file type %s.", filename)
def convert_sql_import(env, fp):
env.cr.execute(fp.read()) # pylint: disable=sql-injection
def convert_csv_import(env, module, fname, csvcontent, idref=None, mode='init',
noupdate=False):
'''Import csv file :
quote: "
delimiter: ,
encoding: utf-8'''
env = env(context=dict(env.context, lang=None))
filename, _ext = os.path.splitext(os.path.basename(fname))
model = filename.split('-')[0]
reader = pycompat.csv_reader(io.BytesIO(csvcontent), quotechar='"', delimiter=',')
fields = next(reader)
if not (mode == 'init' or 'id' in fields):
_logger.error("Import specification does not contain 'id' and we are in init mode, Cannot continue.")
return
# filter out empty lines (any([]) == False) and lines containing only empty cells
datas = [
line for line in reader
if any(line)
]
context = {
'mode': mode,
'module': module,
'install_module': module,
'install_filename': fname,
'noupdate': noupdate,
}
result = env[model].with_context(**context).load(fields, datas)
if any(msg['type'] == 'error' for msg in result['messages']):
# Report failed import and abort module install
warning_msg = "\n".join(msg['message'] for msg in result['messages'])
raise Exception(_('Module loading %s failed: file %s could not be processed:\n %s') % (module, fname, warning_msg))
def convert_xml_import(env, module, xmlfile, idref=None, mode='init', noupdate=False, report=None):
doc = etree.parse(xmlfile)
schema = os.path.join(config['root_path'], 'import_xml.rng')
relaxng = etree.RelaxNG(etree.parse(schema))
try:
relaxng.assert_(doc)
except Exception:
_logger.exception("The XML file '%s' does not fit the required schema!", xmlfile.name)
if jingtrang:
p = subprocess.run(['pyjing', schema, xmlfile.name], stdout=subprocess.PIPE)
_logger.warning(p.stdout.decode())
else:
for e in relaxng.error_log:
_logger.warning(e)
_logger.info("Install 'jingtrang' for more precise and useful validation messages.")
raise
if isinstance(xmlfile, str):
xml_filename = xmlfile
else:
xml_filename = xmlfile.name
obj = xml_import(env, module, idref, mode, noupdate=noupdate, xml_filename=xml_filename)
obj.parse(doc.getroot())
#######################################################################
def _convert_ir_ui_view_modifiers(self, record_node, extra_vals=None):
rec_id = record_node.get("id", '')
f_model = record_node.find('field[@name="model"]')
f_type = record_node.find('field[@name="type"]')
f_inherit = record_node.find('field[@name="inherit_id"]')
f_arch = record_node.find('field[@name="arch"]')
root = f_arch if f_arch is not None else record_node
ref = f'{rec_id} ({self.xml_filename})'
try:
data_id = f_inherit is not None and f_inherit.get('ref')
inherit = None
if data_id:
if '.' not in data_id:
data_id = f'{self.module}.{data_id}'
inherit = self.env.ref(data_id)
model_name = f_model is not None and f_model.text
if not model_name and inherit:
model_name = inherit.model
if not model_name:
return
view_type = f_type is not None and f_type.text or root[0].tag
if inherit:
view_type = inherit.type
if view_type not in ('kanban', 'tree', 'form', 'calendar', 'setting', 'search'):
return
# load previous arch
arch = None
previous_xml = file_open(self.xml_filename, 'r').read()
match = re.search(rf'''(<record [^>]*id=['"]{rec_id}['"][^>]*>(?:[^<]|<(?!/record>))+</record>)''', previous_xml)
if not match:
_logger.error(f"Can not found {rec_id!r} from {self.xml_filename}")
return
record_xml = match.group(1)
match = re.search(rf'''(<field [^>]*name=["']arch["'][^>]*>((.|\n)+)</field>)''', record_xml)
if not match:
_logger.error(f"Can not found arch of {rec_id!r} from {self.xml_filename}")
return
arch = match.group(2).strip()
# load inherited arch
inherited_root = inherit and etree.fromstring(inherit.get_combined_arch())
head = False
added_data = False
arch_clean = arch
if arch_clean.startswith('<?'):
head, arch_clean = arch_clean.split('\n', 1)
if not arch_clean.startswith('<data>'):
added_data = True
arch_clean = f'<data>{arch_clean}</data>'
root_content = etree.fromstring(arch_clean)
model = self.env[model_name]
try:
arch_result = convert_template_modifiers(self.env, arch_clean, root_content, model, view_type, ref, inherited_root=inherited_root)
except Exception as e:
_logger.error(f"Can not convert: {rec_id!r} from {self.xml_filename}\n{e}")
return
if re.sub(rf'(\n| )*{reg_comment}(\n| )*', '', arch_result) == '<data></data>':
_logger.error(f'No uncommented element found: {rec_id!r} from {self.xml_filename}')
arch_result = arch_result[:6] + '<field position="attributes" help="add to avoid error when convert"/>' + arch_result[6:]
if added_data:
arch_result = arch_result[6:-7]
if head:
arch_result = head + arch_result
if arch_result != arch:
if added_data:
while len(f_arch): f_arch.remove(f_arch[0])
for n in root_content:
f_arch.append(n)
f_arch.text = root_content.text
new_xml = previous_xml.replace(arch, arch_result)
with file_open(self.xml_filename, 'w') as file:
file.write(new_xml)
try:
# test file before save
etree.fromstring(new_xml.encode())
except Exception as e:
_logger.error(f'Wrong view conversion in {rec_id!r} from {self.xml_filename}\n\n{arch}\n\n{e}')
return
except Exception as e:
_logger.error('FAIL ! %s\n%s', ref, e)
import itertools
from odoo import tools
from odoo.tools.misc import unique, str2bool
from odoo.tools import locate_node, mute_logger, apply_inheritance_specs
from odoo.tools.view_validation import get_expression_field_names, _get_expression_contextual_values, get_domain_value_names
from odoo.osv.expression import (
DOMAIN_OPERATORS,
TERM_OPERATORS, AND_OPERATOR, OR_OPERATOR, NOT_OPERATOR,
normalize_domain,
distribute_not,
TRUE_LEAF, FALSE_LEAF,
)
from .safe_eval import _BUILTINS
VALID_TERM_OPERATORS = TERM_OPERATORS + ("<>", "==")
AST_OP_TO_STR = {
ast.Eq: "==",
ast.NotEq: "!=",
ast.Lt: "<",
ast.LtE: "<=",
ast.Gt: ">",
ast.GtE: ">=",
ast.Is: "is",
ast.IsNot: "is not",
ast.In: "in",
ast.NotIn: "not in",
ast.Add: "+",
ast.Sub: "-",
ast.Mult: "*",
ast.Div: "/",
ast.FloorDiv: "//",
ast.Mod: "%",
ast.Pow: "^",
}
class InvalidDomainError(ValueError):
"""Domain can contain only '!', '&', '|', tuples or expression whose returns boolean"""
#######################################################################
def convert_template_modifiers(env, arch, root, rec_model, view_type, ref, inherited_root=None):
"""Convert old syntax (attrs, states...) into new modifiers syntax"""
result = arch
if not arch.startswith('<data>'):
raise ValueError(f'Wrong formating for view conversion. Arch must be wrapped with <data>: {ref!r}\n{arch}')
if inherited_root is None: # this is why it must be False
result = convert_basic_view(arch, root, env, rec_model, view_type, ref)
else:
result = convert_inherit_view(arch, root, env, rec_model, view_type, ref, inherited_root)
if not result.startswith('<data>'):
raise ValueError(f'View conversion failed. Result should had been wrapped with <data>: {ref!r}\n{result}')
root_result = etree.fromstring(result.encode())
# Check for incomplete conversion, those attributes should had been removed by
# convert_basic_view and convert_inherit_view. In case there are some left
# just log an error but keep the converted view in the database/file.
for item in root_result.findall('.//attribute[@name="states"]'):
xml = etree.tostring(item, encoding='unicode')
_logger.error('Incomplete view conversion ("states"): %r\n%s', ref, xml)
for item in root_result.findall('.//attribute[@name="attrs"]'):
xml = etree.tostring(item, encoding='unicode')
_logger.error('Incomplete view conversion ("attrs"): %r\n%s', ref, xml)
for item in root_result.findall('.//*[@attrs]'):
xml = etree.tostring(item, encoding='unicode')
_logger.error('Incomplete view conversion ("attrs"): %r\n%s', ref, xml)
for item in root_result.findall('.//*[@states]'):
xml = etree.tostring(item, encoding='unicode')
_logger.error('Incomplete view conversion ("states"): %r\n%s', ref, xml)
return result
def convert_basic_view(arch, root, env, model, view_type, ref):
updated_nodes, _analysed_nodes = convert_node_modifiers_inplace(root, env, model, view_type, ref)
if not updated_nodes:
return arch
return replace_and_keep_indent(root, arch, ref)
def convert_inherit_view(arch, root, env, model, view_type, ref, inherited_root):
updated = False
result = arch
def get_target(spec):
target_node = None
try:
with mute_logger("odoo.tools.template_inheritance"):
target_node = locate_node(inherited_root, spec)
# target can be None without error
except Exception:
pass
if target_node is None:
clone = etree.tostring(etree.Element(spec.tag, spec.attrib), encoding='unicode')
_logger.info('Target not found for %s with xpath: %s', ref, clone)
return None, view_type, model
parent_view_type = view_type
target_model = model
parent_f_names = []
for p in target_node.iterancestors():
if p.tag == 'field' or p.tag == 'groupby': # subview and groupby in tree view
parent_f_names.append(p.get('name'))
for p in target_node.iterancestors():
if p.tag in ('groupby', 'header'):
# in tree view
parent_view_type = 'form'
break
elif p.tag in ('tree', 'form', 'setting'):
parent_view_type = p.tag
break
for name in reversed(parent_f_names):
try:
field = target_model._fields[name]
target_model = env[field.comodel_name]
except KeyError:
# Model is custom or had been removed. Can convert view without using field python states
if name in target_model._fields:
_logger.warning("Unknown model %s. The <field> modifiers may be incompletely converted. %s", target_model._fields[name].comodel_name, ref)
else:
_logger.warning("Unknown field %s on model %s. The <field> modifiers may be incompletely converted. %s", name, target_model, ref)
target_model = None
break
return target_node, parent_view_type, target_model
specs = []
for spec in root:
if isinstance(spec.tag, str):
if spec.tag == 'data':
specs.extend(c for c in spec)
else:
specs.append(spec)
for spec in specs:
spec_xml = get_targeted_xml_content(spec, result)
if spec.get('position') == 'attributes':
target_node, parent_view_type, target_model = get_target(spec)
updated = convert_inherit_attributes_inplace(spec, target_node, parent_view_type)
xml = etree.tostring(spec, pretty_print=True, encoding='unicode').replace('"', "'").strip()
else:
_target_node, parent_view_type, target_model = get_target(spec)
updated = convert_node_modifiers_inplace(spec, env, target_model, parent_view_type, ref)[0] or updated
xml = replace_and_keep_indent(spec, spec_xml, ref)
try:
with mute_logger("odoo.tools.template_inheritance"):
inherited_root = apply_inheritance_specs(inherited_root, etree.fromstring(xml))
except (ValueError, etree.XPathSyntaxError, ValidationError):
clone = xml.split('>', 1)[0] + '>'
if '%(' in clone:
_logger.info('Can not apply inheritance: %s\nPath: %r', ref, clone )
else:
_logger.error('Can not apply inheritance: %s\nPath: %r', ref, clone )
# updated = True
# xml = xml.replace('--', '- -').replace('--', '- -')
# comment = etree.Comment(f' {xml} ')
# spec.getparent().replace(spec, comment)
# xml = f'<!-- {xml} -->'
except Exception as e:
_logger.error('Can not apply inheritance: %s\nPath: %r', ref, xml.split('>', 1)[0] + '>' )
# updated = True
# xml = xml.replace('--', '- -').replace('--', '- -')
# comment = etree.Comment(f' {xml} ')
# spec.getparent().replace(spec, comment)
# xml = f'<!-- {xml} -->'
if updated:
if spec_xml not in result:
_logger.error('Can not apply inheritance: %s\nPath: %r', ref, xml.split('>', 1)[0] + '>' )
else:
result = result.replace(spec_xml, xml, 1)
return result
def convert_inherit_attributes_inplace(spec, target_node, view_type):
"""
convert inherit with <attribute name="attrs"> + <attribute name="invisible">
The conversion is different if attrs and invisible/readonly/required are modified.
(can replace attributes, or use separator " or " to combine with previous)
migration is idempotent, this eg stay unchanged:
<attribute name="invisible">(aaa)</invisible>
<attribute name="invisible">0</attribute>
<attribute name="invisible">1</attribute>
<attribute name="invisible" add="context.get('aaa')" separator=" or "/>
"""
migrated = False
has_change = False
items = {}
to_remove = set()
node = None
for attr in ('attrs', 'column_invisible', 'invisible', 'readonly', 'required'):
nnode = spec.find(f'.//attribute[@name="{attr}"]')
if nnode is None:
continue
to_remove.add(nnode)
value = nnode.text and nnode.text.strip()
if value not in ('True', 'False', '0', '1'):
node = nnode
if nnode.get('separator') or (value and value[0] == '('):
# previously migrate
migrated = True
break
if attr == 'attrs':
try:
value = value and ast.literal_eval(value) or {'invisible': '', 'readonly': '', 'required': ''}
except Exception as error:
raise ValueError(f'Can not convert "attrs": {value!r}') from error
elif (attr == 'invisible' and view_type == 'tree'
and (value in ('0', '1', 'True', 'False')
or (value.startswith('context') and ' or ' not in value and ' and ' not in value))):
attr = 'column_invisible'
items[attr] = value
if node is None or not items or migrated:
return has_change
index = spec.index(node)
is_last = spec[-1] == node
domain_attrs = items.pop('attrs', {})
all_attrs = list((set(items) | set(domain_attrs)))
all_attrs.sort()
i = len(all_attrs)
next_xml = ''
for attr in all_attrs:
value = items.get(attr)
domain = domain_attrs.get(attr, '')
attr_value = domain_to_expression(domain) if isinstance(domain, list) else str(domain)
i -= 1
elem = etree.Element('attribute', {'name': attr})
if i or not is_last:
elem.tail = spec.text
else:
elem.tail = spec[-1].tail
spec[-1].tail = spec.text
if value and attr_value:
has_change = True
# replace whole expression
if value in ('False', '0'):
elem.text = attr_value
elif value in ('True', '1'):
elem.text = value
else:
elem.text = f'({value}) or ({attr_value})'
else:
inherited_value = target_node.get(attr) if target_node is not None else None
inherited_context = _get_expression_contextual_values(ast.parse(inherited_value.strip(), mode='eval').body) if inherited_value else set()
res_value = value or attr_value or 'False'
if inherited_context:
# replace whole expression if replace record value by record value, or context/parent by context/parent
# <field invisible="context.get('a')"/>
# is replaced
#
# <field attrs="{'invisible': [('b', '=', 1)]}"/> => <field invisible="b == 1"/>
# will be combined
#
# <field invisible="context.get('a')" attrs="{'invisible': [('b', '=', 1)]}"/> => <field invisible="context.get('a') or b == 1"/>
# logged because human control is necessary
context = _get_expression_contextual_values(ast.parse(res_value.strip(), mode='eval').body)
has_record = any(True for v in context if not v.startswith('context.'))
has_context = any(True for v in context if v.startswith('context.'))
inherited_has_record = any(True for v in inherited_context if not v.startswith('context.'))
inherited_has_context = any(True for v in inherited_context if v.startswith('context.'))
if has_record == inherited_has_record and has_context == inherited_has_context:
elem.text = res_value
if attr_value:
has_change = True
elif has_context and not has_record:
elem.set('add', res_value)
elem.set('separator', ' or ')
has_change = True
elif not inherited_has_record:
elem.set('add', res_value)
elem.set('separator', ' or ')
has_change = True
elif not value and not attr_value:
has_change = True
elif res_value in ('0', 'False', '1', 'True'):
elem.text = res_value
has_change = True
else:
elem.set('add', res_value)
elem.set('separator', ' or ')
has_change = True
_logger.info('The migration of attributes inheritance might not be exact: %s', etree.tostring(elem, encoding="unicode"))
elif not value and not attr_value:
continue
else:
elem.text = res_value
if attr_value:
has_change = True
spec.insert(index, elem)
index += 1
# remove previous node and xml
for node in to_remove:
spec.remove(node)
return has_change
def convert_node_modifiers_inplace(root, env, model, view_type, ref):
"""Convert inplace old syntax (attrs, states...) into new modifiers syntax"""
updated_nodes = set()
analysed_nodes = set()
def expr_to_attr(item, py_field_modifiers=None, field=None):
if item in analysed_nodes:
return
analysed_nodes.add(item)
try:
modifiers = extract_node_modifiers(item, view_type, py_field_modifiers)
except ValueError as error:
if ('country_id != %(base.' in error.args[0] or
'%(base.lu)d not in account_enabled_tax_country_ids' in error.args[0]):
# Odoo xml file can use %(...)s ref/xmlid, this part is
# replaced later by the record id. This code cannot be
# parsed into a domain and convert into a expression.
# Just skip it.
return
xml = etree.tostring(item, encoding='unicode')
_logger.error("Invalid modifiers syntax: %s\nError: %s\n%s", ref, error, xml)
return
# apply new modifiers on item only when modified...
for attr in ('column_invisible', 'invisible', 'readonly', 'required'):
new_py_expr = modifiers.pop(attr, None)
old_expr = item.attrib.get(attr)
if ( old_expr == new_py_expr
or (old_expr in ('1', 'True') and new_py_expr == 'True')
or (old_expr in ('0', 'False') and new_py_expr in ('False', None))):
continue
if new_py_expr and (new_py_expr != 'False'
or (attr == 'readonly' and field and field.readonly)
or (attr == 'required' and field and field.required)):
item.attrib[attr] = new_py_expr
else:
item.attrib.pop(attr, None)
updated_nodes.add(item)
# ... and remove old attributes
if item.attrib.pop('states', None):
updated_nodes.add(item)
if item.attrib.pop('attrs', None):
updated_nodes.add(item)
# they are some modifiers left, some templates are badly storing
# options in attrs, then they must be left as is (e.g.: studio
# widget, name, ...)
if modifiers:
item.attrib['attrs'] = repr(modifiers)
def in_subview(item):
for p in item.iterancestors():
if p == root:
return False
if p.tag in ('field', 'groupby'):
return True
if model is not None:
if view_type == 'tree':
# groupby from tree target the field as a subview (inside groupby is treated as form)
for item in root.findall('.//groupby[@name]'):
f_name = item.get('name')
field = model._fields[f_name]
updated, fnodes = convert_node_modifiers_inplace(item, env, env[field.comodel_name], 'form', ref)
analysed_nodes.update(fnodes)
updated_nodes.update(updated)
for item in root.findall('.//field[@name]'):
if in_subview(item):
continue
if item in analysed_nodes:
continue
# in kanban view, field outside the template should not have modifiers
if view_type == 'kanban' and item.getparent().tag == 'kanban':
for attr in ('states', 'attrs', 'column_invisible', 'invisible', 'readonly', 'required'):
item.attrib.pop(attr, None)
continue
# shortcut for views that do not use information from the python field
if view_type not in ('kanban', 'tree', 'form', 'setting'):
expr_to_attr(item)
continue
f_name = item.get('name')
if f_name not in model._fields:
_logger.warning("Unknown field %r from %r, can not migrate 'states' python field attribute in view %s", f_name, model._name, ref)
continue
field = model._fields[f_name]
# get subviews
if field.comodel_name:
for subview in item.getchildren():
subview_type = subview.tag if subview.tag != 'groupby' else 'form'
updated, fnodes = convert_node_modifiers_inplace(subview, env, env[field.comodel_name], subview_type, ref)
analysed_nodes.update(fnodes)
updated_nodes.update(updated)
# use python field to convert view <field>
if item.get('readonly'):
expr_to_attr(item, field=field)
elif field.states:
readonly = bool(field.readonly)
fnames = [k for k, v in field.states.items() if v[0][1] != readonly]
if fnames:
fnames.sort()
dom = [('state', 'not in' if readonly else 'in', fnames)]
expr_to_attr(item, py_field_modifiers={'readonly': domain_to_expression(dom)}, field=field)
else:
expr_to_attr(item)
elif field.readonly not in (True, False):
try:
readonly_expr = domain_to_expression(str(field.readonly))
except ValueError:
_logger.warning("Can not convert readonly: %r", field.readonly)
continue
if readonly_expr in ('0', '1'):
readonly_expr = str(readonly_expr == '1')
expr_to_attr(item, py_field_modifiers={'readonly': readonly_expr}, field=field)
else:
expr_to_attr(item, field=field)
# processes all elements that have not been converted
for item in unique(itertools.chain(
root.findall('.//*[@attrs]'),
root.findall('.//*[@states]'),
root.findall('.//tree/*[@invisible]'))):
expr_to_attr(item)
return updated_nodes, analysed_nodes
reg_comment = r'<!--(?:-(?!-)|\n|[^-])+-->'
reg_att1 = r'[a-zA-Z0-9._-]+\s*=\s*"(?:\n|[^"])*"'
reg_att2 = r"[a-zA-Z0-9._-]+\s*=\s*'(?:\n|[^'])*'"
reg_open_tag = rf'''<[a-zA-Z0-9]+(?:\s*\n|\s+{reg_att1}|\s+{reg_att2})*\s*/?>'''
reg_close_tag = r'</[a-zA-Z0-9]+\s*>'
reg_split = rf'((?:\n|[^<])*)({reg_comment}|{reg_open_tag}|{reg_close_tag})((?:\n|[^<])*)'
reg_attrs = r''' (attrs|states|invisible|column_invisible|readonly|required)=("(?:\n|[^"])*"|'(?:\n|[^'])*')'''
close_placeholder = '</XXXYXXX>'
def split_xml(arch):
""" split xml in tags, add a close tag for each void. """
split = list(re.findall(reg_split, arch.replace('/>', f'/>{close_placeholder}')))
return split
def get_targeted_xml_content(spec, field_arch_content):
spec_xml = etree.tostring(spec, encoding='unicode').strip()
if spec_xml in field_arch_content:
return spec_xml
for ancestor in spec.iterancestors():
if ancestor.tag in ('field', 'data'):
break
spec_index = ancestor.index(spec)
xml = ''
level = 0
index = 0
for before, tag, after in split_xml(field_arch_content):
if index - 1 == spec_index:
xml += before + tag + after
if tag[1] == '/':
level -= 1
elif tag[1] != '!':
level += 1
if level == 1:
index += 1
if not xml:
ValueError('Source inheritance spec not found for %s: %s', ref, spec_xml)
return xml.replace(close_placeholder, '').strip()
def replace_and_keep_indent(element, arch, ref):
""" Generate micro-diff from updated attributes """
next_record = etree.tostring(element, encoding='unicode').replace(""", "'").strip()
n_split = split_xml(next_record)
arch = arch.strip()
p_split = split_xml(arch)
control = ''
level = 0
for i in range(max(len(p_split), len(n_split))):
p_node = p_split[i][1]
n_node = n_split[i][1]
control += ''.join(p_split[i])
if p_node[1] != '/' and p_node[1] != '!':
level += 1
replace_by = p_node
if p_node != n_node:
if p_node == close_placeholder and not n_node.startswith('</'):
raise ValueError("Wrong split for convertion in %s\n\n---------\nSource node: None\nCurrent node: %s\nSource arch: %s\nCurrent arch: %s" % (
ref, n_node, arch, next_record))
if n_node == close_placeholder and not p_node.startswith('</'):
raise ValueError("Wrong split for convertion in %s\n\n---------\nSource node: %s\nCurrent node: None\nSource arch: %s\nCurrent arch: %s" % (
ref, p_node, arch, next_record))
p_tag = re.split(r'[<>\n /]+', p_node, 2)[1]
n_tag = re.split(r'[<>\n /]+', n_node, 2)[1]
if p_node != close_placeholder and n_node != close_placeholder and p_tag != n_tag:
raise ValueError("Wrong split for convertion in %s\n\n---------\nSource node: %s\nCurrent node: %s\nSource arch: %s\nCurrent arch: %s" % (
ref, p_node, n_node, arch, next_record))
p_attrs = {k: v[1:-1] for k, v in re.findall(reg_attrs, p_node)}
n_attrs = {k: v[1:-1] for k, v in re.findall(reg_attrs, n_node)}
if p_attrs != n_attrs:
if p_attrs:
key, value = p_attrs.popitem()
for j in p_attrs:
replace_by = replace_by.replace(f' {j}="{p_attrs[j]}"', '')
rep = ''
if n_attrs:
space = re.search(rf'(\n? +){key}=', replace_by).group(1)
rep = ' ' + space.join(f'{k}="{v}"' for k, v in n_attrs.items())
replace_by = re.sub(r""" %s=["']%s["']""" % (re.escape(key), re.escape(value)), rep, replace_by)
replace_by = re.sub('(?: *\n +)+(\n +)', r'\1', replace_by)
replace_by = re.sub('(?: *\n +)(/?>)', r'\1', replace_by)
else:
rep = ''
if n_attrs:
rep = ' ' + ' '.join(f'{k}="{v}"' for k, v in n_attrs.items())
if p_node.endswith('/>'):
replace_by = replace_by[0:-2] + rep + '/>'
else:
replace_by = replace_by[0:-1] + rep + '>'
if p_node[1] == '/':
level -= 1
p_split[i] = (p_split[i][0], replace_by, p_split[i][2])
xml = ''.join(''.join(s) for s in p_split).replace(f'/>{close_placeholder}', '/>')
control = control.replace(f'/>{close_placeholder}', '/>')
if not control or level != 0:
_logger.error("Wrong convertion in %s\n\n%s", ref, control)
raise ValueError('Missing update: \n{control}')
return xml
def extract_node_modifiers(node, view_type, py_field_modifiers=None):
"""extract the node modifiers and concat attributes (attrs, states...)"""
modifiers = {}
# modifiers from deprecated attrs
# <field attrs="{'invisible': "[['user_id', '=', uid]]", 'readonly': [('name', '=', 'toto')]}" .../>
# =>
# modfiers['invisible'] = 'user_id == uid'
# modfiers['readonly'] = 'name == "toto"'
attrs = ast.literal_eval(node.attrib.get("attrs", "{}")) or {}
for modifier, val in attrs.items():
try:
domain = modifier_to_domain(val)
py_expression = domain_to_expression(domain)
except Exception as error:
raise ValueError(f"Invalid modifier {modifier!r}: {val!r}\n{error}") from error
modifiers[modifier] = py_expression
# invisible modifier from deprecated states
# <field states="draft,done" .../>
# =>
# modifiers['invisible'] = "state not in ('draft', 'done')"
states = node.attrib.get('states')
if states:
value = tuple(states.split(","))
if len(value) == 1:
py_expression = f'state != {value[0]!r}'
else:
py_expression = f'state not in {value!r}'
invisible = modifiers.get('invisible') or 'False'
if invisible == 'False':
modifiers['invisible'] = py_expression
else:
# only add parenthesis if necessary
if ' and ' in py_expression or ' or ' in py_expression:
py_expression = f'({py_expression})'
if ' and ' in invisible or ' or ' in invisible:
invisible = f'({invisible})'
modifiers['invisible'] = f'{invisible} and {py_expression}'
# extract remaining modifiers
# <field invisible="context.get('hide')" .../>
for modifier in ('column_invisible', 'invisible', 'readonly', 'required'):
py_expression = node.attrib.get(modifier, '').strip()
if not py_expression:
if modifier not in modifiers and py_field_modifiers and py_field_modifiers.get(modifier):
modifiers[modifier] = py_field_modifiers[modifier]
continue
try:
# most (~95%) elements are 1/True/0/False
py_expression = repr(str2bool(py_expression))
except ValueError:
# otherwise, make sure it is a valid expression
try:
modifier_ast = ast.parse(f'({py_expression})', mode='eval').body
py_expression = repr(_modifier_to_domain_ast_leaf(modifier_ast))
except Exception as error:
raise ValueError(f'Invalid modifier {modifier!r}: {error}: {py_expression!r}') from None
# Special case, must rename "invisible" to "column_invisible"
if modifier == 'invisible' and py_expression != 'False' and not get_expression_field_names(py_expression):
parent_view_type = view_type
for parent in node.iterancestors():
if parent.tag in ('tree', 'form', 'setting', 'kanban', 'calendar', 'search'):
parent_view_type = parent.tag
break
if parent.tag in ('groupby', 'header'): # tree view element with form view behavior
parent_view_type = 'form'
break
if parent_view_type == 'tree':
modifier = 'column_invisible'
# previous_py_expr and py_expression must be OR-ed
# first 3 cases are short circuits
previous_py_expr = modifiers.get(modifier, 'False')
if (previous_py_expr == 'True' # True or ... => True
or py_expression == 'True'): # ... or True => True
modifiers[modifier] = 'True'
elif previous_py_expr == 'False': # False or ... => ...
modifiers[modifier] = py_expression
elif py_expression == 'False': # ... or False => ...
modifiers[modifier] = previous_py_expr
else:
# only add parenthesis if necessary
if ' and ' in previous_py_expr or ' or ' in previous_py_expr:
previous_py_expr = f'({previous_py_expr})'
modifiers[modifier] = f'{py_expression} or {previous_py_expr}'
return modifiers
def domain_to_expression(domain):
"""Convert the given domain into a python expression"""
domain = normalize_domain(domain)
domain = distribute_not(domain)
operators = []
expression = []
for leaf in reversed(domain):
if leaf == AND_OPERATOR:
right = expression.pop()
if operators.pop() == OR_OPERATOR:
right = f'({right})'
left = expression.pop()
if operators.pop() == OR_OPERATOR:
left = f'({left})'
expression.append(f'{right} and {left}')
operators.append(leaf)
elif leaf == OR_OPERATOR:
right = expression.pop()
operators.pop()
left = expression.pop()
operators.pop()
expression.append(f'{right} or {left}')
operators.append(leaf)
elif leaf == NOT_OPERATOR:
expr = expression.pop()
operators.pop()
expression.append(f'not ({expr})')
operators.append(leaf)
elif leaf is True or leaf is False:
expression.append(repr(leaf))
operators.append(None)
elif isinstance(leaf, (tuple, list)):
left, op, right = leaf
if left == 1: # from TRUE_LEAF
expr = 'True'
elif left == 0: # from FALSE_LEAF
expr = 'False'
elif isinstance(left, ContextDependentDomainItem):
# from expression to use TRUE_LEAF or FALSE_LEAF
expr = repr(left)
elif op == '=' or op == '==':
if right is False or right == []:
expr = f'not {left}'
elif left.endswith('_ids'):
expr = f'{right!r} in {left}'
elif right is True:
expr = f'{left}'
elif right is False:
expr = f'not {left}'
else:
expr = f'{left} == {right!r}'
elif op == '!=' or op == '<>':
if right is False or right == []:
expr = str(left)
elif left.endswith('_ids'):
expr = f'{right!r} not in {left}'
elif right is True:
expr = f'not {left}'
elif right is False:
expr = f'{left}'
else:
expr = f'{left} != {right!r}'
elif op in ('<=', '<', '>', '>='):
expr = f'{left} {op} {right!r}'
elif op == '=?':
expr = f'(not {right} or {left} in {right!r})'
elif op == 'in' or op == 'not in':
right_str = str(right)
if right_str == '[None, False]':
expr = f'not ({left})'
elif left.endswith('_ids'):
if right_str.startswith('[') and ',' not in right_str:
expr = f'{right[0]!r} {op} {left}'
if not right_str.startswith('[') and right_str.endswith('id'):
# fix wrong use of 'in' inside domain
expr = f'{right_str!r} {op} {left}'
else:
raise ValueError(f"Can not convert {domain!r} to python expression")
else:
if right_str.startswith('[') and ',' not in right_str:
op = '==' if op == 'in' else '!='
expr = f'{left} {op} {right[0]!r}'
else:
expr = f'{left} {op} {right!r}'
elif op == 'like' or op == 'not like':
if isinstance(right, str):
part = right.split('%')
if len(part) == 1:
op = 'in' if op == 'like' else 'not in'
expr = f'{right!r} {op} ({left} or "")'
elif len(part) == 2:
if part[0] and part[1]:
expr = f'({left} or "").startswith({part[0]!r}) and ({left} or "").endswith({part[1]!r})'
elif part[0]:
expr = f'({left} or "").startswith({part[0]!r})'
elif part[1]:
expr = f'({left} or "").endswith({part[0]!r})'
else:
expr = str(left)
if op.startswith('not '):
expr = f'not ({expr})'
else:
raise ValueError(f"Can not convert {domain!r} to python expression")
else:
op = 'in' if op == 'like' else 'not in'
expr = f'{right!r} {op} ({left} or "")'
elif op == 'ilike' or op == 'not ilike':
if isinstance(right, str):
part = right.split('%')
if len(part) == 1:
op = 'in' if op == 'ilike' else 'not in'
expr = f'{right!r}.lower() {op} ({left} or "").lower()'
elif len(part) == 2:
if part[0] and part[1]:
expr = f'({left} or "").lower().startswith({part[0]!r}) and ({left} or "").lower().endswith({part[1]!r})'
elif part[0]:
expr = f'({left} or "").lower().startswith({part[0]!r})'
elif part[1]:
expr = f'({left} or "").lower().endswith({part[0]!r})'
else:
expr = str(left)
if op.startswith('not '):
expr = f'not ({expr})'
else:
raise ValueError(f"Can not convert {domain!r} to python expression")
else:
op = 'in' if op == 'like' else 'not in'
expr = f'{right!r}.lower() {op} ({left} or "").lower()'
else:
raise ValueError(f"Can not convert {domain!r} to python expression")
expression.append(expr)
operators.append(None)
else:
expression.append(repr(leaf))
operators.append(None)
return expression.pop()
class ContextDependentDomainItem():
def __init__(self, value, names, returns_boolean=False, returns_domain=False):
self.value = value
self.contextual_values = names
self.returns_boolean = returns_boolean
self.returns_domain = returns_domain
def __str__(self):
if self.returns_domain:
return repr(self.value)
return self.value
def __repr__(self):
return self.__str__()
def _modifier_to_domain_ast_wrap_domain(modifier_ast):
try:
domain_item = _modifier_to_domain_ast_leaf(modifier_ast, should_contain_domain=True)
except Exception as e:
raise ValueError(f'{e}\nExpression must returning a valid domain in all cases') from None
if not isinstance(domain_item, ContextDependentDomainItem) or not domain_item.returns_domain:
raise ValueError('Expression must returning a valid domain in all cases')
return domain_item.value
def _modifier_to_domain_ast_domain(modifier_ast):
# ['|', ('a', '=', 'b'), ('user_id', '=', uid)]
if not isinstance(modifier_ast, ast.List):
raise ValueError('This part must be a domain') from None
domain = []
for leaf in modifier_ast.elts:
if isinstance(leaf, ast.Str) and leaf.s in DOMAIN_OPERATORS:
# !, |, &
domain.append(leaf.s)
elif isinstance(leaf, ast.Constant):
if leaf.value is True or leaf.value is False:
domain.append(leaf.value)
else:
raise InvalidDomainError()
elif isinstance(leaf, (ast.List, ast.Tuple)):
# domain tuple
if len(leaf.elts) != 3:
raise InvalidDomainError()
elif not isinstance(leaf.elts[0], ast.Constant) and not (isinstance(leaf.elts[2], ast.Constant) and leaf.elts[2].value == 1):
raise InvalidDomainError()
elif not isinstance(leaf.elts[1], ast.Constant):
raise InvalidDomainError()
left_ast, operator_ast, right_ast = leaf.elts
operator = operator_ast.value
if operator == '==':
operator = '='
elif operator == '<>':
operator = '!='
elif operator not in TERM_OPERATORS:
raise InvalidDomainError()
left = _modifier_to_domain_ast_leaf(left_ast)
right = _modifier_to_domain_ast_leaf(right_ast)
domain.append((left, operator, right))
else:
item = _modifier_to_domain_ast_leaf(leaf)
domain.append(item)
if item not in (True, False) and isinstance(item, ContextDependentDomainItem) and not item.returns_boolean:
raise InvalidDomainError()
return normalize_domain(domain)
def _modifier_to_domain_ast_leaf(item_ast, should_contain_domain=False, need_parenthesis=False):
# [('a', '=', True)]
# True
if isinstance(item_ast, ast.Constant):
return item_ast.value
# [('a', '=', 'b')]
# 'b'
if isinstance(item_ast, ast.Str):
return item_ast.s
# [('a', '=', 1)] if context.get('b') else []
# [('a', '=', 1)]
if should_contain_domain and isinstance(item_ast, ast.List):
domain = _modifier_to_domain_ast_domain(item_ast)
_fnames, vnames = get_domain_value_names(domain)
return ContextDependentDomainItem(domain, vnames, returns_domain=True)
# [('obj_ids', 'in', [uid or False, 33])]
# [uid or False, 33]
if isinstance(item_ast, (ast.List, ast.Tuple)):
vnames = set()
values = []
for item in item_ast.elts:
value = _modifier_to_domain_ast_leaf(item)
if isinstance(value, ContextDependentDomainItem):
vnames.update(value.contextual_values)
values.append(value)
if isinstance(item_ast, ast.Tuple):
values = tuple(values)
if vnames:
return ContextDependentDomainItem(repr(values), vnames)
else:
return values
# [('a', '=', uid)]
# uid
if isinstance(item_ast, ast.Name):
vnames = {item_ast.id}
return ContextDependentDomainItem(item_ast.id, vnames)
# [('a', '=', parent.b)]
# parent.b
if isinstance(item_ast, ast.Attribute):
vnames = set()
name = _modifier_to_domain_ast_leaf(item_ast.value, need_parenthesis=True)
if isinstance(name, ContextDependentDomainItem):
vnames.update(name.contextual_values)
value = f"{name!r}.{item_ast.attr}"
if value.startswith('parent.'):
vnames.add(value)
return ContextDependentDomainItem(value, vnames)
# [('a', '=', company_ids[1])]
# [1]
if isinstance(item_ast, ast.Index): # deprecated python ast class for Subscript key
return _modifier_to_domain_ast_leaf(item_ast.value)
# [('a', '=', company_ids[1])]
# [1]
if isinstance(item_ast, ast.Subscript):
vnames = set()
name = _modifier_to_domain_ast_leaf(item_ast.value, need_parenthesis=True)
if isinstance(name, ContextDependentDomainItem):
vnames.update(name.contextual_values)
key = _modifier_to_domain_ast_leaf(item_ast.slice)
if isinstance(key, ContextDependentDomainItem):
vnames.update(key.contextual_values)
value = f"{name!r}[{key!r}]"
return ContextDependentDomainItem(value, vnames)
# [('a', '=', context.get('abc', 'default') == 'b')]
# ==
if isinstance(item_ast, ast.Compare):
vnames = set()
if len(item_ast.ops) > 1:
raise ValueError(f"Should not more than one comparaison: {expr}")
left = _modifier_to_domain_ast_leaf(item_ast.left, need_parenthesis=True)
if isinstance(left, ContextDependentDomainItem):
vnames.update(left.contextual_values)
operator = AST_OP_TO_STR[type(item_ast.ops[0])]
right = _modifier_to_domain_ast_leaf(item_ast.comparators[0], need_parenthesis=True)
if isinstance(right, ContextDependentDomainItem):
vnames.update(right.contextual_values)
expr = f"{left!r} {operator} {right!r}"
return ContextDependentDomainItem(expr, vnames, returns_boolean=True)
# [('a', '=', 1 - 3]
# 1 - 3
if isinstance(item_ast, ast.BinOp):
vnames = set()
left = _modifier_to_domain_ast_leaf(item_ast.left)
if isinstance(left, ContextDependentDomainItem):
vnames.update(left.contextual_values)
operator = AST_OP_TO_STR[type(item_ast)]
right = _modifier_to_domain_ast_leaf(item_ast.right)
if isinstance(right, ContextDependentDomainItem):
vnames.update(right.contextual_values)
expr = f"{left!r} {operator} {right!r}"
return ContextDependentDomainItem(expr, vnames)
# [(1, '=', field_name and 1 or 0]
# field_name and 1
if isinstance(item_ast, ast.BoolOp):
vnames = set()
returns_boolean = True
returns_domain = False
values = []
for ast_value in item_ast.values:
value = _modifier_to_domain_ast_leaf(ast_value, should_contain_domain, need_parenthesis=True)
if isinstance(value, ContextDependentDomainItem):
vnames.update(value.contextual_values)
if not value.returns_boolean:
returns_boolean = False
if value.returns_domain:
returns_domain = True
elif not isinstance(value, bool):
returns_boolean = False
values.append(repr(value))
if returns_domain:
raise ValueError("Use if/else condition instead of boolean operator to return domain.")
if isinstance(item_ast.op, ast.Or):
expr = ' or '.join(values)
else:
expr = ' and '.join(values)
if need_parenthesis and ' ' in expr:
expr = f'({expr})'
return ContextDependentDomainItem(expr, vnames, returns_boolean=returns_boolean)
# [('a', '=', not context.get('abc', 'default')), ('a', '=', -1)]
# not context.get('abc', 'default')
if isinstance(item_ast, ast.UnaryOp):
if isinstance(item_ast.operand, ast.Constant) and isinstance(item_ast.op, ast.USub) and isinstance(item_ast.operand.value, (int, float)):
return -item_ast.operand.value
leaf = _modifier_to_domain_ast_leaf(item_ast.operand, need_parenthesis=True)
vnames = set()
if isinstance(leaf, ContextDependentDomainItem):
vnames.update(leaf.contextual_values)
expr = f"not {leaf!r}"
return ContextDependentDomainItem(expr, vnames, returns_boolean=True)
# [('a', '=', int(context.get('abc', False))]
# context.get('abc', False)
if isinstance(item_ast, ast.Call):
vnames = set()
name = _modifier_to_domain_ast_leaf(item_ast.func, need_parenthesis=True)
if isinstance(name, ContextDependentDomainItem) and name.value not in _BUILTINS:
vnames.update(name.contextual_values)
returns_boolean = str(name) == 'bool'
values = []
for arg in item_ast.args:
value = _modifier_to_domain_ast_leaf(arg)
if isinstance(value, ContextDependentDomainItem):
vnames.update(value.contextual_values)
values.append(repr(value))
expr = f"{name!r}({', '.join(values)})"
return ContextDependentDomainItem(expr, vnames, returns_boolean=returns_boolean)
# [('a', '=', 1 if context.get('abc', 'default') == 'b' else 0)]
# 1 if context.get('abc', 'default') == 'b' else 0
if isinstance(item_ast, ast.IfExp):
vnames = set()
test = _modifier_to_domain_ast_leaf(item_ast.test)
if isinstance(test, ContextDependentDomainItem):
vnames.update(test.contextual_values)
returns_boolean = True
returns_domain = True
body = _modifier_to_domain_ast_leaf(item_ast.body, should_contain_domain, need_parenthesis=True)
if isinstance(body, ContextDependentDomainItem):
vnames.update(body.contextual_values)
if not body.returns_boolean:
returns_boolean = False
if not body.returns_domain:
returns_domain = False
else:
returns_domain = False
if not isinstance(body, bool):
returns_boolean = False
orelse = _modifier_to_domain_ast_leaf(item_ast.orelse, should_contain_domain, need_parenthesis=True)
if isinstance(orelse, ContextDependentDomainItem):
vnames.update(orelse.contextual_values)
if not orelse.returns_boolean:
returns_boolean = False
if not orelse.returns_domain:
returns_domain = False
else:
returns_domain = False
if not isinstance(orelse, bool):
returns_boolean = False
if returns_domain:
# [('id', '=', 42)] if parent.a else []
not_test = ContextDependentDomainItem(f"not ({test})", vnames, returns_boolean=True)
if not isinstance(test, ContextDependentDomainItem) or not test.returns_boolean:
test = ContextDependentDomainItem(f"bool({test})", vnames, returns_boolean=True)
# ['|', '&', bool(parent.a), ('id', '=', 42), not parent.a]
expr = ['|', '&', test] + body.value + ['&', not_test] + orelse.value
else:
expr = f"{body!r} if {test} else {orelse!r}"
return ContextDependentDomainItem(expr, vnames, returns_boolean=returns_boolean, returns_domain=returns_domain)
if isinstance(item_ast, ast.Expr):
return _modifier_to_domain_ast_leaf(item_ast.value)
raise ValueError(f"Undefined item {item_ast!r}.")
def _modifier_to_domain_validation(domain):
for leaf in domain:
if leaf is True or leaf is False or leaf in DOMAIN_OPERATORS:
continue
try:
left, operator, _right = leaf
except ValueError:
raise InvalidDomainError()
except TypeError:
if isinstance(leaf, ContextDependentDomainItem):
if leaf.returns_boolean:
continue
raise InvalidDomainError()
raise InvalidDomainError()
if leaf not in (TRUE_LEAF, FALSE_LEAF) and not isinstance(left, str):
raise InvalidDomainError()
if operator not in VALID_TERM_OPERATORS:
raise InvalidDomainError()
def modifier_to_domain(modifier):
"""
Convert modifier values to domain. Generated domains can contain
contextual elements (right part of domain leaves). The domain can be
concatenated with others using the `AND` and `OR` methods.
The representation of the domain can be evaluated with the corresponding
context.
:params modifier (bool|0|1|domain|str|ast)
:return a normalized domain (list(tuple|"&"|"|"|"!"|True|False))
"""
from odoo.osv import expression
if isinstance(modifier, bool):
return [TRUE_LEAF if modifier else FALSE_LEAF]
if isinstance(modifier, int):
return [TRUE_LEAF if modifier else FALSE_LEAF]
if isinstance(modifier, (list, tuple)):
_modifier_to_domain_validation(modifier)
return normalize_domain(modifier)
if isinstance(modifier, ast.AST):
try:
return _modifier_to_domain_ast_domain(modifier)
except Exception as e:
raise ValueError(f'{e}: {modifier!r}') from None
# modifier is a string
modifier = modifier.strip()
# most (~95%) elements are 1/True/0/False
if modifier.lower() in ('0', 'false'):
return [FALSE_LEAF]
if modifier.lower() in ('1', 'true'):
return [TRUE_LEAF]
# [('a', '=', 'b')]
try:
domain = ast.literal_eval(modifier)
_modifier_to_domain_validation(domain)
return normalize_domain(domain)
except SyntaxError:
raise ValueError(f'Wrong domain python syntax: {modifier}')
except ValueError:
pass
# [('a', '=', parent.b), ('a', '=', context.get('b'))]
try:
modifier_ast = ast.parse(f'({modifier})', mode='eval').body
if isinstance(modifier_ast, ast.List):
return _modifier_to_domain_ast_domain(modifier_ast)
else:
return _modifier_to_domain_ast_wrap_domain(modifier_ast)
except Exception as e:
raise ValueError(f'{e}: {modifier}')
def str2bool(s):
s = s.lower()
if s in ("1", "true"):
return True
if s in ("0", "false"):
return False
raise ValueError()
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。